Załóżmy dla uproszczenia, że stopy zwrotu z jakichś aktywów, np. funduszy akcji, mają rozkład normalny i nie są skorelowane w czasie. Dalej zastanawiamy się, w który fundusz zainwestować. Ponieważ rozkład jest gaussowski, są tylko dwa parametry do analizy: średnia i wariancja. Im większa średnia stopa zwrotu, tym lepiej oraz im mniejsza wariancja (i jej pierwiastek, czyli odchylenie std) tym lepiej. W sumie wystarczy użyć współczynnika Sharpe'a będącego w najprostszym ujęciu ilorazem średniej stopy zwrotu do odchylenia standardowego. Wydawałoby się więc, że wystarczy wyciągnąć stopy zwrotu z kilku ostatnich lat, np. z notowań mbanku lub stooq.pl, obliczyć wskaźnik Sharpe'a i wybrać fundusz o najlepszym wyniku. Jednak takie proste podejście jest niepoważne z naukowego punktu widzenia. Przykładowo, jak można traktować poważnie taką metodę, skoro przyjmujemy za pewnik, że średnia stopa zwrotu pozostaje stabilna w czasie? Niektórzy autorzy uzasadniają użycie stałych parametrów, odwołując się do ekonofizyki: M. Dobija i D. Dobija [1] stwierdzają, że premia za ryzyko jest wielkością wynikającą z praw natury, a przez to stabilną, wynoszącą średnio ok. 8% rocznie (w zależności od sposobu liczenia może wynieść nieco więcej). Chociaż analogie do fizyki są bardzo kuszące, to mimo wszystko nie muszą one odzwierciedlać w pełni rzeczywistości, bo nie wywodzą się z dedukcji ekonomicznej. Teoria CAPM wprost mówi, że im większe ryzyko rynkowe, tym większa premia za ryzyko. Owe 8% może istotnie dotyczyć pewnej średniej, czyli np. portfela rynkowego (bo wraz z premią za czas równą ok. 3% koszt kapitału wyniesie 11%), ale fundusze akcji budują własne portfele. W dynamice giełdowej fundusze zmieniają skład portfela, a wtedy też mogą zmieniać się ich zyski.
Dochodzimy do wniosku, że potrzebne są nam narzędzia do oceny stabilności parametrów rozkładu stopy zwrotu. Z czego można więc skorzystać na szybko?
Test t
Jest to tak standardowe narzędzie, że znajdziemy je w każdej wersji Excela. Na dodatek testu t możemy użyć na dwa sposoby: poprzez formułę (T.TEST) lub poprzez specjalną opcję przeznaczoną do analizowania danych statystycznych (dodatek Analiza danych, w ang. Analysis Toolpak). Użyjemy formuły.
Jest kilka rodzajów testu t. Wg pomocy Excela wszystkie one stanowią test t-Studenta, choć trzeba wiedzieć, że oryginalny test t-Studenta dotyczy sytuacji, gdy wariancje w obu porównywanych próbach są równe. Gdy wariancje nie są równe, stosuje się tzw. test Welcha. W Excelu nazwa nie ma znaczenia. Generalnie, zasada jest taka, że dla zmiennych ekonomicznych lub giełdowych zawsze stosujemy test Welcha. Nawet jeśli wariancja jest taka sama, to test Welcha też będzie dobrze działać. Niektórzy autorzy uważają, że w ogóle zamiast testu Studenta należy stosować test Welcha, ponieważ jego moc jest zbliżona do tego pierwszego, gdy wariancje są jednorodne [2].
Czyli mamy dwie próby A i B. Nie jest konieczne, żeby miały taką samą liczebność, chociaż sami czujemy, że żeby prawidłowo porównać dwie próby, to jednak liczba danych powinna być w miarę podobna, jeśli oczywiście to możliwe.
Formuła jest banalnie prosta:
=T.TEST(A; B; 2; 3)
Nazwa może być myląca, bo nie zwraca ona wartości statystyki t, tylko prawdopodobieństwo, że średnie są równe. Trzeci argument wynosi 2, bo chcemy sprawdzić zachowanie ogonów rozkładu z dwóch stron - dodatniej i ujemnej. Tak naprawdę ten argument mógłby w ogóle nie występować, bo ze względu na założenie symetryczności, zawsze ogon jednej strony będzie równy połowie dwóch ogonów w sensie prawdopodobieństwa - więc samemu można sobie już podzielić na dwa czy podwoić.
