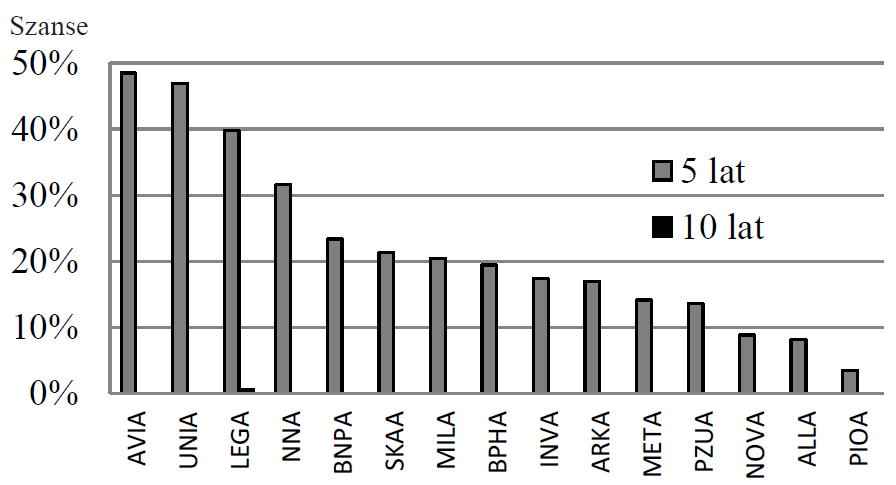
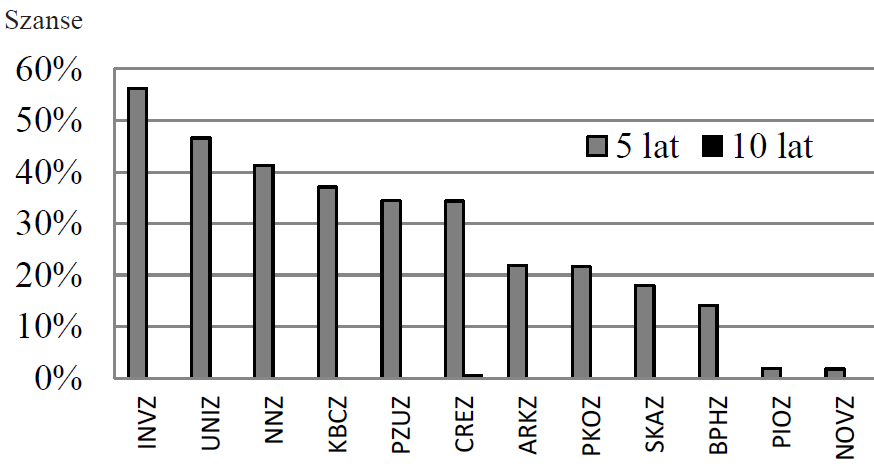
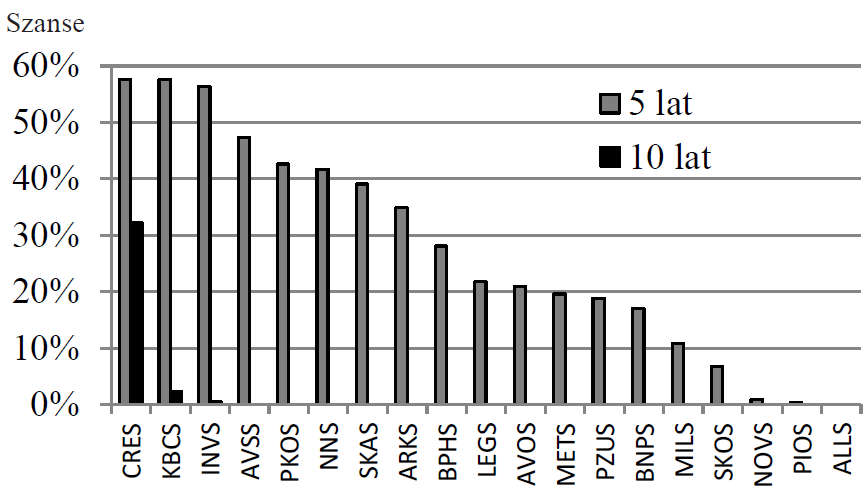
Powiedzmy, że zastanawiamy się czy zainwestować w jakieś akcje. Oczywiście standardowym narzędziem do tego jest wycena zdyskontowanych przepływów pieniężnych lub dywidend. Jeśli model wycenił spółkę na poziomie niższym niż bieżąca kapitalizacja, to dostajemy sygnał kupna. W przeciwnym wypadku dostajemy sygnał sprzedaży. Niestety wycena to problem skomplikowany i oparty na wielu założeniach. Nawet wspomagana przez analizę fundamentalną, w której bierzemy pod uwagę nie tylko czynniki wewnętrzne, ale i otoczenie firmy, może zawieść. Łatwiej zastosować samą AF opartą na wskaźnikach lub analizie dyskryminacyjnej. Zagadnienie tej ostatniej już poruszyłem (
tutaj ,
tutaj , dla banków -
tutaj) i należy stwierdzić, że jest wyjątkowo użyteczna, będąc jednocześnie techniką prostą i precyzyjną, bo mówi konkretnie czy firma jest w dobrej czy złej kondycji (w przeciwieństwie do analizy wskaźnikowej, która jest niejednoznaczna). Jej wadą jest jednak na stałe ustalenie wielkości parametrów (na podstawie testów na innych próbach z przeszłości). Podobną rolę do analizy dyskryminacyjnej odgrywają liniowy model prawdopodobieństwa oraz regresja logistyczna (model logitowy; logit), ale dostarczają one jeszcze dokładniejszej informacji: jakie jest prawdopodobieństwo, że na przykład firma jest w dobrej albo złej kondycji; jakie jest prawdopodobieństwo bankructwa. A zatem dostajemy nie tyle sygnał kupna lub sprzedaży, co prawdopodobieństwo sygnału (jakkolwiek to dziwnie brzmi). Należy dodać, że logit jest to metoda dużo bardziej skomplikowana i trudniejsza do zrozumienia i żeby ją zastosować konieczne jest użycie programu komputerowego, najlepiej do ekonometrii. Ja używam gretla.
