Edward E. Miller w artykule z 1977 r. "Risk, Uncertainty, and Divergence of Opinion" zaproponował interesujący model wyjaśniający różnego rodzaju "dziwne" zachowania stóp zwrotu przeczące teorii efektywności rynku oraz CAPM związany z rozbieżnością opinii inwestorów.
Rozważmy uproszczony model, w którym spółka akcyjna organizuje projekt na jeden rok. Po roku spółka zostanie zlikwidowana, a jej aktywa zostaną podzielone pomiędzy inwestorów. Inwestorzy maksymalizują oczekiwaną stopę zwrotu przy danym ryzyku, estymują stopę zwrotu z inwestycji, ale z powodu niepewności różnią tymi estymacjami.
Poniższy wykres pokazuje skumulowany rozkład liczby inwestorów z estymacjami powyżej pewnej wartości otrzymanej przy likwidacji inwestycji. Może być on także interpretowany jako liczba akcji, którą chcą trzymać inwestorzy po danej cenie.
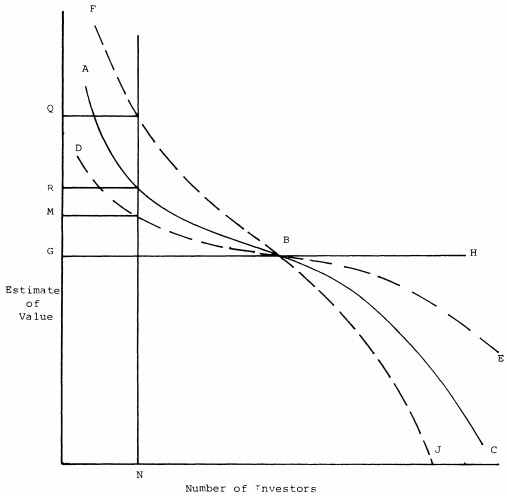
Załóżmy, że każdy inwestor jest w stanie trzymać tylko jedną akcję i jest N dostępnych akcji. Na krzywej ABC widać, że N inwestorów szacuje końcową wartość R lub wyższą. W sumie cena sprzedaży ustala się na poziomie R. Jeśli cena wyniesie mniej niż R, będzie więcej niż N inwestorów którzy chcą trzymać akcje, ale ponieważ akcji w obrocie jest tylko N, zaczną pomiędzy sobą rywalizować, podbijając maksymalnie cenę do R. Jeśli cena będzie powyżej R, wtedy będzie mniej niż N inwestorów, którzy chcą trzymać akcje, a ponieważ liczba akcji N jest większa, podaż będzie zmuszona do sprzedawania akcji, sprowadzając cenę do R.
Aby lepiej zrozumieć model, przypomnijmy sobie poprzedni artykuł, gdzie podałem wzór na oczekiwaną przyszłą cenę akcji. Mieliśmy cenę P(0) w momencie 0 i E(P(1)) w okresie 1. Jeśli więc zaczynamy od okresu 0, to oczywiście inwestorzy kupują akcje po P(0), w tym przypadku po jednej akcji. P(0) może się znajdować w dowolnym punkcie krzywej ABC. Ale każdy inwestor może szacować inny poziom E(P(1)). Jeśli P(0) znajduje się poniżej R, to będzie więcej niż N inwestorów (czyli więcej niż akcji w obrocie), którzy chcą teraz trzymać akcje, ponieważ uważają, że w okresie 1 cena wyniesie co najmniej R lub - co na jedno wychodzi - dostaną przy likwidacji wartość kapitału własnego na jedną akcję równą R lub wyższą, co że pozwoli im maksymalizować stopę zwrotu. Jeśli bieżąca cena P(0) okaże się równa bądź wyższa od R, to inwestycja przestanie być opłacalna dla części z tych inwestorów. Ta część "odpadnie", w tym sensie, że ci, którzy kupili akcje po niższej cenie, będą sprzedawać, a ci którzy nie kupili, nie będą chcieli już kupić. W ten sposób pozostanie mniejsza liczba inwestorów, która nadal uważa, że przy danej cenie inwestycja maksymalizuje ich stopę zwrotu. W tej mniejszej grupie ci, którzy już kupili akcje wcześniej, nadal trzymają, a ci którzy nie kupili, będą starać się ciągle kupić. Ta grupa nadal bowiem uważa, że w okresie 1 cena będzie zadowalająco wyższa. Ale wraz ze wzrostem bieżącej ceny P(0) liczba tych inwestorów będzie sukcesywnie spadać. Stąd przesuwając się z prawej do lewej liczba inwestorów spada, a cena rośnie.
