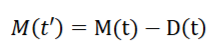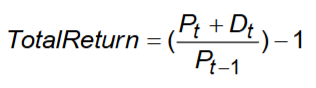I znowu model zawiódł. Prawdopodobieństwo wzrostu WIG20 w poprzednim tygodniu szacowałem na ponad 0,6. Jednak indeks spadł. Diagnostyka nie wykryła jakichś nieprawidłowości, szczególnie model wybrany zgodnie z kryterium DAC w próbie testowej 30 obserwacji wydawał się całkiem poprawny. Doszedłem do wniosku, że problem może leżeć w zbyt niskim DAC po reestymacji. Wówczas dostałem 63,5% poprawnych odpowiedzi, co było niewystarczające dla 30 danych (nieistotne), tak że ciągle był to raczej przypadek. O tym żeby uznać to za coś więcej, przekonała mnie korelacja 0,67 między reestymowanymi prognozami kroczącymi na podstawie różnych kryteriów (HQC i DAC-of-sample). Mógł to być oczywiście pech, ale trzeba wziąć pod uwagę inne powody.
Pierwsza sprawa to wielkość próby. Użyte 200 obserwacji w próbie uczącej to nie jest za dużo jak na taki model. Wybrałem 200 tygodni ad hoc na takiej zasadzie, żeby z jednej strony obliczenia nie trwały za długo, a z drugiej, żeby uwzględnić przynajmniej jeden cykl giełdowy, który mniej więcej tyle trwa. Może być to jednak za mało. Z drugiej strony rodzi się problem reestymacji, który szczegółowo omawiałem poprzednio. Jeżeli uznajemy, że prawdziwy model nie istnieje i należy przez cały czas go reestymować, to lepiej aby próba testowa nie była za duża. Nie chodzi nawet o czasochłonność obliczeniową, ale o to, że po wielu obserwacjach testowych, sama specyfikacja (model teoretyczny) się zmienia. Rzecz w tym, że nawet przy ponad 500 danych dodanie jednej tylko obserwacji zmienia optymalny model. Tak więc, gdybym użył 501 danych już bym miał inne optimum, 502 jeszcze inne itd. Teoretycznie przy kolejnej reestymacji parametry dla zbędnych rzędów powinny zostać przez algorytm ustawione na zero, ale to z kolei rodzi pytanie o ustawienie maksymalnego rzędu. Przykładowo przy założeniu max 15 i przy 400 obserwacjach próby uczącej dostałem ARMA(12, 15)-EGARCH-ARCH_In_Mean dla HQC, co znaczy, że albo max rzędów jest za mały, albo próba jest za mała.
Aby zminimalizować ten problem, zwiększam próbę uczącą do 600 obserwacji (tygodniowe log-stopy zwrotu WIG20), a maksimum rzędów ARMA do 20. Natomiast wielkość próby testowej wyniesie tylko 15. Poza tym kod pozostaje ten sam. W ten sposób wg min. HQC otrzymałem:
ARMA(9, 9)-ARCH_In_Mean
HQC -4.4735
DAC (in sample) 0.6133
DAC (out of sample) 0.6000
Ciekawe, że DAC in-sample i out-of-sample są w tym modelu takie same. Może przypadek, może nie. Wykonajmy diagnostykę:
*---------------------------------*
* GARCH Model Fit *
*---------------------------------*
Conditional Variance Dynamics
-----------------------------------
GARCH Model : eGARCH(1,1)
Mean Model : ARFIMA(9,0,9)
Distribution : snorm
Optimal Parameters
------------------------------------
Estimate Std. Error t value Pr(>|t|)
mu -0.000611 0.000000 -72428.506 0
ar1 -1.017510 0.000786 -1295.050 0
ar2 0.510817 0.000964 529.650 0
ar3 0.688893 0.000020 34654.649 0
ar4 0.042736 0.000037 1150.044 0
ar5 0.031574 0.000027 1166.599 0
ar6 0.802410 0.000001 1581829.476 0
ar7 0.981174 0.000001 839176.987 0
ar8 -0.423505 0.000006 -74666.301 0
ar9 -0.723909 0.000000 -1840101.437 0
ma1 1.014618 0.000022 46381.828 0