Skoro chcemy uzyskać szansę tylko na to, że będzie dobrze lub źle, to znaczy, że zmienna Y ma tylko dwie wartości: 0 (będzie źle) lub 1 (będzie dobrze). Zacznijmy więc od najprostszego przykładu rzutu monetą, która nie musi być sprawiedliwa. Powiedzmy orzeł - 1, reszka - 0. Chcemy orła. Rzucamy raz monetą - udało się. Rzucamy drugi raz - znów orzeł. Za trzecim razem jest reszka. Rzucamy tak wielokrotnie i zapisujemy wyniki. Teraz chcemy sprawdzić prawdopodobieństwo wyrzucenia orła. Oczywiście nie potrzebujemy do tego żadnych cudów, logitów. Zwyczajnie obliczamy częstość wyrzuconych orłów i dzielimy przez liczbę wszystkich rzutów. Mamy więc to czego szukaliśmy. Powiedzmy, że zastępujemy monetę samochodem jadącym po trudnej drodze - 1 to brak wypadku, 0 to wypadek. Chcielibyśmy sprawdzić szansę, że wypadku nie będzie. Porównując auto z monetą napotykamy problem - nie możemy go testować wielokrotnie, ale tylko raz. Co zrobić? Moglibyśmy wprawdzie sprawdzić statystyki wypadków w kraju w ciągu roku i podzielić na liczbę jadących samochodów w tym samym czasie. Pomijając kwestię aktywnych samochodów, to taka metoda obliczania prawdopodobieństwa przypomina przysłowie o średniej liczbie nóg człowieka i psa. Przecież podejrzewamy, że aby doszło do wypadku, muszą zajść jakieś okoliczności, chcemy ustalić jakieś zmienne, które do tego prowadzą. Bez dokładniejszych informacji, obliczanie średniej częstości nie ma dla nas sensu. Chcemy większej precyzji, stąd pierwszy pomysł odpada. Musimy odkryć związek między jakimiś zmiennymi a zdarzeniem się wypadku, a następnie znaleźć jakiś sposób na obliczenie prawdopodobieństwa wypadku. W przypadku logitu będzie w zasadzie na odwrót: najpierw znajdziemy prawdopodobieństwo, a ono doprowadzi nas do związku między zmiennymi.