Jeśli pominiemy inne spółki w analizie, możemy stwierdzić, że inwestorzy będą kupować akcje dopóki szacowana stopa zwrotu przewyższy stopę zwrotu z obligacji rządowych po uwzględnieniu ryzyka. Ponieważ każdy może inaczej oceniać ryzyko i oczekiwaną stopę zwrotu, to każdy może mieć inny poziom akceptowalnej ceny zakupu i sprzedaży. A więc na osi pionowej znajdują się jednocześnie ceny zakupu P(0) i ceny oczekiwane E(P(1)) różnych inwestorów. Oczywiście jeśli wartość E(P(1)) szacowana przez pewną grupę inwestorów zostanie osiągnięta przed okresem likwidacji, to będzie mogła już realizować zysk.
Na krzywą ABC można spojrzeć jak na krzywą popytu, gdzie dana liczba inwestorów odpowiada popytowi przy danej cenie. Krzywa podaży jest to linia pionowa N wyrażająca liczbę dostępnych akcji.
Oczywiście łatwo zauważyć, że w takim układzie przyszła cena R będzie musiała zostać bardzo szybko osiągnięta, ponieważ cena jest wynikiem sił popytu i podaży. Dzieje się tak dlatego, że pewna stosunkowo niewielka (jak widać na wykresie) grupa inwestorów, ale będąca jeszcze w stanie zaspokoić całkowitą podaż, ciągle uważa, że przy P(0) = R, inwestycja jest nadal opłacalna.
Ta niewielka grupa inwestorów dopóki będzie w stanie wchłonąć podaż, spowoduje, że cena rynkowa będzie wyższa niż średnia oczekiwana cena przez ogół inwestorów. (Przy czym oczekiwana cena R będzie nadal średnią ważoną udziałem akcji, a tym samym estymacji wielu inwestorów tak jak przedstawiono to w poprzednim artykule). Zatem najwięksi optymiści albo słabo lub lepiej poinformowani będą w stanie spowodować istotne zwyżki kursu.
Dopiero nowe informacje płynące z otoczenia rynkowego czy samej spółki wpłyną na zmiany jej wyceny. I wszystko zacznie się od nowa, aż do momentu likwidacji spółki.
Rozbieżność opinii może się zmieniać w czasie pod wpływem nowych informacji. Co więcej, jak Miller stwierdza, rozbieżność opinii na temat stopy zwrotu i ryzyko zmieniają się w tym samym kierunku. Znaczenie ma tutaj założenie, że rzeczywiste inwestycje charakteryzują się niepewnością, to znaczy rozkład prawdopodobieństwa zdarzeń jest nieznany. Skutkuje to tym, że decyzje opierają się na subiektywnych szacunkach przyszłych zdarzeń, na subiektywnych prawdopodobieństwach. W grach hazardowych jak kasyno można ściśle wyznaczyć ryzyko i rozkład prawdopodobieństwa, a więc nie istnieje niepewność, a tym samym nie istnieje rozbieżność opinii. Sytuacja na rynkach jest dużo bardziej skomplikowana i może generować subiektywność oszacowań, co implikuje niepewność, a więc i rozbieżność opinii. Stąd w ogólnym rozrachunku możemy utożsamiać ryzyko inwestycji z niepewnością.