ma2 -0.521428 0.000221 -2362.691 0
ma3 -0.732535 0.000111 -6598.699 0
ma4 -0.121873 0.000055 -2210.317 0
ma5 -0.089846 0.000052 -1728.580 0
ma6 -0.894943 0.000205 -4362.136 0
ma7 -1.067543 0.000164 -6508.449 0
ma8 0.517891 0.000070 7402.304 0
ma9 0.849641 0.000082 10319.607 0
archm 0.000132 0.000000 315.194 0
omega -1.188795 0.005020 -236.822 0
alpha1 -0.261897 0.000051 -5159.294 0
beta1 0.842014 0.000210 4006.494 0
gamma1 0.009565 0.000146 65.525 0
skew 0.741782 0.000413 1796.442 0
Robust Standard Errors:
Estimate Std. Error t value Pr(>|t|)
mu -0.000611 0.000000 -14098.715 0
ar1 -1.017510 0.000898 -1132.916 0
ar2 0.510817 0.001865 273.969 0
ar3 0.688893 0.000038 18278.881 0
ar4 0.042736 0.000151 282.800 0
ar5 0.031574 0.000111 283.606 0
ar6 0.802410 0.000003 307956.247 0
ar7 0.981174 0.000004 279684.711 0
ar8 -0.423505 0.000019 -22631.465 0
ar9 -0.723909 0.000001 -628047.744 0
ma1 1.014618 0.000123 8251.585 0
ma2 -0.521428 0.000587 -887.549 0
ma3 -0.732535 0.000303 -2414.904 0
ma4 -0.121873 0.000083 -1475.789 0
ma5 -0.089846 0.000103 -870.758 0
ma6 -0.894943 0.000507 -1766.114 0
ma7 -1.067543 0.000361 -2955.822 0
ma8 0.517891 0.000449 1154.102 0
ma9 0.849641 0.000402 2111.852 0
archm 0.000132 0.000002 80.308 0
omega -1.188795 0.020893 -56.900 0
alpha1 -0.261897 0.000597 -438.494 0
beta1 0.842014 0.000153 5495.866 0
gamma1 0.009565 0.000228 41.865 0
skew 0.741782 0.000726 1021.332 0
LogLikelihood : 1388
Information Criteria
------------------------------------
Akaike -4.5448
Bayes -4.3616
Shibata -4.5481
Hannan-Quinn -4.4735
Weighted Ljung-Box Test on Standardized Residuals
------------------------------------
statistic p-value
Lag[1] 0.6302 0.4273
Lag[2*(p+q)+(p+q)-1][53] 21.5958 1.0000
Lag[4*(p+q)+(p+q)-1][89] 43.0403 0.6430
d.o.f=18
H0 : No serial correlation
Weighted Ljung-Box Test on Standardized Squared Residuals
------------------------------------
statistic p-value
Lag[1] 0.6644 0.415008325
Lag[2*(p+q)+(p+q)-1][5] 22.9348 0.000002998
Lag[4*(p+q)+(p+q)-1][9] 25.8744 0.000005721
d.o.f=2
Weighted ARCH LM Tests
------------------------------------
Statistic Shape Scale P-Value
ARCH Lag[3] 0.2817 0.500 2.000 0.5956
ARCH Lag[5] 0.3440 1.440 1.667 0.9283
ARCH Lag[7] 0.7047 2.315 1.543 0.9563
Nyblom stability test
------------------------------------
Joint Statistic: no.parameters>20 (not available)
Individual Statistics:
mu 0.01828
ar1 0.04389
ar2 0.04270
ar3 0.02659
ar4 0.01544
ar5 0.01972
ar6 0.02274
ar7 0.01703
ar8 0.01997
ar9 0.01801
ma1 0.03099
ma2 0.03226
ma3 0.03189
ma4 0.02808
ma5 0.02623
ma6 0.01821
ma7 0.06530
ma8 0.03776
ma9 0.01859
archm 0.01796
omega 0.15436
alpha1 0.19570
beta1 0.14572
gamma1 0.05599
skew 0.14442
Asymptotic Critical Values (10% 5% 1%)
Individual Statistic: 0.35 0.47 0.75
Sign Bias Test
------------------------------------
t-value prob sig
Sign Bias 1.72190 0.08561 *
Negative Sign Bias 1.37158 0.17071
Positive Sign Bias 0.06065 0.95166
Joint Effect 4.79282 0.18761
Adjusted Pearson Goodness-of-Fit Test:
------------------------------------
group statistic p-value(g-1)
1 20 26.60 0.11432
2 30 38.30 0.11581
3 40 46.13 0.20113
4 50 62.50 0.09319
Słabo to wygląda. Test znaków i kwadratów reszt sugeruje, że model jest niewłaściwy.