Liniowy model prawdopodobieństwa
Skoro szukamy zmiennej zależnej i niezależnej, to powróćmy na chwilę do monety. Na wynik monety wpływała tylko jej budowa, a nie to, jak nią rzucamy. Budowa mogła powodować większe szanse wyrzucenia orła od reszki lub na odwrót. Co więcej, gdyby moneta była idealnie sprawiedliwa, to nawet budowa nie wpływałaby na zdarzenie oprócz tego, że pozwala jedynie na 0 lub 1. Innymi słowy w tym przypadku Y = X, gdzie Y to wyrzucenie 0 lub 1, a X to zmienna wpływająca na Y i przyjmuje to samo co Y. Jeżeli podejrzewamy, że moneta jest niesprawiedliwa, to to równanie musi się zmienić, np. na Y = a + b*X. Teraz moneta została jakby rozbita na dwie części: same zdarzenia Y oraz zdarzenia, które X wpływają na Y, ale nie są już tożsame z Y.
Wróćmy do przykładu z samochodem. Podobnie jak z monetą, musimy spytać co będzie miało wpływ na wypadek. Gdyby Y = X, to znaczyłoby, że na wypadek wpływa jedynie sama budowa samochodu i jego "wewnętrzne zagrożenia" albo sam kierowca. Głównym czynnikiem tworzącym zagrożenie są umiejętności kierowcy i jego stan psychiczny. Dla uproszczenia połączymy obie te cechy w jedną zmienną X: kierowca o wysokich umiejętnościach i w dobrym stanie psychicznym (1) lub nie spełniający tych wymagań (0). Gdyby nie było innych zakłócających czynników, to równanie Y = X mogłoby zostać spełnione: dobry kierowca (X = 1) nigdy nie miałby wypadku (Y = 1), natomiast zły kierowca (X = 0) zawsze miałby wypadek (Y = 0). Ta idealna korelacja rzecz jasna nie jest prawdziwa, ale pozwala dobrze zobrazować początkową sytuację. Znalezienie prawdopodobieństwa sprowadzałoby się do określenia z jakim kierowcą mamy do czynienia. I nagle spostrzegamy, że szansa musiałaby wynosić dokładnie 1 albo 0, bo utożsamiliśmy idealnie zdolności kierowcy z zagrożeniem wypadku. Skąd ta różnica w porównaniu z monetą? Rzucanie sprawiedliwej monety (bo o takiej teraz mówimy) to czysty los, natomiast zdolności i stan kierowcy losowe nie są. Można te zdolności oczywiście traktować jak zmienną losową, jednakże to właśnie fakt, że nie są w pełni losowe, pozwala na lepsze przewidywanie zdarzeń.
Oczywiście taka idealna zależność nie występuje, dlatego równanie Y = X należy także tutaj poprawić. Pytanie jak? Zacznijmy od liniowej zależności Y = a + b*X. Jeżeli X = 0, to Y = a, zaś gdy X = 1, to Y = a + b. To jednak ciągle oznacza doskonałą korelację równą 1: X to zawsze przekształcony Y. Załóżmy, że a = 0. Wtedy zawsze Y = 0 gdy X = 0. Dla b = 1, gdy X = 1, Y = 1. Zmienne zachowują się identycznie. W rzeczywistości relacja X-Y jest statystyczna, więc powinna być modelem regresji. To znaczy, że powinna zawierać dodatkowo składnik losowy. Czyli moglibyśmy zapisać
gdzie ε to składnik losowy. Wtedy dostajemy linię regresji jako warunkową wartość oczekiwaną Y względem X:
Zauważmy, że wartość oczekiwana Y równa się prawdopodobieństwu zajścia zdarzenia Y:
(1)
gdzie p to prawdopodobieństwo, że Y przyjmie wartość 1.