Istotny jest natomiast czwarty argument - typ testu. Będzie równy 1 dla testu sparowanego, tzn. gdy pozycja każdego elementu w jednej próbie ma znaczenie dla elementu o tej samej pozycji w drugiej próbie. To znaczy, każdy element w jednej próbie jest sparowany z elementem na takiej samej pozycji w drugiej próbie. Przykładowo mamy grupę pacjentów A. Każdy pacjent ma jakiś wynik bez stosowania leku. Następnie stosujemy na każdym pacjencie lek. Jest oczywiste, że kolejność pacjentów w grupie A ma znaczenie, jeśli chcemy porównać ich wyniki po użyciu leku. Dlatego, tworząc grupę B pacjentów, którzy przyjmą lek, musimy mieć pewność, że dany pacjent ma tę samą pozycję w obu grupach. Wynik w jednej grupie może się różnić w drugiej grupie, ale czy statystycznie wyniki będą różne? Zauważmy, że nawet jeśli dla kilku pacjentów lek będzie działał doskonale, ale dla reszty nie przyniesie żadnej poprawy, to badacz musi uznać, że lek nie działa. Widać więc, że ważne jest, aby grupa pacjentów była reprezentatywna w badaniach i samo grupowanie ma duże znaczenie. W ekonomii użycie sparowanego testu w niektórych sytuacjach ma sens, jak choćby porównanie zmian PKB okres do okresu. W przypadku stóp zwrotu na rynkach nie ma to już znaczenia.
Jeżeli dane nie muszą być sparowane, a wariancja w obydwu próbach jest równa, czyli zmienna jest homoskedastyczna, to typ będzie równy 2.
W końcu, jeśli wariancje w obu próbach się różnią (zmienna jest heteroskedastyczna), to dajemy 3. To jest właśnie test Welcha.
Jak wygenerować losowe obserwacje pochodzące z rozkładu normalnego?
Aby sprawdzić jak test działa, możemy wygenerować dwie próby o rozkładzie normalnym. W polskiej wersji używamy formuły ROZKŁAD.NORMALNY.ODW (w ang. wersji NORMINV) - tj. rozkład normalny odwrócony, czyli po prostu nasza zmienna o rozkładzie normalnym (formuła ROZKŁAD.NORMALNY, w ang. NORMDIST, zwraca prawdopodobieństwo tej zmiennej). Formuła zawiera 3 argumenty: prawdopodobieństwo zwracanej wartości, średnia oraz odchylenie std. Powiedzmy, że chcemy wygenerować 50 danych. Dwa ostatnie są oczywiste - założymy średnią równą 0 i odch. std 1, Gorzej z pierwszym argumentem. Przede wszystkim należy wiedzieć, że zwracana wartość pochodzi z rozkładu skumulowanego (dystrybuanty), a nie gęstości. To z kolei umożliwia zastosowanie pewnej sztuczki: za prawdopodobieństwo wstawiamy formułę LOS(), w ang. RAND(). Generuje ona wartość losową z przedziału od 0 do 1, ale - uwaga - z rozkładu jednostajnego. Czyli nasza formuła ma postać:
=ROZKŁAD.NORMALNY.ODW(LOS(); 0; 1)
Formułę tę kopiujemy 50 razy i za każdym razem uzyskamy nowy wynik, który będzie pochodził już z rozkładu normalnego.
-----------------------------------------------------------------------------------------
Dla zainteresowanych: jak działa ta formuła? Intuicyjnie wydawałoby się, że powinna ona przynieść zmienną także z rozkładu jednostajnego: przecież dystrybuanta to jest funkcja rosnąca, a więc każdej wylosowanej obserwacji z przedziału od 0 do 1 przyporządkowujemy zawsze jedną liczbę. Skoro zmienna niezależna pochodzi z rozkładu jednostajnego, to jak to się dzieje, że przekształca się w rozkład normalny? Problem leży w istnieniu dodatkowych warunków, jak średnia i wariancja, a szczególnie chodzi tu o wariancję. W art. Od zasady maksymalnej entropii do regresji logistycznej pokazałem, że maksymalizacja entropii Shannona bez dodatkowych warunków prowadzi do rozkładu jednostajnego. Po dodaniu warunku średniej, otrzymamy rozkład logistyczny. Gdyby jeszcze tam dodać warunek wariancji, dostalibyśmy rozkład normalny.
To jednak wyjaśnienie jest bardziej pośrednie, bo nie dotyczy samej odwrotnej dystrybuanty (kumulanty). Gdyby bezpośrednio to wyjaśnić, to trzeba odwołać się do jej własności. Jedną z nich jest fakt taki, że jeśli zmienna p ma rozkład jednostajny od 0 do 1, to zmienna 1/F(p) posiada dystrybuantę F (zob. art. w Wikipedii). Własność tę wykorzystują różne generatory liczb losowych. W szczególności dla rozkładu normalnego będzie to transformacja Boxa-Mullera.
