Rynek efektywny to taki, na którym wszelkie istotne informacje zostają natychmiast uwzględnione w cenach. Paradoksalnie w takiej sytuacji racjonalny inwestor nie powinien dyskontować informacji, gdyż szansa na to jest nikła. Jest takie powiedzenie o rynku efektywnym: Jeśli zobaczysz leżącego na ulicy dolara, nie podnoś go, bo już go ktoś znalazł przed tobą. Idiotyczne to, ale jakże znamienne dla rynku, któremu poświęcamy tyle czasu.
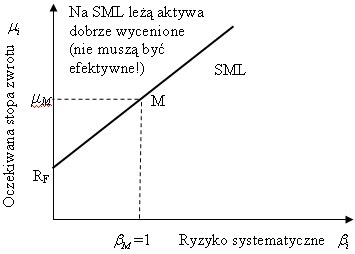
Inwestor dyskontujący informacje na doskonałym rynku, na którym wszyscy robią to samo co on, poniósłby duże ryzyko, inwestując w konkretne akcje. Jak pamiętamy, zgodnie z teorią efektywnego rynku oczekiwana stopa zwrotu z dowolnego papieru wartościowego leży na linii papierów wartościowych (SML). A zatem inwestor, który dyskontuje informacje powinien liczyć się z ryzykiem rynkowym wynoszącym beta.
Oczywiście mógłby inwestować w takie akcje, jeśli posiada niską awersję do ryzyka, ale i tak byłaby to zwykła spekulacja, bo zgodnie z teorią już ktoś przed nim albo w tym samym momencie co on zdyskontował wszelkie wiadomości.
Dlatego powinien stosować model linii rynku kapitałowego (CML) lub przynajmniej metodę Markowitza. W takim razie nikt nie powinien dyskontować informacji, lecz używać CML, a więc rynek przestałby być efektywny. Cóż za paradoks.
Oczywiście, gdyby wszyscy stosowali CML, ruchy cen nadal mogłyby być całkowicie losowe, lecz ważne wiadomości nie byłyby uwzględniane w cenach. Ktoś powie: a jakie to ma znaczenie, po prostu powstanie prawdziwy hazard. Jest to błędne rozumowanie.
Przychodzi informacja, że zysk spółki X wzrósł o 50% i zamierza ona o tyle samo zwiększyć dywidendę. Efektywny rynek powinien natychmiast na to zareagować zwyżkami cen, gdyż każdy może skorzystać z dodatkowego zysku firmy bez ryzyka. Po dniu ustalenia prawa do dywidendy (a na GPW 3 dni przed tym dniem, gdyż tyle trwa rozliczenie transakcji w KDPW) cena akcji powinna spaść dokładnie o wielkość stopy dywidendy, tak że informacja o dywidendzie już nie miałaby żadnego znaczenia dla kursów, a inwestor nie miałby żadnych korzyści z trzymania tych akcji, gdyż zysk z dywidendy zostałby skorygowany spadkiem kursu.
Jeśli wszyscy stosują CML, to kurs porusza się losowo, wobec czego w dniu ustalenia prawa dywidendy także. Ten dzień nie ma znaczenia. Oznacza to, że po tym dniu kurs nie musi spadać, lecz będzie zachowywać jak zwykle. Wynika z tego, że sprytny inwestor "wyłamujący się" ze schematu CML, mógłby znacznie więcej zarobić niż inni, czyli ponadprzeciętnie. Przerzuciłby wszystkie lub większość środków na spółkę X. Otrzymuje więc dużą dywidendę, a ponadto posiada ciągle akcje, których oczekiwana stopa zwrotu nie zmienia się (tj. nie spada). Wprawdzie ryzyko z samych akcji wzrasta (gdyż jak wiemy dywersyfikacja w CML jest maksymalna, a więc zapewnia najmniejsze ryzyko), ale zostaje to skompensowane dywidendą. Czy więc wychodzi na to samo, tzn. czy znów większy zysk jest okupiony większym ryzykiem? Nie, ponieważ inwestor zachowuje się tak, jakby stosował SML, czyli model bez dywersyfikacji, który właśnie przedstawia potencjalny większy zysk okupiony ryzykiem. A więc zgodnie z SML bez ryzyka niemożliwe jest uzyskanie zysku większego od stopy zwrotu z obligacji lub bonów skarbowych. A w omawianym przypadku dostajemy dodatkowy zysk z dywidendy. Tym samym inwestor pokonuje rynek, co jest niedopuszczalne na efektywnym rynku.