W tym miejscu ważne spostrzeżenie: skoro p to prawdopodobieństwo, że Y = 1, to znaczy, że:
(2)
Analogicznie warunkowa wartość oczekiwana Y będzie się równać prawdopodobieństwu warunkowemu zajścia zdarzenia Y pod warunkiem X:
(3)
Znów ważne jest to, że mamy tu do czynienia z prawdopodobieństwem warunkowym p, że Y wyniesie 1:
(4)
To kluczowy moment do zrozumienia dalszego wywodu. Warunkowa wartość oczekiwana Y to pewna średnia pod warunkiem, że X wyniesie (0 lub 1). A skoro średnia, to jest to tylko coś między 0 a 1. Ta średnia będzie jednak równa prawdopodobieństwu, że Y właśnie wyniesie 1 (pod warunkiem, że X równa się coś). To trudny, ale ważny element teorii.
Jeżeli regresja Y byłaby liniowa, to dostajemy:
Taki model nazywa się
liniowym modelem prawdopodobieństwa. Parametry a i b znajdujemy normalnie metodą MNK lub inną.
Przykład 1.
Stworzyłem przykładowy zestaw 50 danych: X - Czy kierowca ma zdolności? 1 - Tak, 0 - Nie. Y - Czy brak wypadku? 1 - Tak, 0 - Nie.
Wchodzimy do gretla. Model ->Klasyczna metoda najmniejszych kwadratów. Zaznaczamy jako zmienną niezależną Czy_kierowca_ma_zdolnosci, a jako zależną - Czy_bez_wypadku. Wynik:
Z uzyskanego okna wyników wchodzimy w Prognozę. Otrzymujemy:
Model wskazuje teoretyczne prawdopodobieństwa (prognozy), jego błędy ex-ante i przedział ufności. Weźmy pierwszą obserwację: był wypadek (0), a prognoza, że nie będzie wypadku to 30%. Skąd wiem, że o tym mówi prognoza? Właśnie stąd, co wcześniej napisałem, że
prognoza to prawdopodobieństwo, że Y = 1 pod warunkiem X. To pod warunkiem X powoduje, że nie powiedziałem wszystkiego. Prognoza, że nie będzie wypadku wynosi 30%, ale
tylko dla tej jednej obserwacji. A ta jedna obserwacja spełnia pewne warunki. Tym warunkiem jest zmienna X. To znaczy, że dostajemy szansę 30%, że nie będzie wypadku, ale tylko wtedy, gdy X równa się... i tu musimy wrócić do pierwszego rysunku, gdzie jest lista wartości zmiennej Czy_kierowca_ma_zdolnosci. Pierwsza wartość wynosi zero. Czyli wiemy już, że gdy X = 0 (gdy kierowca nie ma zdolności) to prawdopodobieństwo, że Y = 1 (że nie będzie miał wypadku), wynosi tylko 0,3, co jest równoznaczne z tym, że będzie miał wypadek na 70% (1 - 0,3 = 0,7).
Dla drugiej obserwacji Y = 1, a p = 0,6. Sprawdzamy pierwszy rysunek, wartość X(2) = 1. Czyli wiemy już, że gdy X = 1 (gdy kierowca ma zdolności) to prawdopodobieństwo, że Y = 1 (że nie będzie miał wypadku), wynosi 0,6.
Żeby pokazać zmienne niezależne i prognozę, zapisuję prognozy (+ w oknie prognozy) jako zmienną Pr_Czy_bez_wypadku_lin1. W oknie głównym zaznaczam tę nową zmienną razem z Czy_kierowca_ma_zdolnosci, i wyświetlam tabelę:
Faktycznie, dostaję to czego oczekiwaliśmy.
Podsumowując ten przykład, jeżeli mamy dobrego kierowcę, to spokojnie przejedziemy z prawdopodobieństwem 0,6, a jeżeli mamy złego kierowcę, to będziemy mieć wypadek z prawdopodobieństwem 0.7. Widzimy więc, że nie ma symetrii między odwrotnymi przypadkami.
Przykład 2.
Spróbujmy model poprawić, dodając drugi czynnik - otoczenie. Nowa zmienna niezależna X2 będzie pytać czy inni kierowcy mają zdolności? Tak - 1, Nie -
0. Dane tak samo własnoręcznie stworzyłem. Tabela wszystkich zmiennych z wartościami
jest teraz taka:
Wszystko robimy tak samo jak poprzednio, tylko dodajemy nową zmienną niezależną do modelu.