-----------------------------------------------------------------------------------------
Generujemy więc dwie losowe próby, A i B, po 50 danych za pomocą przedstawionej formuły:
=T.TEST(A; B; 2; 2) lub
=T.TEST(A; B; 2; 3)
Nie tu ma większego znaczenia którą wybierzemy. Klawiszem F9 będziemy zmieniać wylosowane wartości. Zauważymy, że niemal zawsze wartość testu da wartość powyżej 0,05. To znaczy, że hipotezy zerowej mówiącej, że średnie są równe, nie powinniśmy odrzucać. Czyli test działa prawidłowo.
W kolejnym kroku próbę B nieco zmieniamy: podwyższamy średnią do 0,2. Czyli tworzymy formułę =ROZKŁAD.NORMALNY.ODW(LOS(); 0,2; 1).
Patrzymy na test t. Co się okaże? Najczęściej dostaniemy wartość testu powyżej 0,05, a to znaczy, że test źle działa. Wiemy przecież, że pierwsza próba ma ciągle średnią 0, a druga 0,2, więc powinniśmy odrzucić hipotezę zerową. Różnica 0,2 okazuje się po prostu za mała. Zwiększmy średnią B do 0,5. Tym razem test radzi sobie lepiej, bo najczęściej daje wartości poniżej 0,05, choć nadal ma czasem problemy. Zwiększmy więc średnią do 0,7. Tym razem niemal zawsze dostaniemy wartości testu poniżej 0,05, czyli odrzucamy hipotezę zerową, że średnie są równe. Dostaliśmy wynik prawidłowy.
Czyli już widzimy, że przy 50 danych różnica między średnimi nie może być minimalna, aby test dawał wiarygodne wyniki. Ale sytuacja jeszcze się pogorszy, gdy zwiększymy odchylenie std w B. Powiedzmy, że zwiększamy je dwukrotnie, tak że dostaniemy formułę =ROZKŁAD.NORMALNY.ODW(LOS(); 0,7; 2). Wtedy już stosujemy tylko test Welcha:
=T.TEST(A; B; 2; 3).
Okazuje się, że test działa słabo dla 50 danych. Dopiero po zwiększeniu liczebności obu prób do 100, statystyka testu wygląda lepiej: błędów dużo mniej.
Chociaż Excel nadaje się do robienia podstawowych i niezbyt złożonych operacji statystycznych, to jeżeli chcemy zrobić coś więcej, musimy ściągnąć jakieś dodatki albo samemu stworzyć formułę lub makro. Mimo wszystko najlepiej chyba posłużyć się specjalistycznym oprogramowaniem.
Test Chowa
Kiedyś poruszyłem temat stabilności modelu ekonometrycznego. Jednym z nich był test Chowa, który nieco przypomina test t-Studenta z tego powodu, że także porównuje dwie próby. Różnica polega na tym, że test Chowa bada stabilność wszystkich parametrów w regresji liniowej zbudowanej na podstawie połączonych obu prób. Można by pomyśleć, że jeśli w regresji ustalimy zerowe nachylenie, to powinniśmy dostać te same rezultaty dla Chowa co dla t. Jednak tak nie jest, bo test t porównuje różnicę między jedną średnią a drugą, natomiast test Chowa (inaczej test F) stosunek średniej z sumy połączonych próbek do średniej pierwszej próby. Okazuje się jednak, że w jednym przypadku oba testy dają praktycznie te same rezultaty w sensie prawdopodobieństwa błędu (p), a dzieje się to w sytuacji najczęściej stosowanym, czyli gdy obie próbki mają taką samą liczebność (tj. w przypadku Chowa potencjalna zmiana średniej następuje w połowie badanego zakresu).
Tym razem użyję języka R do testu Chowa. W zasadzie to od R w ogóle mógłbym zacząć i nie bawić się z Excelem, ale z drugiej strony Excela zna każdy, więc łatwiej w ten sposób znaleźć punkt zaczepienia. Chociaż nie jest to konieczne, to polecane jest stosowanie R-Studio. I jeszcze nota dot. Gretla. Możemy także go użyć do analiz, chociaż R jest bardziej wszechstronny, dlatego od teraz na nim się skupię. Gretl ma w tym temacie tylko jedną przewagę: analiza zmian strukturalnych modelu jest już w programie zainstalowana, a w R musimy sami zainstalować pakiet. Dodatkową niedogodnością w R jest wymóg jeszcze załadowania pakietu.
W konsoli albo skrypcie wpisujemy komendę install.packages(strucchange) lub install.packages("strucchange") i zatwierdzamy ENTER. W R-Studio można też wybrać Tools -> Install packages -> wpisujemy nazwę strucchange.