Oczywiście inwestorzy nie są głupi i szybko zauważyliby i wykorzystaliby takie możliwości. W zasadzie, wszyscy powinni tak zrobić, co oczywiście znów doprowadziłoby do powrotu rynku efektywnego. Ale jeśli każdy jest statystycznie identycznie spostrzegawczy, to statystyczny inwestor winien zarobić zero. A więc lepiej stosować strategię pasywną, bo po co się jak Syzyf męczyć... a więc każdy racjonalny jednak powinien nie dyskontować żadnych informacji i rynek znów staje się nieefektywny...
Znów więc stoimy wobec pytania, która postawa - aktywna czy pasywna - jest racjonalna na (efektywnym?) rynku?
Aby odpowiedzieć na to pytanie, zróbmy przykład. Powiedzmy, że na rynku są dwaj gracze A i B. Jeśli obaj dyskontują w tym samym czasie informację, to każdy zarobi V + 0 - Z, gdzie V - przeciętna wygrana wynikająca z SML lub CML - nie ma znaczenia która, gdyż oba modele po skorygowaniu o ryzyko dają te same oczekiwane stopy zwrotu. Dodajemy zero, gdyż 0 = 0,5*D + 0,5(-D), gdzie D - nadwyżka stopy zwrotu wynikająca ze zdyskontowania informacji (np. o dywidendzie). Któryś zarobi, ale średnio nikt. Z - koszt zarządzania wynikający z tego, że inwestor ciągle śledzi informacje napływające z minuty na minutę i dokonuje szybkich decyzji. Dla uproszczenia uznamy, że Z = V. A więc oczekiwany zysk, gdy wszyscy dyskontują informacje, równa się zero. Jeśli tylko jeden gracz dyskontuje informacje, to zarabia on V + D - Z = D, a wtedy drugi grając pasywnie, tj. stosując metodę CML, zarabia V. Jeśli obaj stosują CML, wtedy obaj zarabiają V. Dlaczego V nie rozdwaja się? Uznajemy, że parametry rozkładu stopy zwrotu są identyczne i niezależne od czasu. CML opiera się na tym, że po prostu kupujemy rynek, który zachowuje się losowo zgodnie z pewną wartością oczekiwaną (a ta jest z założenia stała).

Schemat ten został przedstawiony powyżej. Macierz jest symetryczna. Poziome strategie dotyczą gracza A, zaś pionowe gracza B. Lewa strona każdego okna odpowiada zyskom gracza A, prawa - oddzielona kreską - gracza B.
Od razu widać, że paradoks jest trudniejszy niż w standardowym przypadku paradoksu Newcomba. Strategia dominująca nie istnieje. Czy istnieje równowaga Nasha? Popatrzmy. Jeśli gracz A wybiera góra, wtedy gracz B wybiera zawsze prawa. Jeśli zaś B wybiera prawa, to A wybiera zawsze góra. Istnieje zatem równowaga Nasha. Ale jeśli gracz A wybiera dół, to gracz B wybiera zawsze lewa. Jeśli B wybiera lewa. to A wybiera zawsze dół. A więc też istnieje równowaga Nasha. Są dwie równowagi Nasha i prowadzi to do zamieszania. Musimy użyć więc strategii mieszanej. Chodzi tu o to, że gracze będą posługiwać się z pewnym prawdopodobieństwem strategią aktywną i pasywną. Gracz A z prawdopodobieństwem p stosuje strategię aktywną, a gracz B stosuje strategię aktywną z prawdopodobieństwem q. Oznacza to, że jeśli gracz A gra aktywnie, to dostaje z prawdopodobieństwem q zero (gdyż B stosuje z szansą q strategię aktywną) oraz z 1-q dostaje D (gdyż B stosuje z szansą 1-q strategię pasywną). Jeśli A gra pasywnie, to zawsze dostaje V, gdyż q*V +(1-q)*V = V. Jeśli gracz B aktywnie, to wszystko jest tak samo, lecz q zostaje zastąpione p. Należy zwrócić uwagę, kiedy używa się p, a kiedy q. A więc dla gracza A mamy:
Strategia aktywna: q*0 + (1-q)*D = D - q*D
Strategia pasywna: V.
Dla gracza B:
Strategia aktywna: p*0 + (1-p)*D = D - p*D
Strategia pasywna: V.
Gracz A stosuje strategię aktywną z prawdopodobieństwem p i pasywną z 1-p, lecz już przy danej strategii jego wygrana zależy od decyzji B, czyli prawdopodobieństwa q. Powstaje pytanie, ile musi wynieść p i q? Odpowiedź wydaje się logiczna. Wiadomo, że żadna strategia nie może być lepsza od drugiej, gdyż gracz zawsze by wybierał lepszą. Zatem wartość oczekiwana strategii aktywnej musi być równa wartości oczekiwanej strategii pasywnej. Weźmy gracza A:
D - q*D = V
q = (D - V)/D.