Model się znacznie poprawił (AIC, BIC, HQC). Spójrzmy na prognozy:
Jak widać prognozy wypadków już dużo bardziej się zmieniają niż w
pierwszym modelu. Mimo wszystko możemy bez nowych obserwacji sami
wychwycić p. Zapiszmy prognozę w bazie danych (znak + w oknie prognozy),
np. o nazwie Pr_Czy_bez_wypadku_lin2. W oknie głównym zaznaczmy
zmienne niezależne i nowo dodaną zmienną.
Wyświetlamy:
Gdy X1 = 0 i X2 = 0, to p = 0,13. Gdy X1 = 1 i X2 = 1, to p = 0,826. Gdy
X1 = 1 i X2 = 0, p = 0,4. Gdy X1 = 0 i X2 = 1, p = 0,554. Te wielkości
potem się powtarzają, stąd łatwo zgadniemy jakie będzie p dla nowych
obserwacji (nowych kierowców). Jednak przy 3 zmiennych będzie
to już na tyle skomplikowane, że nie opłaca się samemu tego robić i lepiej skorzystać z automatycznej prognozy.
Powiedzmy, że dostajemy nową obserwację X, tzn. nowego kierowcę, o
którym wiemy, że bywa pijany, czyli X1 = 0, a do tego kierowcy, którzy jadą obok niego łamią prawo, bo stracili prawo jazdy, tj. X2 = 0. Nie wiemy, czy nastąpi wypadek, czyli nie posiadamy
wartości Y. Dostajemy realną sytuację, w której
przewidujemy przyszłość, tzn. chcemy się dowiedzieć, jaka jest szansa, że nie
będzie wypadku. W Dane -> Dodaj obserwacje dodajemy 1 obserwację,
zaznaczamy zmienną X1, X2 i Dane - > Edycja wartości. Możemy wpisać 51
obserwację, tj. X1 = 0, X2 = 0. Co ważne, nie dodajemy Y. Teraz ponownie wchodzimy w KMNK, zaznaczamy wszystko tak jak poprzednio i wchodzimy w prognozę. Dostałem:
Otrzymaliśmy to, czego oczekiwaliśmy, tj. p = 0,13. Jak wyżej napisałem, można samemu do tego dojść przy małej liczbie zmiennych, ale przy większej już taka procedura byłaby niezbędna.
W ten sposób uzyskujemy prosty model do szacowania poziomu zagrożenia.
Liniowy model prawdopodobieństwa jest prosty i dość logiczny, ale ma dwie wady. Po pierwsze, w tablicy prognoz, przedział ufności zawiera liczby ujemne, a także powyżej 1. A przecież prawdopodobieństwo nie może być ujemne ani wyższe od 1. W omawianym przypadku problem ten ma charakter czysto teoretyczny, bo nie dostaniemy prognoz poniżej 0 ani powyżej 1. Niemniej mogą się pojawić przykłady, że gdy takie wartości się pojawią.
Druga wada jest z punktu widzenia analizowanego przykładu poważniejsza. Bo na jakiej właściwie podstawie założyliśmy, że
zależność Y-X jest liniowa? I stąd, dlaczego prawdopodobieństwo
zdarzenia Y ma być funkcją liniową X? Gdy stosujemy klasyczną regresję
liniową, to zazwyczaj patrzymy graficznie czy obserwacje X układają się
liniowo względem Y. A jak się dzieje w tym przypadku? Wykres punktowy wygląda następująco:
Oczywiście wiele z 50 danych nakłada się na siebie, bo wszystkie mają tylko 0 lub 1.
Regresja logistyczna
Czy można rozwiązać nasz problem bez założenia liniowej zależności X-Y? Powiedzmy, że mamy jakąś ogólną statystyczną zależność X od Y:
(5)
gdzie ε to składnik losowy.
Rozwiązanie tego zadania wiąże się z wykorzystaniem
zasady maksymalnej entropii. To ona doprowadza do wzoru na
regresję logistyczną, który
wyprowadziłem poprzednim razem:
(6)
gdzie:
p(i) - prawdopodobieństwo i-tego zdarzenia dla zmiennej X, która przyjmuje wartości x(i, 1), x(i, 2), ..., x(i, K).