Sporą niedogodnością, być może w przyszłości rozwiązaną, jest to, że aby użyć danego pakietu, musimy użyć aż trzech komend. Pierwsze to właśnie instalacja, drugie to załadowanie pakietu przez komendę library(strucchange) lub library("strucchange"). Tu jeszcze mała uwaga. Ponieważ będę na blogu używał potem różnych pakietów do R, warto od razu mieć kod sprawdzający czy dany pakiet jest zainstalowany i jeśli nie, to należy go zainstalować. Następnie włączyć. W sumie początkowy kod byłby następujący:
#jeżeli to wymagane, instalacja pakietu (tu strucchange) i włączenie go
if (require(strucchange)==FALSE) {
install.packages(strucchange)
library(strucchange)
}
Trzecią komendą będzie użycie samego pakietu. Ponieważ składa się on z wielu funkcji, nie przywołujemy już samego strucchange, który jest klasą funkcji, ale funkcję, np. sctest(x, ...) , gdzie x to jakiś obiekt. Na tej stronie znajdziemy odnośniki do dokumentacji w formacie pdf. Samemu ciężko się przebić przez to wszystko, więc trzeba po kolei zacząć od prostych komend.
Podobnie jak w Excelu musimy najpierw stworzyć dwie próby do testowania. Każda ma mieć 50 danych o rozkładzie normalnym. Służy do tego funkcja rnorm().
(1) Średnia 0 i odch std 1. W skrypcie wpisujemy kod:
n1 = 50
n2 = 50
sim1 = rnorm(n1, 0, 1)
sim2 = rnorm(n2, 0, 1)
gdzie n1 i n2 to liczebność próbek, sim1 i sim2 to nazwane zmienne symulujące rozkład Gaussa.
Musimy teraz połączyć obie próbki. Najprostsze to użycie funkcji c:
sim12 = c(sim1,sim2)
gdzie sim12 to połączenie próbki 1 i 2 w jedną.
W końcu wykonujemy test Chowa. To właśnie teraz przywołujemy funkcję sctest:
sctest(sim12 ~ 1, type="Chow", point=n1)
Falka oznacza tworzenie regresji. Chociaż jest zrozumiałe, dlaczego jest ona użyta (notacja matematyczna), to jej wpisanie na klawiaturze nie jest zbyt wygodne (shift+tylda+spacja). W każdym razie sim12 to zmienna zależna, a sama cyfra 1 po tyldzie oznacza po prostu, że tworzymy regresję liniową bez nachylenia, jedynie ze stałą, której parametr chcemy wyznaczyć. Formuła sctest umożliwia analizę pod różnym kątem i jednym z nim z nich jest test Chowa, stąd type = "Chow". Ostatni element wprost nawiązuje do tego testu, bo wymaga wprowadzenia punktu, w którym sprawdzamy zmianę struktury modelu. Chcemy sprawdzić czy dzieje się to w połowie próby, więc będzie to n1 lub n1 + 1.
Wykonujemy kod. W R-Studio za pomocą CTRL+ENTER albo klikamy Run w oknie skryptu.
Hipoteza zerowa to brak zmiany struktury. Wobec tego gdy p > 0,05 lub jeśli mamy niewielką próbę, to gdy p > 0,1, uznajemy, że brak podstaw do odrzucenia hipotezy. Kod wykonujemy wielokrotnie. Test działa prawidłowo - praktycznie za każdym razem dostaniemy p > 0,05.
(2) Średnia powyżej 0 i odch std 1.
Zmieńmy więc średnią drugiej próby, sim2, na 0,2. Tzn. sim2 = rnorm(n1, 0.2, 1)
Tym razem p najczęściej znajduje się powyżej 0,1, co wskazywałoby błędnie na niezmienność średniej. Przy 50 danych zmiana średniej o 0,2 jest po prostu za niska. Podnieśmy ją do 0,5: sim2 = rnorm(n1, 0.5, 1).
Po wielokrotnym użyciu testu wnioskujemy, że jest lepiej, ale nadal dość słabo. Dopiero podniesienie średniej sim2 do 0,7 będzie dawało bardzo dobre rezultaty, najczęściej p < 0,05. Co ważne, nie zawsze graficznie widoczna ta różnica. 3 przykłady poniżej (sim2 = 0,7), za pomocą komendy plot(sim12, type="l")
Porównanie testu Chowa z testem t
Wcześniej napisałem, że oba testy dają identyczne rezultaty jeśli obie próby są równoliczne. Możemy to teraz sami sprawdzić. Dotychczas test t robiłem w Excelu, ale skoro przechodzimy na R, trzeba to samo zrobić w tym języku. W R test t wykonujemy za pomocą komendy t.test. W naszym przykładzie będzie to
t.test(sim1,sim2).