I tak dochodzimy do drugiej kwestii - samej specyfikacji modelu. Jeszcze dla 300 obserwacji EGARCH(1, 1) był prawidłowy, ale 600 zmienia ten pogląd. Jest jeszcze wprawdzie możliwość, że zły rozkład, ale raczej nie o to chodzi.
Wszystko od początku
Całą analizę zacznijmy od początku. Na tych 600 danych treningowych i 15 testowych trzeba najpierw znaleźć najlepszy model ARMA (bez GARCH). Kod będzie bardzo podobny do omawianego poprzednio (wszystkie pakiety i zmienne te same), ale bez ARCH-In-Mean i użyć funkcji arfimaspec(), arfimafit(), arfimaforecast() zamiast ugarchspec(), ugarchfit(), ugarchforecast():
rozklad <- "snorm"
hqc <- list()
dacDopas <- list()
dacPrognoza <- list()
wyrzuc <- 15
wynik <- list()
# Ustawienie równoległego backendu do użycia wielu procesorów
ileRdzeni <- detectCores() - 1 # Użyj jednego mniej niż całkowita liczba rdzeni
klaster <- makeCluster(ileRdzeni)
registerDoParallel(klaster)
# Utworzenie siatki parametrów dla pętli bez k (ARCH-in-mean)
siatka_parametrow <- expand.grid(i = 0:20, j = 0:20)
# Użycie foreach do przetwarzania równoległego
wyniki <- foreach(param = 1:nrow(siatka_parametrow), .packages = c("rugarch")) %dopar% {
i <- siatka_parametrow$i[param]
j <- siatka_parametrow$j[param]
rzad_modelu <- sprintf("ARMA(%d, %d)", i, j)
tryCatch({
dopasArma <- NULL
mojArma <- arfimaspec(mean.model = list(armaOrder = c(i, j)),
distribution.model = rozklad)
dopasArma <- arfimafit(spec = mojArma, data = stopaZwrotu, out.sample = wyrzuc,
solver = "hybrid")
stopaZwrotuDopas <- fitted(dopasArma)
stopaZwrotuZgodna <- stopaZwrotuDopas + residuals(dopasArma)
prognozaArma <- arfimaforecast(dopasArma, n.ahead = 1, n.roll = wyrzuc - 1)
# Inicjalizacja wartości DAC
dacDopas_wartosc <- NA
dacPrognoza_wartosc <- NA
# Sprawdzenie ARMA(0, 0) i pominięcie DACTest jeśli prawda
if (!(i == 0 && j == 0)) {
dacDopas_wartosc <- DACTest(forecast = as.numeric(stopaZwrotuDopas),
actual = as.numeric(stopaZwrotuZgodna),
test = "PT")$DirAcc
dacPrognoza_wartosc <- as.numeric(fpm(prognozaArma)[3]) # Liczenie DAC dla prognozy
}
return(list(
rzad_modelu = rzad_modelu,
hqc = infocriteria(dopasArma)[4,],
dacDopas = dacDopas_wartosc,
dacPrognoza = dacPrognoza_wartosc
))
}, error = function(e) {
message("Błąd w ARMA(", i, ", ", j, "): ", conditionMessage(e))
return(list(error = conditionMessage(e), rzad_modelu = rzad_modelu))
})
}
# Zatrzymaj klaster po przetwarzaniu
stopCluster(klaster)
# Przetwórz wyniki i przechowaj je w oryginalnych listach
for (wynik in wyniki) {
if (!is.null(wynik)) {
for (nazwa_modelu in names(wynik)) {
hqc[[wynik$rzad_modelu]] <- wynik$hqc
dacDopas[[wynik$rzad_modelu]] <- wynik$dacDopas
dacPrognoza[[wynik$rzad_modelu]] <- wynik$dacPrognoza
}
}
}