Załóżmy więc, że przychodzi informacja, że spółka za część wyemitowanego kapitału podejmuje pewną dodatkową inwestycję mającą na celu obniżenie kosztów. Jednak inwestycja ta jest dość ryzykowna. A więc całkowite ryzyko inwestycji wzrasta, ale jednocześnie wywołuje to wzrost rozbieżności opinii. Krzywa ABC zostaje zastąpiona przez FBJ. Jak widać prowadzi to do wzrostu ceny rynkowej z R do Q. Załóżmy następnie, że ta dodatkowa inwestycja udaje się, tak że koszty zostaną rzeczywiście obniżone. To doprowadzi do tego, że część wypłaty pieniędzy w okresie likwidacji staje się bardziej pewna. Ryzyko więc spada, a to prowadzi do spadku rozbieżności opinii. Krzywa FBJ zostaje zastąpiona przez DBE. To jednak prowadzi do spadku wyceny rynkowej, z Q do M. W sytuacji gdy rozbieżność opinii nie występuje - ryzyko jest obiektywne - krzywa popytu staje się linią prostą GBH, a cena spada do G.
Model ten tłumaczy zaobserwowany przez naukowców (np. przez Haugena i Hinesa, a także przez Soldofsky'ego, Millera oraz Pratta) paradoks, że często średnia stopa zwrotu jest ujemnie skorelowana z odchyleniem standardowym. Bardziej ryzykowne walory (to znaczy o wyższym współczynniku beta) przynosiły średnio mniejszy zwrot niż mniej ryzykowne. Jest to oczywiście zjawisko niezgodne z CAPM. Model Millera pokazuje, że staje się to możliwe, gdyż bardziej ryzykowny walor podnosi rozbieżność opinii, a dopóki mniej liczna grupa inwestorów, która optymistycznie ocenia nową inwestycję, w pełni pokryje podaż, wycena rynkowa będzie mogła być odpowiednio wyższa.
No dobrze, ale czy wyższa oczekiwana stopa zwrotu nie podnosi właśnie ceny? Wyższa oczekiwana stopa zwrotu podnosi oczekiwaną cenę E(P(1)) lub obniża P(0). W modelu, który omawiamy występuje zarówno P(0) jak i E(P(1)), jednak wartość E(P(1)) jako wartość oczekiwana pojawia się już w okresie 0. Badanie stóp zwrotu natomiast analizuje dane ex-post, czyli po fakcie - wartość, która się pojawiła się w okresie 0 zaliczona zostaje jako P(0), a wartość w okresie 1 jako P(1). Wartość P(1) jest wartością ex-post dla E(P(1)) - czyli jest to faktyczna wartość, która się pojawiła w okresie 1. Mówiąc krótko - wartość oczekiwana pojawia się szybciej i dlatego staje się wartością bieżącą. A ponieważ wartość bieżąca rośnie, to średnia stopa zwrotu (albo inaczej oczekiwana ex-post stopa zwrotu) spada. Dlatego też - według Millera - badania wykazały ujemną korelację pomiędzy ryzykiem a średnią stopą zwrotu.
Możemy w końcu przejść do sprawy tworzenia się trendu. Jeśli informacje sygnalizujące zwiększenie niepewności będą się często powtarzać, to rozbieżność opinii będzie wzrastać i cena dzięki temu systematycznie wzrasta. Bardziej optymistycznie nastawieni inwestorzy lub też lepiej poinformowani będą traktować informacje jako pozytywną i dopóki wchłoną całą podaż będą "rządzić". Z drugiej strony, jeśli powtarzać się będą informacje sygnalizujące zmniejszenie niepewności, to rozbieżność opinii zacznie spadać i paradoksalnie cena też zacznie spadać. Bardziej optymistyczni i lepiej poinformowani inwestorzy nie będą się zbytnio różnić w ocenach od średniej populacji inwestorów; cena zbliży się do średniej.
Możemy sobie również wyobrazić sytuację, gdy krzywa popytu staje się asymetryczna, tak że górna część staje się silniej nachylona. Mógłby to być typowy przykład z zakresu asymetrii informacji. Pewna niewielka grupa inwestorów wie znacznie więcej od reszty i zaczyna stopniowo, bez hałasu podbijać cenę. Gdy informacja publicznie się ujawnia, cena zwiększa już swoją średnią oczekiwań. Kolejne informacje i kolejne sprzężenia z rozbieżnymi opiniami mogą doprowadzić do utworzenia się trendu.