I tak np. dostaniemy dla niego
t = -2.3179, df = 97.889, p-value = 0.02254
a dla testu Chowa
F = 5.3726, p-value = 0.02254
Z czego ta równość wynika? Podnieśmy statystykę t, czyli -2,3179, do kwadratu. Otrzymamy 5,3726, czyli F.
Jednak ta równowaga obu testów powstaje tylko w przypadku, gdy punkt zmiany struktury wynosi n1, czyli od połowy całej próby. Powiedzmy, że chcemy sprawdzić zmianę średniej nie od połowy zakresu, ale nieco wcześniej, np. od 40-tej obserwacji. Z punktu widzenia testu Welcha próbkę 1 zmniejszymy o 10, a do próbki 2 dokładamy te odjęte wartości. Wykonajmy teraz kod:
n1 = 40
n2 = 60
sim1 = rnorm(n1, 0, 1)
sim2 = rnorm(n2, 0.7, 1)
sim12 = c(sim1,sim2)
t.test(sim1,sim2)
sctest(sim12 ~ 1, type="Chow", point=n1)
Dostałem dla testu Welcha:
t = -2.0099, df = 79.143, p-value = 0.04785
i Chowa:
F = 4.1691, p-value = 0.04385
P-value już nie są takie same (t^2 będzie różne od F). Kolejne przesunięcie punktu zmiany spowoduje jeszcze większą różnicę.
Problem okresu zmiany parametru
W rzeczywistości rzadko wiemy z góry, kiedy moment zmiany może nastąpić. Oryginalny test Chowa [3] zakładał sytuację, gdy badacz ma przed sobą taką oto sytuację. Najpierw jakaś zmienna wykazywała trend przez wiele lat, więc można było znaleźć parametry jej regresji. Mijają kolejne lata i badacz ma zadanie sprawdzić czy trend się zmienił od poprzedniego badania. Czyli do starej regresji dodawane są kolejne obserwacje i można teraz sprawdzić czy nowa regresja (stara powiększona o nowe obserwacje) zmieniła parametry. Widać więc, że jest to odwrotna analiza do naszej. W naszej wybieramy punkt załamania, a Chow nie wybierał żadnego punktu - był on dany z góry.
Mimo tej różnicy, przeprowadzana przez nas analiza jest prawidłowa. Logicznie biorąc nie ma znaczenia, czy dostajemy nową próbkę czy też dzielimy całą próbę na dwie części. W tym drugim podejściu powstaje jednak problem, polegający na arbitralnym wyborze okresu zmiany struktury modelu.
W powyższym przykładzie normalnie założylibyśmy połowę zakresu dla testu Chowa. Czyli sctest miałby postać:
sctest(sim12 ~ 1, type="Chow", point=(n1+n2)/2)
Przykładowo otrzymałem dla Welcha p = 0,008 i Chowa p = 0,021. Innym razem odpowiednio 0,02 i 0,03. Test Welcha zawsze wskaże mniejsze p, czyli da lepsze wyniki, ale generalnie test Chowa nadal sobie dobrze radzi mimo iż błędnie wskazaliśmy moment zmiany. Dzieje się tak, bo odchylenie 10 okresów nie powoduje dużego zamieszania: nadal prrzed połową średnia będzie mniejsza niż po niej.
Niestety jeśli zmniejszymy średnią sim2 do 0,5 sytuacja się pogorszy na niekorzyść Chowa. Np. otrzymamy dla t p-value = 0,014 i dla Chowa 0,092. Problem ten można "rozwiązać" zwiększając liczebność próby. Np. wykonując kod:
n1 = 100
n2 = 200
sim1 = rnorm(n1, 0, 1)
sim2 = rnorm(n2, 0.5, 1)
sim12 = c(sim1,sim2)
t.test(sim1,sim2)
sctest(sim12 ~ 1, type="Chow", point=(n1+n2)/2)
test Chowa będzie już dawał bardzo dobre wyniki mimo odchylenia 50 okresów.
Problem małej próby
Oczywiście nie jest to żadne prawdziwe rozwiązanie, bo w przypadku szeregów czasowych to właśnie liczebność stanowi zawsze ograniczenie. Chociaż zazwyczaj w przypadku zbyt małej liczby danych rocznych czy kwartalnych, zwiększa się częstość do miesięcznej albo tygodniowej, to trzeba pamiętać, że to spowoduje, że także średnia spadnie i uchwycenie zmiany może być trudniejsze. Dodatkową przeszkodą jest zwiększona zmienność dla większych częstości.