# kryterium inf HQC
hqcDf <- as.data.frame(do.call(cbind, hqc))
colnames(hqcDf) <- names(hqc)
rownames(hqcDf) <- "HQC"
# DAC w próbie treningowej (uczącej)
dacDopasDf <- as.data.frame(do.call(cbind, dacDopas))
rownames(dacDopasDf) <- "DAC (in sample)"
# DAC w próbie testowej
dacPrognozaDf <- as.data.frame(do.call(cbind, dacPrognoza))
rownames(dacPrognozaDf) <- "DAC (out of sample)"
porownanie <- bind_rows(hqcDf, dacDopasDf, dacPrognozaDf)
kryterium_hqc <- porownanie[, which.min(porownanie[1, ]), drop=F]
kryterium_dacDopas <- porownanie[, which.max(porownanie[2, ]), drop=F]
kryterium_dacPrognoza <- porownanie[, which.max(porownanie[3, ]), drop=F]
# Znajdź wszystkie kolumny z minimalną wartością w pierwszym wierszu (HQC)
min_hqc <- min(round(porownanie[1, ], 4), na.rm = TRUE)
kryterium_hqc <- porownanie[, which(round(porownanie[1, ], 4) == min_hqc), drop = FALSE]
# Znajdź wszystkie kolumny z maksymalną wartością w drugim wierszu (DAC w próbie treningowej)
max_dacDopas <- max(round(porownanie[2, ], 4), na.rm = TRUE)
kryterium_dacDopas <- porownanie[, which(round(porownanie[2, ], 4) == max_dacDopas), drop = FALSE]
# Znajdź wszystkie kolumny z maksymalną wartością w trzecim wierszu (DAC w próbie testowej)
max_dacPrognoza <- max(round(porownanie[3, ], 4), na.rm = TRUE)
kryterium_dacPrognoza <- porownanie[, which(round(porownanie[3, ], 4) == max_dacPrognoza), drop = FALSE]
kryterium_hqc
kryterium_dacDopas
kryterium_dacPrognoza
Dostałem:
> kryterium_hqc
ARMA(7, 11)
HQC -4.3222
DAC (in sample) 0.6017
DAC (out of sample) 0.8667
> kryterium_dacDopas
ARMA(16, 11)
HQC -4.2633
DAC (in sample) 0.6283
DAC (out of sample) 0.6000
> kryterium_dacPrognoza
ARMA(6, 4) ARMA(6, 18)
HQC -4.2574 -4.264
DAC (in sample) 0.5417 0.570
DAC (out of sample) 1.0000 1.000
Dalej wyciągamy optymalne rzędy:
# parametry - HQC
wyciagnij_liczby <- function(wyr, x) {
as.numeric(gsub("[^0-9]", "", substr(wyr, x, x+2), ))
}
rzadAR_hqc <- wyciagnij_liczby(colnames(kryterium_hqc), 6)
rzadMA_hqc <- wyciagnij_liczby(colnames(kryterium_hqc), 9)
# parametry - DAC out of sample
rzadAR_DAC <- wyciagnij_liczby(colnames(kryterium_dacPrognoza), 6)[2]
rzadMA_DAC <- wyciagnij_liczby(colnames(kryterium_dacPrognoza), 9)[2]
Wykonajmy diagnostykę, analogicznie jak poprzednio wg HQC:
dopasArma_hqc <- arfimafit(spec = mojArma_hqc, data = stopaZwrotu, out.sample = wyrzuc, solver="hybrid")
dopasArma_hqc
> dopasArma_hqc
*----------------------------------*
* ARFIMA Model Fit *
*----------------------------------*
Mean Model : ARFIMA(7,0,11)
Distribution : snorm
Optimal Parameters
------------------------------------
Estimate Std. Error t value Pr(>|t|)
mu -0.000163 0.000001 -118.88 0
ar1 1.708939 0.000055 31171.71 0
ar2 -1.589454 0.000048 -33434.75 0
ar3 0.941900 0.000042 22383.28 0