Dla gracza B:
p = (D - V)/D.
Stąd p = q.
W równowadze, gdy strategia aktywna jest równoważna pod względem wartości oczekiwanej strategii pasywnej, każdy gracz będzie dyskontował informacje z tym samym prawdopodobieństwem wynoszącym różnicę pomiędzy nadwyżkową stopą zwrotu a przeciętną stopą zwrotu podzieloną przez nadwyżkową stopę zwrotu.
Niech V = 100. Jeśli np. zysk w wyniku zdyskontowania istotnej informacji wynosi D = 1000, to p = (1000 - 100)/1000 = 0,9. Ale już przy D = 200, p = 0,5. A przy D = 100, p = 0, zaś przy D = 50, p = -1. Jak interpretować ujemne prawdopodobieństwo? Przypomnijmy, że założyliśmy, iż zmienna zarządzania Z = V. Jeśli więc zysk D jest mniejszy od kosztów zarządzania, to jest to to samo, co dopłacanie do rynku. Oznacza to, że aby inwestor dyskontował z jakąś szansą informacje, D > V.
Nasza dyskusja jest kluczowym momentem do zrozumienia, dlaczego rynki kapitałowe nie mogą być całkowicie efektywne, nawet jeśli wszyscy inwestorzy są równi i tak samo szybcy. Gracze - w równowadze - będą aktywnie dyskontować informacje na rynku efektywnym z prawdopodobieństwem (D-V)/D i będą grać pasywnie z prawdopodobieństwem 1 - (D-V)/D = V/D.
Jeśli częstość z jaką inwestorzy się zachowują jest znana, to jeśli trochę pomyślimy, dotrzemy do głębokiego wniosku. Jeśli mamy populację inwestorów, to (D-V)/D populacji będzie dyskontować informacje, a V/D jedynie grać pasywnie...
Teoria efektywnego rynku jest analogią teorii darwinowskiej, czyli teorii doboru naturalnego. Czytelnik sam to szybko zauważy, po przeczytaniu przytoczonego fragmentu pracy A. Łomnickiego: Ekologia ewolucyjna - 2008.
Proste rozumowanie wskazuje, że w sytuacji, gdy dwa osobniki walczą o ograniczone zasoby, na przykład gniazdo, samicę lub pokarm osobnik wygrywający powinien zostawić w przyszłych pokoleniach więcej swego materiału genetycznego, niż osobnik wykazujący tendencję do ustępowania. Zatem jeśli tendencja do ustępowania i tendencja, aby walczyć aż do wygranej lub do śmierci są genetycznie zdeterminowane, wówczas należy się spodziewać, że tendencja do ustępowania i wszelkie walki nie na serio, czyli typu konwencjonalnego powinny być już dawno wyeliminowane przez dobór. Jeśli akceptujemy takie rozumowanie, wówczas przyjmujemy też, że ustępowanie, unikanie konfliktów i wszelkiego rodzaju walki konwencjonalne nie mogły powstać drogą doboru naturalnego między osobnikami, ale jakimś innym sposobem. Konrad Lorenz w swych książkach sugerował, że takie zachowanie utrzymuje się, ponieważ jest dobre dla gatunku i zapobiega nadmiernej śmiertelności w wyniku agresji.
Za rozumowaniem Konrada Lorenza i wielu innych biologów myślących podobnie nie stał i nie stoi żaden opis mechanizmu doboru, który mógłby doprowadzić do powstania cech dobrych dla gatunku, a nie dla osobnika. Można stwierdzić, ze ograniczona agresja i walki konwencjonalne były w świetle Darwinowskiej teorii doboru naturalnego niezrozumiałe, a neodarwinizm z genetyką populacyjną też tych zjawisk nie tłumaczył. Była to wyraźna słabość biologii ewolucyjnej, która skończyła się, gdy do badania konfliktów między zwierzętami zastosowano teorię gier.Łomnicki przedstawia w jaki sposób w ewolucji ukształtował się pewien podział na "agresorów" (jastrzębie) i "ustępujących" (gołębie). Zarówno jastrzębie jak i gołębie mogą współistnieć. Co więcej, muszą występować zarówno i ci, i ci. Zastosowana strategia jest właśnie tą, jaką tutaj zaprezentowaliśmy. Strategia ta nazywana jest strategią ewolucyjnie stabilną. Przytaczam kolejny fragment:
Strategia mieszana może być realizowana na dwa sposoby. Przy pierwszym sposobie, wszystkie osobniki w populacji mogą posługiwać się takim samym programem: z prawdopodobieństwem P bądź agresorem, zaś z prawdopodobieństwem (1 - P) bądź ustępującym. Przy sposobie drugim bycie agresorem lub ustępującym jest cechą zdeterminowaną genetycznie i dobór będzie prowadził do polimorfizmu zrównoważonego, czyli takiego, przy którym proporcja agresorów będzie równa P. (s. 1)
(...)