Reszta to stałe.
Ponieważ są dwa zdarzenia Y, to i = 1, 2. Natomiast dla X jest w sumie K*i + 1 zdarzeń.
Mamy tu czynienia z K-wymiarową zmienną X. W naszym przypadku K = 1:
(7)
W uproszczeniu:
(8)
Model (7) można też przekształcić do postaci:
(9)
Ponieważ szukamy p(Y = 1 | X), to (7), dla którego i = 1 (bo i = 1, 2), zapiszemy:
(10)
Pamiętajmy przy tym, że ciągle jest spełniona tożsamość (4), stąd:
(11)
Sumarycznie moglibyśmy zapisać:
Zmienną z formalnie należy traktować jako stałą wartość. Dla wszystkich zdarzeń, tj. X, p stanie się funkcją prawdopodobieństwa - dystrybuantą rozkładu logistycznego:
(12)

Powstaje nieco zagmatwana sprawa. Zgodnie z (12) zmienna Z ma rozkład logistyczny. Ale jedyną zmienną losową tworzącą Z jest X proporcjonalny do Z, zatem X też musi mieć rozkład logistyczny (tzn. rozkład prawdopodobieństwa zmiennej Z jest rozkładem logistycznym). Co się dzieje jednak z Y? Zmienna ta nie może być tożsama ze zmienną Z, bo by idealnie korelowała z X bez błędów losowych. To znaczy, że brakuje jej składnika losowego w Z. Pytanie czy ten składnik można po prostu dodać do Z? Okazuje się, że dla jednej zmiennej X można tak zrobić, ale nie gdy występuje więcej zmiennych. Np. jeśli X = 1, a beta(0) = 0, beta(1) = 0,5 to Y = 0,5 + składnik losowy. Pamiętajmy, że Y to zmienna zero-jedynkowa, więc składnik losowy przyjmie wartość 0,5 albo -0,5. Wartość oczekiwana składnika losowego równa się zero i powinien być niezależny od X, co powoduje, że E(Y | X) = 0,5. Jeżeli jednak występują dwie zmienne niezależne, X1 i X2, wtedy jeśli beta(0) = 0, beta(1) = 0,5 oraz beta(2) = 0,7, to E(Y | X) = p = 0,5 + 0,7 = 1,2, czyli p > 1. Do tego nie może dojść, gdyż nie dopuszcza do tego sama konstrukcja wzoru (12). Prawdopodobieństwo po prostu nie może przekraczać 1. Wobec tego niemożliwe jest zwyczajne dodanie składnika losowego do Z, aby dostać Y. Oznacza to, że Y będzie funkcją nieliniową i poszukiwana funkcja g będzie postaci:
W sumie możemy jedynie napisać:
I tak jak stwierdziliśmy wyżej, w przypadku tylko jednej zmiennej niezależnej X - ale tylko zero-jedynkowej - prawdziwe będzie równanie:
co oznacza, że
dla funkcji jednej zmiennej regresja logistyczna pokrywa się z modelem liniowym prawdopodobieństwa. Jaka jest tego przyczyna? Po prostu X ma tylko dwa punkty, a więc Y też musi mieć! Skacze więc z jednego punktu do drugiego i stąd sztucznie zachowuje się jak funkcja liniowa.
Dla zmiennej X nie-zerojedynkowej już tak nie będzie.
Pozostało zadanie estymacji parametrów. Chociaż doszliśmy do dość zadziwiającego liniowego wyniku dla 1 zmiennej X, który prowadzi do wniosku, że można parametry poszukać MNK, to w ogólnym przypadku korzysta się z metody największej wiarygodności. Poszukuje
się w niej w takich parametrów, aby prawdopodobieństwo
obserwowanych danych (zmiennych o rozkładzie logistycznym) było największe. Na szczęście to trudne zadanie wykonuje program.
Przykład 3.