ar4 -1.292676 0.000001 -1403760.91 0
ar5 1.688498 0.000060 28287.27 0
ar6 -1.389024 0.000042 -32791.53 0
ar7 0.337973 0.000043 7801.90 0
ma1 -1.803387 0.000060 -29855.67 0
ma2 1.876807 0.000059 31845.44 0
ma3 -1.393470 0.000044 -31363.61 0
ma4 1.874833 0.000068 27413.36 0
ma5 -2.382959 0.000069 -34491.56 0
ma6 2.152583 0.000074 29113.30 0
ma7 -1.013392 0.000043 -23773.12 0
ma8 0.566727 0.000027 20790.58 0
ma9 -0.357758 0.000017 -20796.19 0
ma10 0.187237 0.000010 18174.45 0
ma11 -0.066118 0.000014 -4891.35 0
sigma 0.026299 0.000060 439.52 0
skew 0.803218 0.001613 498.00 0
Robust Standard Errors:
Estimate Std. Error t value Pr(>|t|)
mu -0.000163 0.000001 -245.88 0
ar1 1.708939 0.000100 17094.56 0
ar2 -1.589454 0.000060 -26331.39 0
ar3 0.941900 0.000053 17769.70 0
ar4 -1.292676 0.000004 -321135.66 0
ar5 1.688498 0.000068 24959.04 0
ar6 -1.389024 0.000018 -75620.19 0
ar7 0.337973 0.000035 9540.15 0
ma1 -1.803387 0.000209 -8649.06 0
ma2 1.876807 0.000157 11965.81 0
ma3 -1.393470 0.000031 -45389.79 0
ma4 1.874833 0.000165 11333.48 0
ma5 -2.382959 0.000120 -19852.77 0
ma6 2.152583 0.000209 10290.45 0
ma7 -1.013392 0.000129 -7881.81 0
ma8 0.566727 0.000037 15484.79 0
ma9 -0.357758 0.000041 -8716.28 0
ma10 0.187237 0.000009 19894.66 0
ma11 -0.066118 0.000021 -3178.62 0
sigma 0.026299 0.000071 371.02 0
skew 0.803218 0.000424 1892.55 0
LogLikelihood : 1336
Information Criteria
------------------------------------
Akaike -4.3821
Bayes -4.2282
Shibata -4.3844
Hannan-Quinn -4.3222
Weighted Ljung-Box Test on Standardized Residuals
------------------------------------
statistic p-value
Lag[1] 1.659 0.19768
Lag[2*(p+q)+(p+q)-1][53] 35.169 0.00000
Lag[4*(p+q)+(p+q)-1][89] 54.654 0.03086
H0 : No serial correlation
Weighted Ljung-Box Test on Standardized Squared Residuals
------------------------------------
statistic p-value
Lag[1] 1.762 0.1844147994362065335
Lag[2*(p+q)+(p+q)-1][2] 35.427 0.0000000004027803646
Lag[4*(p+q)+(p+q)-1][5] 57.765 0.0000000000000003331
ARCH LM Tests
------------------------------------
Statistic DoF P-Value
ARCH Lag[2] 67.45 2 0.00000000000000222
ARCH Lag[5] 67.76 5 0.00000000000029932
ARCH Lag[10] 70.05 10 0.00000000004330802
Nyblom stability test
------------------------------------
Joint Statistic: no.parameters>20 (not available)
Individual Statistics:
mu 0.05184
ar1 0.08997
ar2 0.06947
ar3 0.05230
ar4 0.02741
ar5 0.04652
ar6 0.07092
ar7 0.08179
ma1 0.09581
ma2 0.07342
ma3 0.05758
ma4 0.03403
ma5 0.03789
ma6 0.04300
ma7 0.07302
ma8 0.10824
ma9 0.07579
ma10 0.04847
ma11 0.03839
sigma 0.66621
skew 0.02743
Asymptotic Critical Values (10% 5% 1%)
Individual Statistic: 0.35 0.47 0.75
I co się okazuje? Że występuje jednak efekt ARCH. Sama ARMA jest niedopuszczalna.