Jeżeli fundusz funkcjonuje od 10 lat, to mamy zaledwie 40 kwartałów. Np. jeżeli w próbie 50-elementowej od 35 elementu nastąpi zmiana średniej z 0 na 0,7, to test Chowa:
n1 = 35
n2 = 15
sim1 = rnorm(n1, 0, 1)
sim2 = rnorm(n2, 0.7, 1)
sim12 = c(sim1,sim2)
sctest(sim12 ~ 1, type="Chow", point=(n1+n2)/2)
będzie bardzo chwiejny. Istotność należy już ustawić na 0,1, a i tak co druga próba będzie dawać p > 0,1.
Najgorsze jest to, że jeżeli zmiana średniej nastąpi tylko 5 obserwacji więcej niż w połowie zakresu (czyli n1 = 30 i n2 = 20), to dodatkowo test będzie często zawodził. Nie można wtedy polegać na nim.
Test QLR
W samej idei test QLR (Quandt Likelihood Ratio) rozwiązuje powyższy kłopot bardzo prosto - wykonuje test Chowa po wszystkich punktach zakresu (poza skrajnymi punktami początku i końca sumarycznej próby), a następnie znajduje maksimum otrzymanych statystyk F, które powinno przekroczyć poziom uznany za przypadkowy. Pozornie wydaje się, że można by napisać kod z pętlą, która to robi. To by z kolei znaczyło, że wystarczy wyznaczyć max F i sprawdzić czy p-value > poziom istotności. Tylko że sprawdzając każdy punkt potencjalnej zmiany struktury, za każdym razem wyznaczamy jakieś p-value, a więc dla wielu punktów p staje się zmienną o pewnym rozkładzie częstości. Jeżeli wybieramy sobie z próbki najmniejszą wartość tego rozkładu (któremu odpowiada największe F), to przy dużej próbie zawsze trafimy na p mniejsze od poziomu istotności. Przy mniejszej próbie też będzie na to duża szansa. Będzie to przypadkowe odchylenie zupełnie jak w grze w totolotka, gdy przy wielu losowaniach w końcu trafimy na liczbę wygrywającą. W naszym przypadku każde losowanie to kolejna obserwacja w szeregu czasowym. Testy statystyczne polegają na oszacowaniu prawdopodobieństwa, że takie odchylenie to losowy przypadek, a nie realna cecha rozkładu zmiennej. Widać, że potrzebna jest metoda oceniająca czy przebicie progu istotności nie jest efektem wyłącznie samej budowy rozkładu prawdopodobieństwa, w tym wypadku rozkładu F. Quandt [4] posłużył się ilorazem wiarygodności (likelihood ratio).
W pakiecie strucchange do wykonania testu QLR służy funkcja Fstats. W sumie będą 4 nowe linijki kodu. Pierwsza to funkcja Fstats, którą dla skojarzenia nazwiemy qlr. Druga nie jest potrzebna, ale przyda się grafika - plot. Jest to funkcja wewnętrznie związana ze strucchange, dlatego zawiera także argument alpha. Ustawimy go na 0,1. Trzecia jest najważniejsza, to sctest, ale tym razem głównym argumentem nie będzie model liniowy, tylko sam qlr. Drugi tutaj argument "supF" oznacza supremum statystyki F, czyli właśnie jego max. Czwarta linia - breakpoints - to sam moment zmiany, w naszym przypadku test powinien wskazać 35.
n1 = 35
n2 = 15
sim1 = rnorm(n1, 0, 1)
sim2 = rnorm(n2, 0.7, 1)
sim12 = c(sim1,sim2)
qlr = Fstats(sim12 ~ 1)
plot(qlr, alpha=0.1)
sctest(qlr, type="supF")
breakpoints(qlr)
Przykładowo dostaniemy takie wyniki:
Fstats prawidłowo pokazał, że zmiana struktury nastąpiła w 35 punkcie, ponieważ jest to najwyższy punkt statystyki F. Dodatkowo podano, że odpowiada to 68% całkowitego zakresu.Dostaliśmy więc bardzo ciekawe narzędzie do oceny stabilności średniej, które można wykorzystać do analizy portfela, zarówno akcji, jak i funduszy. Zróbmy przykład dla obu.
----------------------------------------------------------------------------------------
Aspekty techniczne kodowania w R:
Standardowym katalogiem roboczym R jest folder Pobrane / Downloaded , więc tam możemy ściągać dane np. ze stooq.pl. Zaletą portalu jest możliwość ściągnięcia miesięcznych, kwartalnych i rocznych danych, ale wadą jest to, że można nie zauważyć, że ostatni element nie należy do grupy o oczekiwanej częstości, tu kwartalnej, ale jest z ostatniego dnia. Dlatego trzeba pamiętać, że ostatni element usuwamy, jeżeli jego data wyprzedza datę bieżącą. Zrobimy to też za pomocą kodu.