ewolucyjnie stabilna strategia mieszana wyjaśnia częściowo zmienność genetyczną w naturalnych populacjach. Taką zmienność można sprowadzić do problemu zrównoważonego polimorfizmu genetycznego, czyli utrzymywania się w populacji w jednym locus dwóch lub więcej różnych alleli. Genetyka populacyjna tłumaczy polimorfizm genetyczny wyższym dostosowaniem heterozygot w stosunku do obu homozygot i doborem zależnych od częstości allelu, powodującym niższe dostosowanie formy bardziej pospolitej. Koncepcja mieszanej strategii ewolucyjnie stabilnej sugeruje jeszcze jeden powód doboru zależnego od częstości i tym samym utrzymywania się zmienności genetycznej przy założeniu, że strategia mieszana jest zdeterminowana genetycznie. (s. 4).
Jest to właśnie to o czym mówiliśmy. Częstość danej strategii może być używana przez naturę jako całość, bądź przez pojedyncze osobniki.
Wyobraźmy sobie, że populacja składa się tylko z gołębi. Nagle w wyniku mutacji pojawia się jastrząb. Jak to w przyrodzie, jednostki walczą ze sobą. Jastrząb wygrywa każdą potyczkę, co zwiększa szansę na pozostawienie potomstwa. Można byłoby krzyknąć, że gołębiom grozi zagłada! Załóżmy więc, że gołębie zostały zgładzone i zostały same jastrzębie. Doprowadzi to do wyniszczenia gatunku, gdyż każdy jastrząb ma taką samą szansę wygranej. Straty statystycznie będą większe od zysków (u nas byłby to koszt zarządzania większy od wygranej: D < Z). Nagle pojawia się mutacja w postaci gołębia. Biedaczyna nie ma szans, chociaż... jeśli statystyczna wygrana jest mniejsza od ceny przegranej gołębia, to okaże się, że gołąb będzie statystycznie zarabiał na przegrywaniu więcej niż jastrzębie! Skutkiem będzie wzrost liczebności gołębi. Okazuje się więc, że ze statystycznego punktu widzenia musi istnieć pewna proporcja gołębi i jastrzębi.
Na rynku efektywnym słabsi lub - co wychodzi na jedno - ustępujący gracze, powinni zostać wyeliminowani przez agresywnych i szybkich inwestorów. Wolniejsi nie zdołaliby zdyskontować informacji przed szybkimi, straciliby więc wszystkie pieniądze, bo to szybcy sprzedawaliby im lub odkupywaliby od nich. Ale widzieliśmy do czego prowadzi taka sytuacja. Zastępując gołębie graczami pasywnymi, a jastrzębie graczami aktywnymi, natura ekonomiczno-psychologiczna doprowadzi do współistnienia tych dwóch typów graczy.
Pasywny nie musi tu wcale oznaczać, że stosuje CAPM. Może oznaczać po prostu gracza, który ucieka z pola walki.
Jest dwóch graczy, którzy trzymają akcje. Dokupić czy sprzedawać? Chiken? Macierz jest podobna do tej pierwszej z małym wyjątkiem. 0 - gdy obaj dokupują. Windują cenę tak, że nikt od nich drożej nie odkupi, D - gdy dokupuje pod warunkiem, że drugi sprzedaje, V - gdy sprzedaje pod warunkiem, że drugi kupuje, V/2 - obaj sprzedają. W tym ostatnim przypadku siła podaży silnie zaniża cenę i obaj średnio zarabiają V/2. Oto macierz w tym przypadku:

Obliczmy p w równowadze (ze względu na symetrię macierzy p jest nadal równe q).
Dokupuje: p*0 + (1-p)*D = D - p*D
Sprzedaje: p*V + (1-p)*V/2 = p*V + V/2 - p*V/2
D - p*D = p*V + V/2 - p*V/2
p = (D - V/2)/(D + V/2).
A więc też bardzo ładny wynik.
Zakładamy istnienie trendu zwyżkującego. Aby zaistniała równowaga jeden z nich musi ustąpić - sprzedać, aby drugi mógł kupić. Jest to ważne, gdyż w następnej rozgrywce mogą się zastąpić miejscami. Tak tworzą trend.