Sprawdźmy jeszcze model wg kryterium DAC w próbie testowej:
> dopasArma_DAC
*----------------------------------*
* ARFIMA Model Fit *
*----------------------------------*
Mean Model : ARFIMA(6,0,18)
Distribution : snorm
Optimal Parameters
------------------------------------
Estimate Std. Error t value Pr(>|t|)
mu -0.000484 0.000003 -181.01 0
ar1 1.652690 0.000052 31715.16 0
ar2 -0.569904 0.000021 -26571.17 0
ar3 -0.691440 0.000024 -29358.26 0
ar4 -0.370370 0.000016 -23705.84 0
ar5 1.335052 0.000028 46954.51 0
ar6 -0.810241 0.000022 -36509.08 0
ma1 -1.807455 0.000065 -27683.56 0
ma2 0.896344 0.000043 20628.63 0
ma3 0.479002 0.000017 28772.19 0
ma4 0.307185 0.000013 23760.96 0
ma5 -1.300847 0.000056 -23158.98 0
ma6 0.999150 0.000045 22099.33 0
ma7 -0.255216 0.000013 -19665.03 0
ma8 0.146197 0.000009 15602.83 0
ma9 0.010041 0.000005 1948.42 0
ma10 -0.192279 0.000009 -20638.50 0
ma11 0.181860 0.000009 19169.60 0
ma12 -0.126310 0.000007 -19332.60 0
ma13 0.129111 0.000008 15919.81 0
ma14 -0.135228 0.000010 -13197.50 0
ma15 0.080054 0.000005 16270.07 0
ma16 -0.257084 0.000014 -19028.90 0
ma17 0.334883 0.000013 24885.88 0
ma18 -0.170361 0.000002 -78823.90 0
sigma 0.026828 0.000039 684.76 0
skew 0.736525 0.000896 822.24 0
Robust Standard Errors:
Estimate Std. Error t value Pr(>|t|)
mu -0.000484 0.000005 -88.585 0
ar1 1.652690 0.000225 7358.377 0
ar2 -0.569904 0.000030 -18787.065 0
ar3 -0.691440 0.000020 -33985.665 0
ar4 -0.370370 0.000007 -53955.284 0
ar5 1.335052 0.000061 22010.081 0
ar6 -0.810241 0.000078 -10327.488 0
ma1 -1.807455 0.000418 -4325.866 0
ma2 0.896344 0.000228 3928.523 0
ma3 0.479002 0.000019 25779.508 0
ma4 0.307185 0.000031 10005.522 0
ma5 -1.300847 0.000312 -4166.365 0
ma6 0.999150 0.000079 12603.512 0
ma7 -0.255216 0.000037 -6950.382 0
ma8 0.146197 0.000019 7556.457 0
ma9 0.010041 0.000026 388.235 0
ma10 -0.192279 0.000006 -33015.132 0
ma11 0.181860 0.000014 12830.990 0
ma12 -0.126310 0.000003 -39589.998 0
ma13 0.129111 0.000016 8046.554 0
ma14 -0.135228 0.000022 -6183.826 0
ma15 0.080054 0.000032 2482.382 0
ma16 -0.257084 0.000028 -9035.050 0
ma17 0.334883 0.000027 12423.452 0
ma18 -0.170361 0.000007 -26122.951 0
sigma 0.026828 0.000057 474.242 0
skew 0.736525 0.003314 222.255 0
LogLikelihood : 1329
Information Criteria
------------------------------------
Akaike -4.3406
Bayes -4.1427
Shibata -4.3444
Hannan-Quinn -4.2636
Weighted Ljung-Box Test on Standardized Residuals
------------------------------------
statistic p-value
Lag[1] 5.469 0.01936
Lag[2*(p+q)+(p+q)-1][71] 35.802 0.63160
Lag[4*(p+q)+(p+q)-1][119] 62.706 0.30838
H0 : No serial correlation
Weighted Ljung-Box Test on Standardized Squared Residuals
------------------------------------
statistic p-value
Lag[1] 0.6252 0.429113495341529
Lag[2*(p+q)+(p+q)-1][2] 28.6335 0.000000024213054
Lag[4*(p+q)+(p+q)-1][5] 45.7761 0.000000000001031
ARCH LM Tests
------------------------------------
Statistic DoF P-Value
ARCH Lag[2] 55.77 2 0.000000000000775
ARCH Lag[5] 57.73 5 0.000000000035680
ARCH Lag[10] 58.90 10 0.000000005842875
Nyblom stability test
------------------------------------
Joint Statistic: no.parameters>20 (not available)
Individual Statistics:
mu 0.07987
ar1 0.12280
ar2 0.10719
ar3 0.05115
ar4 0.04223
ar5 0.07941
ar6 0.11593
ma1 0.11203
ma2 0.06554
ma3 0.03642
ma4 0.07160
ma5 0.11188
ma6 0.12608
ma7 0.10324
ma8 0.05420
ma9 0.03809
ma10 0.07410
ma11 0.11379
ma12 0.12568
ma13 0.09919
ma14 0.05052
ma15 0.03972
ma16 0.07790
ma17 0.11582
ma18 0.12465
sigma 0.63364
skew 0.06743
Asymptotic Critical Values (10% 5% 1%)
Individual Statistic: 0.35 0.47 0.75
To samo - mamy tu do czynienia z efektami ARCH. Aby model poprawnie działał, musimy je uwzględnić.