Oczywiście wszystko zależy od położenia linii podaży N. Jeśli będzie ona przesunięta mocno w prawo w stosunku do krzywej popytu, to popatrzmy co się dzieje - cała analiza się odwraca. Duża liczba inwestorów będzie gorzej od średniej oceniać wartość akcji i każda dodatkowa informacja sygnalizująca wzrost niepewności obniży cenę. Odwrotnie stanie w przypadku informacji zmniejszającej ryzyko. Miller skłania się jednak ku tezie, że liczba inwestorów trzymających wszystkie akcje jest mała w stosunku do całego uniwersum inwestorów, a więc że spełnione są założenia, że to optymiści wyznaczają cenę rynkową. Jednak możemy sobie wyobrazić sytuację, że akcje są tak źle odbierane przez dużą część rynku, że krzywa popytu jest niemal pionowa, a oprócz tego może przecież mieć inny kształt, na przykład im niższa cena, tym mniejsze nachylenie, a nie większe.
Zwróćmy uwagę na fakt, że choć model jest bardzo prosty, bo np. zakłada, że każdy inwestor trzyma jedną akcję, to oczywiście sytuację tę można odpowiednio uogólnić. Każdy inwestor mógłby trzymać n akcji. Wtedy jeśli oś pozioma wyznacza skumulowaną liczbę inwestorów przy danej estymacji, a liczba wszystkich akcji równa się N, to w miejsce N na naszym wykresie wstawiamy N/n. Ponieważ N = M*n, gdzie M - maksymalna liczba inwestorów mogących trzymać wszystkie akcje na rynku, to M = N/n jest liczbą którą musimy wstawić za N.
Na koniec poruszę jeszcze krytykę modelu Millera zapoczątkowaną prawdopodobnie przez Jarrowa (1980). Jarrow zwraca uwagę, że model Millera zakłada heterogeniczność oszacowań oczekiwanej stopy zwrotu oraz homogeniczność oszacowań ryzyka pośród inwestorów. Jeśli inwestorzy oceniają ryzyko na tym samym poziomie, to model Millera może być prawidłowy, a więc rzeczywiście cena będzie rosła wraz ze wzrostem rozbieżności opinii. Jednak rezultat może się zmienić, jeśli ryzyko będzie także niejednorodnie szacowane. Przypomnijmy sobie model Lintnera z poprzedniego artykułu, który opisuje różne sytuacje rozbieżności opinii: zarówno dla oczekiwanej stopy zwrotu, jak i ryzyka. Wprawdzie Lintner nie rozważa w swoim modelu relacji pomiędzy rozbieżnością opinii a ryzykiem/niepewnością, która stanowi klucz do teorii Millera, jednak należy brać pod uwagę wszelkie możliwe przypadki rozbieżnych opinii. Optymiści przewidują wyższe zyski firmy (wyższe dywidendy) bez wzrostu ryzyka. Pesymiści przewidują gorsze wyniki (dywidendy) bez spadku ryzyka. Popatrzmy na wzór:

Jeśli ryzyko się nie zmienia, to jedynie oczekiwana cena E(P1) będzie się zmieniać w zależności od opinii o przyszłych zyskach. Oznacza to, że oczekiwana stopa zwrotu będzie się zmieniać pod wpływem opinii inwestorów o przyszłych zyskach, pomimo że ryzyko (lub opinia o nim) będzie niezmienne. W rzeczywistości jednak ryzyko i awersja do ryzyka może się dodatkowo zmieniać. Widać, że bieżąca cena P(0) będzie tym wyższa, im niższe będzie ryzyko (v) oraz niższa awersja do ryzyka (a).
Jeśli część (av) wzrośnie, wtedy P(0) może spaść. Wtedy oczekiwana stopa zwrotu może wzrosnąć, gdy wzrośnie ryzyko, a nie spaść, jak przewiduje model Millera. Model CAPM zostanie uratowany.
Literatura:
1. E. Miller - Risk, Uncertainty, and Divergence of Opinion, 1977,
2. R. Jarrow - Heterogeneous Expectations, Restrictions on Short Sales, and Equilibrium Asset Prices, 1980,
3. J. Lintner, "The Aggregation of Investor's Diverse Judgments and Preferences in Purely Competetive Security Markets", 1969.































{kind=link}
{kind=link}
{kind=link}