Nie znaczy to, że muszą całkowicie nie zgadzać się co do tego czy będą w najbliższym czasie wzrosty czy spadki. Jeśli gracz A ma horyzont krótkoterminowy, a gracz B długoterminowy, to obaj mogą rozumować nieco innymi kategoriami. Inną możliwością wymiany a nie konkurencji, jest to, że gracz, który ma większy kapitał lub też dłużej trzyma dane akcje, więcej na nich zarobił i może być bardziej skłonny do sprzedaży akcji pomimo, iż może zgadzać się, że warto ciągle je kupować. Nawet jeśli prawdopodobieństwo dalszych zwyżek wynosi więcej niż 50:50 i tak będzie odczuwał pokusę realizacji zysków. Co więcej, będzie miał rację, bo w przeciwnym wypadku, jeśli wielu będzie takich jak on, którzy nie zdecydują się na sprzedaż, to nastąpią spadki. Jeśli jednak wielu się zdecyduje na sprzedaż, wtedy lepiej dokupować, a wygrana D gwarantowana. Statystycznie należy raz ustąpić, raz nie.
Tak, udało się. Rozwiązaliśmy paradoks rynku efektywnego. Rynek staje się fraktalny, czyli ułamkowo efektywny, gdyż tylko część graczy będzie dyskontować w pełni informacje (na przykład o istnieniu trendu - na efektywnym rynku trend powinien natychmiast zniknąć, gdy wszyscy się o nim dowiadują) lub też wszyscy będą dyskontować informacje z pewnym prawdopodobieństwem. Ta część lub to prawdopodobieństwo zależy od maksymalnej wygranej i od przeciętnej wygranej i można je łatwo obliczyć. Świadczy to o tym, że na giełdzie nie warto maksymalizować zysków za wszelką cenę.
Źródło:
1. A. Łomnicki, Ekologia ewolucyjna - 2008. Strategia ewolucyjnie stabilna,
2. T. Rostański, M. Drozd, Teoria gier, 2003.
................................................................................
We wpisie "Jak powstają cykle i podcykle? Ułamkowość jest wszędzie. Część piąta": http://gieldowyracjonalista.blogspot.com/2009/10/jak-powstaja-cykle-i-podcykle-uamkowosc.html napisano:
Przede wszystkim należy zauważyć, że zbiorowość jako pewna zorganizowana struktura tworzy się dlatego, że siła (użyteczność) zbiorowości jest wyższa niż siła (użyteczność) sumy jednostek ją tworzących. Pod tym względem rzeczywiście rynek zdobywa siłę, kształtuje się trend. To jest to, o czym pisałem w drugiej części cyklu, że inwestorzy niejako sami się racjonalizują. Aby utrzymać organizm przy życiu komórka musi współpracować z innymi komórkami.
Wcześniej, w "Jak powstają cykle i podcykle? Część druga": http://gieldowyracjonalista.blogspot.com/2009/08/jak-powstaja-cykle-i-podcykle-czesc.html stwierdzono:
Rynek kapitałowy jest ograniczony pewną ilością kapitału w danym przedziale czasowym. Musi "racjonalizować" tę ilość, czyli wykorzystywać kapitał jak najwydajniej. Choć zabrzmi to bardzo ezoterycznie, "coś" zmusza inwestorów do zachowania ograniczonej racjonalności. Ekonomicznie może być to ograniczony horyzont czasowy, a psychologicznie - pokusa kupna lub sprzedaży. Połączenie homo oeconomicusa i człowieka nieracjonalnego daje pewną kombinację: człowieka ograniczenie racjonalnego.Można zajrzeć:
1. http://gieldowyracjonalista.blogspot.com/2009/08/jak-powstaja-cykle-czesc-pierwsza.html
2. http://gieldowyracjonalista.blogspot.com/2009/08/jak-powstaja-cykle-i-podcykle-czesc.html
3. http://gieldowyracjonalista.blogspot.com/2009/09/jak-powstaja-cykle-i-podcykle.html
4. http://gieldowyracjonalista.blogspot.com/2009/09/jak-powstaja-cykle-i-podcykle-giedowy.html
5. http://gieldowyracjonalista.blogspot.com/2009/10/jak-powstaja-cykle-i-podcykle-uamkowosc.html
6. http://gieldowyracjonalista.blogspot.com/2009/10/jak-powstaja-cykle-i-podcykle-czesc_18.html
Teraz wszystko zaczyna łączyć się w jedną całość. Dotąd brakowało tego budulca w postaci teorii gier, która rozwiązuje problem racjonalności i efektywności rynku.






































{kind=link}
{kind=link}
{kind=link}