Wiemy już na pewno, że sama ARMA jest błędna. Dochodzimy do wniosku, że musi być to jakiś model GARCH, ale nie EGARCH. Sprawdziłem więc standardowy GARCH(1,1) oznaczany "sGARCH" - ale także okazał się niewłaściwy. Trzeba szukać dalej. Wiadomo tylko, że rzędy części GARCH (1, 1) są prawidłowe, bo gdyby nie były, to w resztach pojawiłyby się efekty ARCH nie uwzględnione przez model - a ich nie było w EGARCH (ani w sGARCH jak sprawdzałem).
Przychodzą mi dwie możliwości, które trzeba po kolei sprawdzić. Po pierwsze może być to inny model, jak TGARCH, APARCH, GJR-GARCH, NGARCH, NAGARCH, iGARCH i csGARCH. Po drugie EGARCH może być prawidłowy, ale może występować jakaś niestabilność czy zmiana struktury wariancji, której test Nybloma nie uwzględnił. Stąd może być potrzebny zupełnie inny model albo bardziej zaawansowany GARCH, jak np. TV-GARCH (time-varying GARCH), którego nie ma obecnie w rugarch.
Jak dotąd sprawdziłem we wszystkich konfiguracjach sGARCH, TGARCH, GJR-GARCH, IGARCH i APARCH. Mimo użycia przetwarzania równoległego poszukiwanie optimum dla każdego zajmuje wiele godzin. Okazało się, że żaden model wcale nie był lepszy od EGARCH. Sprawdziłem dodatkowo - ale już bez ARMA - wiele modeli z GARCH innych rzędów, czyli GARCH(1, 2), GARCH(2, 1), GARCH(2, 2). Sprawdzałem pod tym kątem też NGARCH i NAGARCH. Nic to nie dało.
Jedną z potencjalnych przyczyn trudności modelowania warunkowej wariancji, jest zmienność jej parametrów w czasie. Test Nybloma w rugarch nie wykryje tej zmienności, jeśli zmiana nie będzie systematyczna, ale za to będzie systematycznie zanikać w czasie. Moglibyśmy użyć innych testów. Dotychczas sprawdzałem zmienność wariancji przy pomocy testu Goldfelda-Quandta, Breuscha-Pagana, Harrisona-McCabe (zob. tu) oraz CUSUM (tu i tu). Niektóre z tych testów mogą jednak pomylić warunkową heteroskedastyczność z niestabilnością wariancji niewarunkowej.
TV-GARCH
Rozwiązaniem problemu jest pakiet tvgarch, służący do symulacji, estymacji i analizy procesu TV-GARCH (Time Varying GARCH). Pakiet zawiera funkcję tvgarchTest(), która testuje proces TV-GARCH(1,1). Instalujemy i ładujemy pakiet:
if (require("tvgarch")==FALSE) {
install.packages("tvgarch")
}
library("tvgarch")
Najpierw przeprowadzimy kilka symulacji sGARCH i eGarch z rozkładem skośno-normalnym i wykonamy test:
set.seed(30)
sym <- ugarchspec(variance.model = list(model = "sGARCH", garchOrder = c(1, 1)), mean.model = list(armaOrder = c(1, 1)),
distribution.model = "snorm", fixed.pars = list(omega = 0.5,
alpha1 = 0.6,
beta1 = 0.3,
mu = 0.01,
ar1 = 0.6,
ma1 = 0.2,
skew = 0.7))
symGarch <- ugarchpath(sym, n.sim = 600)
symGarch <- symGarch@path$seriesSim
ts.plot(symGarch)
I włączamy funkcję:
tvGarchTest <- tvgarchTest(y = as.numeric(symGarch))
tvGarchTest
Efekt:
Testing GARCH(1,1), i.e., the model under H0, against
TV-GARCH(1,1), i.e., the model under H1:
Estimation results for model under H0:
Model: GARCH(1,1)
intercept.h arch1 garch1
Estimate: 0.5632 0.8630 0.28048
Std. Error: 0.1232 0.1134 0.04657
Log-likelihood: -1309
Transition variable in TV-GARCH(1,1): time
Results from the Non-Robust TR^2 Test:
NonRobTR2 p-value
H0:B3=B2=B1=0 3.7317 0.2919
H03:B3=0 0.7273 0.3937