Wykorzystamy te sam zestaw 50 danych co w przykładzie 1: X - Czy kierowca ma zdolności? 1 - Tak, 0 - Nie. Y - Czy brak wypadku? 1 - Tak, 0 - Nie:
Wchodzimy w gretla. Model -> Ograniczona zmienna zależna -> model logitowy -> binarny. Zaznaczamy jako zmienną niezależną Czy_kierowca_ma_zdolnosci, a jako zależną - Czy_bez_wypadku. Dodatkowo zaznaczamy opcję Pokaż wartość p (zamiast Pokaż efekt krańcowy dla średniej). Dostałem taki wynik:

Model okazuje się istotny statystycznie. Poniżej widzimy macierz błędów: Dane przewidywane (Y) kontra empiryczne (X): wiersz drugi, kolumna 2, czyli 1x1, oznacza ile razy model trafnie przewidywał brak wypadku (18). Mówiąc inaczej, ile razy występowało Y = 1 oraz X = 1. Wiersz pierwszy, kolumna pierwsza, czyli 0x0, oznacza ile razy model trafnie przewidywał wypadek (14). Mówiąc inaczej, ile razy występowało Y = 0 oraz X = 0. Pierwszy wiersz, druga kolumna, czyli 0x1 pokazuje ile razy model błędnie przewidywał, że kierowca przejedzie bez wypadku (12). Drugi wiersz, pierwsza kolumna, czyli 1x0 pokazuje ile razy model błędnie przewidywał, że kierowca będzie miał wypadek (6). Jak widać najwięcej błędów model popełnił przewidując brak wypadku, gdy kierowca miał zdolności, natomiast stosunkowo niedużo błędów popełnił szacując wystąpienie wypadku, gdy kierowca nie miał zdolności. Jest to sygnał, że słabe zdolności kierowcy rzeczywiście będą prognozować wypadek, natomiast wysokie zdolności mogą nie być wystarczającym czynnikiem do oceny czy nastąpi wypadek.
Zanim poprawimy model, sprawdźmy w końcu to, do czego od początku dążyliśmy - jakie jest prawdopodobieństwo Y = 1. Z uzyskanego okna wyników wchodzimy w Prognozę. Otrzymałem:
A zatem tak samo jak w liniowym modelu, każda obserwacja generuje prawdopodobieństwo wypadku, p(i, t). Jest to możliwe, bo wykorzystujemy teoretyczny poziom prawdopodobieństwa, dla którego, jak wyżej napisałem, X przyjmuje konkretne wartości dla t-tej obserwacji. Wg modelu, jeżeli kierowca ma zdolności, to szansa na brak wypadku, wynosi tylko 60%. A jeśli nie ma zdolności, to 30%. Czyli dostajemy to samo co w liniowym modelu, co wyżej sami przewidzieliśmy.
Przykład 4.
Spróbujmy model poprawić dodając nową zmienną niezależną X2, tę samą co w przykładzie 2: czy inni kierowcy mają zdolności? Tak - 1, Nie - 0. Tabela wszystkich zmiennych z wartościami jest teraz taka:
Wszystko robimy tak samo jak poprzednio, tylko dodajemy nową zmienną niezależną do modelu. Wynik dla logit:
Wszystkie kryteria, od BIC do AIC się poprawiły, czyli model się poprawił. Widać to zresztą po macierzy błędów: sumarycznie wcześniej było 18 błędów (12+6), teraz 14 (6+8). Nowa zmienna okazuje się bardzo istotna stat. Teraz prognoza:
Zapiszmy prognozę w bazie danych (znak + w oknie prognozy), np. o nazwie Pr_Czy_bez_wypadku_log2. Wszystkie kolejne kroki możemy powtórzyć z przykładu 2. Czyli znów, chcąc prognozować wypadek, mając nowe informacje o X1 i X2, dopisujemy je do obserwacji i sprawdzamy jaka będzie prognoza Y.
Widzieliśmy, że dla X o 1 zmiennej prognozy w modelu liniowym i logicie były identyczne. Porównajmy teraz prognozy z przykładu 2 i przykładu 4:
Okazuje się, że prognozy są bardzo podobne, choć tym razem nieco się różnią.
Na koniec zaznaczę, że zarówno liniowy model prawdopodobieństwa jak i regresja logistyczna nie muszą być stosowane tylko dla zero-jedynkowej zmiennej X. To Y musi być zawsze binarny. Więcej o tym, z przykładami, napiszę następnym razem.