Po ściągnięciu pliku csv, od razu tworzymy nową zmienną o nazwie plik, którą definiujemy jako tabelę wczytaną za pomocą komendy read.csv. Istotną opcją jest wybór separatora, bo czasami będzie to średnik, czasami przecinek. Pliki stooq mają zawsze więcej niż 1 kolumnę, bo 1 to zawsze data. Stąd problem separatora rozwiążemy za pomocą funkcji if, która przypisze przecinek, jeśli liczba kolumn zmiennej plik nadal będzie równa 1.
Powszechnym problemem w kodowaniu jest format daty. Jedną z najważniejszych rzeczy jest przyswojenie sobie, że to co wygląda tak samo, takie być nie musi. Data może być tekstem albo liczbą. Przyzwyczailiśmy się, że datę traktujemy zawsze jak liczbę nie do końca zdając sobie z tego sprawy. Dlatego zawsze musimy zamienić datę-tekst na datę-liczbę. W naszym przypadku jest to proste, bo wystarczy użyć funkcji as.Date().
Pierwsza zmienna to daty, druga - cena. Obie są danymi zewnętrznymi. Stopa to trzecia zmienna- stopa zwrotu. Zmienną tę możemy utworzyć na dwa sposoby. Pierwszy to klasyczna pętla, jednak jest ona mniej wydajna (przy dużej liczbie danych wolniejsza) niż druga metoda zwana wektoryzacją. Ta druga metoda jest także stosowana w Excelu poprzez formuły tablicowe.
----------------------------------------------------------------------------------------
CD Projekt
Dla akcji przykładem niech będzie CDR od 2017 r. - miesięcznie (63 obserwacji). Cena i stopa zwrotu kształtowały się następująco:
Wykonujemy kod:
#jeżeli to wymagane, instalacja pakietu (tu strucchange) i włączenie go
if (require(strucchange)==FALSE) {
install.packages(strucchange)
library(strucchange)
}
#czytamy plik csv
plik = read.csv('cdr_m.csv', sep=";")
if (ncol(plik)==1) {
plik = read.csv('cdr_m.csv', sep=",")
}
#jeżeli ostatnia data przekracza wczorajszą datę, to usuwamy ostatnią obserwację
daty = plik[,1]
daty = as.Date(daty)
if (daty[length(daty)]>Sys.Date()) {
plik = plik[-nrow(plik),]
daty = plik[,1]
daty = as.Date(daty)
}
cena = plik[,2]
#1 sposób obliczenia stopy zwrotu - klasyczna pętla, niewydajny
for (t in 1:length(cena)) {
if (t>1) {
stopa[t-1]=cena[t]/cena[t-1] - 1
}
}
#2 sposób - wektoryzacja
stopa = diff(cena)/cena[-length(cena)]
#dalej już qlr
qlr = Fstats(stopa ~ 1)
sctest(qlr, type="supF")
breakpoints(qlr)
#tworzymy wykresy
par(mfrow=c(2,1), mar=c(2,5,2,2))
plot(qlr, alpha=0.1)
plot(x=daty, y=cena, type="l")
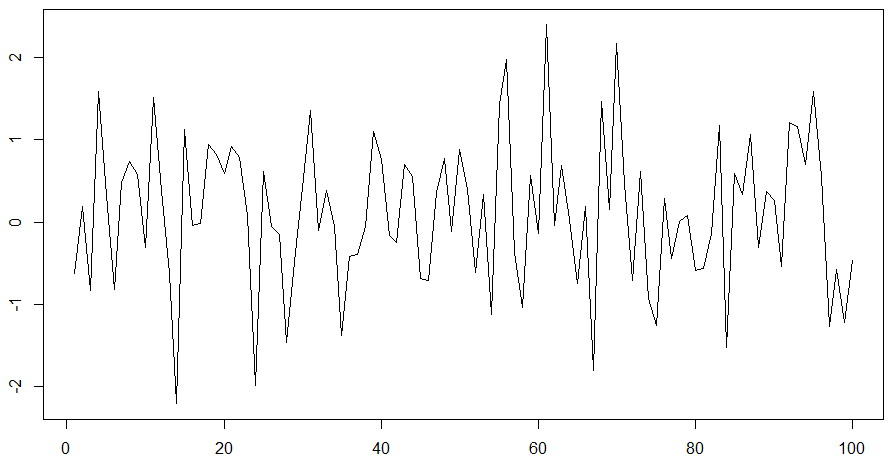
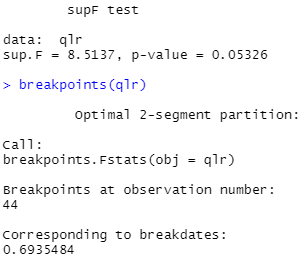
Dostajemy statystyki:
wykres:
Jedna uwaga: ponieważ mamy tu tylko 63 obserwacje, wybrałem istotność 10%. Wygląda na to, że średnia stopa zwrotu CDR zmieniła się od połowy 2020 r. Koresponduje to z widocznym załamaniem trendu rosnącego. Uzyskano p-value = 0,053, czyli hipoteza mówiąca, że nastąpiła zmiana średniej, jest wiarygodna.