H02:B2=0|B3=0 2.2520 0.1334
H01:B1=0|B3=B2=0 0.7589 0.3837
Results from the Robust TR^2 Test:
RobTR2 p-value
H0:B3=B2=B1=0 6.268 0.0993
H03:B3=0 1.393 0.2378
H02:B2=0|B3=0 2.195 0.1385
H01:B1=0|B3=B2=0 2.694 0.1007
Single
No. of locations (alpha = 0.05) 0
Są tu dwie wersje testu: nieodporny (non-robust) i odporny (robust), podobnie jak to było w rugarch. Odporność należy tu rozumieć jako odporność na odchylenia od założonego rozkładu (tu normalnego). Ponieważ nasze reszty modelu nie mają rozkładu normalnego, to ten odporny będzie ważniejszy - więc tylko na niego patrzymy. Dzięki temu odróżnieniu możemy ocenić czy błędy odchyleń zachowują się gaussowsko. Parametr B1 można interpretować jako średnią warunkową wariancji niewarunkowej. Parametr B2 - jako wariancję warunkową wariancji niewarunkowej. Parametr B3 - jako skośność warunkową wariancji niewarunkowej. Najważniejsza jest pierwsza hipoteza. Ponieważ wskazuje p-value > 0,05 , to znaczy, że nie ma podstaw do odrzucenia hipotezy stałego GARCH. Tak też wskazuje ostatnia statystyka No. of locations = 0 liczbę punktów przejść z jednego modelu do drugiego.
Dla set.seed(1100)
Dostałem podobne statystyki.
Teraz symulacja EGARCH(1, 1):
sym <- ugarchspec(variance.model = list(model = "eGARCH", garchOrder = c(1, 1)), mean.model = list(armaOrder = c(1, 1)),
distribution.model = "snorm", fixed.pars = list(omega = 0.5,
alpha1 = 0.6,
beta1 = 0.3,
mu = 0.01,
ar1 = 0.6,
ma1 = 0.2,
gamma1 = 0.8,
skew = 0.7))
set.seed(1100)
symGarch <- ugarchpath(sym, n.sim = 600)
symGarch <- symGarch@path$seriesSim
ts.plot(symGarch)
Tak samo test odrzucił tu TV-GARCH.
To teraz nasze (logarytmiczne) stopy zwrotu WIG20
plot(stopaZwrotu)
tvGarchTest <- tvgarchTest(y = as.numeric(stopaZwrotu))
tvGarchTest
Testing GARCH(1,1), i.e., the model under H0, against
TV-GARCH(1,1), i.e., the model under H1:
Estimation results for model under H0:
Model: GARCH(1,1)
intercept.h arch1 garch1
Estimate: 0.0001704 0.15324 0.63531
Std. Error: 0.0003021 0.09059 0.05965
Log-likelihood: 1346
Transition variable in TV-GARCH(1,1): time
Results from the Non-Robust TR^2 Test:
NonRobTR2 p-value
H0:B3=B2=B1=0 5.7505 0.1244
H03:B3=0 3.7567 0.0526
H02:B2=0|B3=0 0.0233 0.8787
H01:B1=0|B3=B2=0 1.9829 0.1591
Results from the Robust TR^2 Test:
RobTR2 p-value
H0:B3=B2=B1=0 10.2591 0.0165
H03:B3=0 3.5790 0.0585
H02:B2=0|B3=0 0.0203 0.8867
H01:B1=0|B3=B2=0 6.4987 0.0108
Single
No. of locations (alpha = 0.05) 1
Test rzeczywiście odrzuca stabilność wariancji niewarunkowej. Towarzyszy temu niskie p-value. Jednocześnie wyłapał 1 punkt zmiany struktury modelu wariancji. Dostajemy dowód, że albo należy posługiwać się mniejszą próbą, albo właśnie TV-GARCH.
Chociaż jest jeszcze jedna możliwość - nawet bardziej naturalna. Można użyć nieparametrycznego GARCH, analogicznie do regresji nieparametrycznej. Skoro to takie naturalne, to po co w ogóle parametryczne modele? Głównie z powodu dostępności i tak jak w przypadku rugarch z całą paletą diagnostyczną. Drugim powodem jest to, że powinny być one zawsze punktem wyjścia - bo przecież mogą się okazać lepsze od wersji nieparametrycznej. Poza tym używanie skomplikowanych metod bez zrozumienia podstaw jest bez sensu.