Allianz FIO Akcji Małych i Średnich Spółek
Kolejnym przykładem miał być fundusz, więc wybrałem Allianz Akcji MiŚ spółek. Dane także pobrałem ze stooq.pl. Symbol na portalu to 1394_N. Aby zachować porównywalność z poprzednim testem, tak samo przyjąłem początek 2017 i 63 danych miesięcznych.
Kod:
#jeżeli to wymagane, instalacja pakietu (tu strucchange) i włączenie go
if (require(strucchange)==FALSE) {
install.packages(strucchange)
library(strucchange)
}
#czytamy plik csv
plik = read.csv('1394_n_m.csv', sep=";")
if (ncol(plik)==1) {
plik = read.csv('1394_n_m.csv', sep=",")
}
#jeżeli ostatnia data przekracza wczorajszą datę, to usuwamy ostatnią obserwację
daty = plik[,1]
daty = as.Date(daty)
if (daty[length(daty)]>Sys.Date()) {
plik = plik[-nrow(plik),]
daty = plik[,1]
daty = as.Date(daty)
}
cena = plik[,2]
#stopa zwrotu (wektoryzacja)
stopa = diff(cena)/cena[-length(cena)]
#dalej już qlr
qlr = Fstats(stopa ~ 1)
sctest(qlr, type="supF")
breakpoints(qlr)
#tworzymy wykresy
par(mfrow=c(2,1), mar=c(2,5,2,2))
plot(qlr, alpha=0.1)
plot(x=daty, y=cena, type="l")
Wyniki:
I wykresy:W pierwszej połowie 2020 r. notowania funduszu jakby zmieniły kierunek i wielu intuicyjnie uznałoby, że to zmiana trendu ze spadkowego na zwyżkujący. Test QLR rzeczywiście pokazał, że coś się zadziało na stopach zwrotu w tym okresie, bo statystyka F osiągnęła wysoki szczyt. Niemniej obiektywnie oceniając, nie ma powodu, by wierzyć, że to realna zmiana trendu: p-value wynosi 0,17, a więc sporo powyżej 0,1. Uznajemy, że średnia stopa zwrotu funduszu nie zmieniła się.Teoretycznie są dwie konsekwencje testów na stabilność średniej stopy zwrotu. Po pierwsze, jeżeli otrzymamy przesłankę, że nastąpiła zmiana tej średniej, to dostajemy argument, by inwestować lub nie inwestować w dane aktywo. Po drugie, jak dla mnie ważniejsze i bardziej wiarygodne, otrzymujemy informację, czy przy budowie portfela można porównywać średnie stopy zwrotu z różnych aktywów. Np. wskaźnik Sharpe'a może przekonywać, że dane akcje są lepsze, nie biorąc pod uwagę, że mogła nastąpić zmiana struktury i od jakiegoś czasu są tak naprawdę gorsze.
To co tu pokazałem, to oczywiście tylko niewielki wycinek problemu stabilności parametrów stóp zwrotu. Nie poruszyłem sprawy wpływu potencjalnej zmiany wariancji na skuteczność testu Chowa i QLR. Dalej, co jeśli występuje choćby lekka autokorelacja stóp zwrotu lub ich warunkowej wariancji? W końcu, jak na wyniki wpłynie fakt, że stopy zwrotu na giełdzie nie mają rozkładu normalnego? Przecież od początku zakładaliśmy tu klasyczną regresję liniową. Na te wszystkie wątpliwości należy jeszcze odpowiedzieć.
Literatura:
[1] Dobija, M., Dobija, D., Premia za ryzyko jako stała ekonomiczna, Ekonomika Organizacja Przedsiębiorstwa, 6/2006.
[2] Rasch, D., Kubinger, K.D., Moder, K., The two-sample t-test: pre-testing its assumptions does not pay off, Statistical Papers volume 52, p. 219–231 (2011).
[3] Chow, G., Tests of Equality Between Sets of Coefficients in Two Linear Regressions, Econometrica, Vol. 28, No. 3 (Jul., 1960), pp. 591-605.
[4] Quandt, R. E.,
Tests of the Hypothesis that a Linear Regression System Obeys Two Separate Regimes, Journal of the American Statistical Association, Vol. 55, No. 290 (Jun., 1960), pp. 324-330.