W języku R można symulować i modelować procesy ARIMA(p, d, q) za pomocą wielu pakietów, ale zaczniemy od funkcji wbudowanej w sam R.
Symulacja
Symulacje wykonamy za pomocą funkcji arima.sim.
Wybór ziarna
Do odtwarzania zawsze tych samych wyników na liczbach pseudolosowych służy tzw. ziarno, czyli wartość startowa, która determinuje cały ciąg liczb udających losowe. Możemy więc wybrać dowolną liczbę całkowitą i uzyskamy nowe ziarno, a tym samym inny przebieg losowy, który jednak możemy za każdym razem odtwarzać. Podstawowa funkcja to set.seed(x), gdzie x to dowolna liczba całkowita. Czy liczba ziarn jest nieskończona? Nie. W pomocy do funkcji set.seed dowiemy się, że domyślnie używany jest stosunkowo nowy algorytm z 2002 r., którego okres wynosi 2^19937 - 1, czyli tyle jest unikatowych ziarn, a potem powtarzają się od nowa. Tyle w teorii. A w praktyce taka liczba ziarn jest niemożliwa dla programu, gdyż to oznaczałoby liczbę składającą się z 6002 cyfr. Z moich testów wynika, że obecna wersja programu (64bit) jest ograniczona do paru miliardów. W wersji której używam dokładnie jest 4 294 967 295 ziaren. Ponieważ argumenty funkcji seed() nie muszą być dodatnie, to tę liczbę należy rozbić: 2147483647*2 + 1, z czego 2147483647 dotyczy liczb dodatnich oraz ujemnych, stąd mnożymy razy 2, a dodanie 1 dotyczy argumentu 0. Oznacza to ni mniej ni więcej, że pierwsze ziarno otrzymamy za pomocą funkcji seed(-2147483647), a największe seed(2147483647). Możemy to sprawdzić sami. Stwórzmy próbkę z rozkładu normalnego o średniej 0 i wariancji 1:
Przykład 1: brak autokorelacji
AR(0) to proces czysto losowy o rozkładzie normalnym. Aby go zasymulować, stosowałem wcześniej funkcję rnorm. Dzięki ziarnu zobaczymy, że arima i rnorm dadzą dokładnie to samo. Przykładowo bierzemy pierwsze ziarno i generujemy 100 danych za pomocą arima.sim
set.seed(1)
sim1 = arima.sim(list(order=c(0,0,0)), n=100)
plot(sim1, type="l")
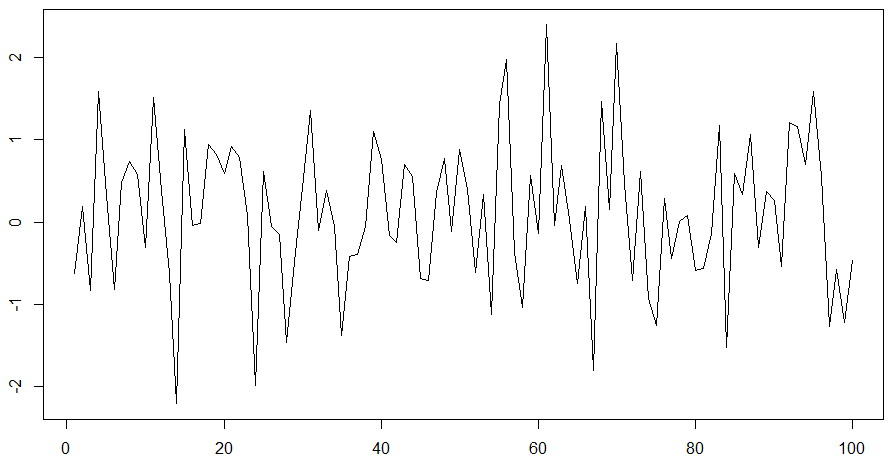
Otrzymamy dokładnie ten sam wykres, gdy wykonamy kod z rnorm:
set.seed(1)
sim1 = rnorm(100,0,1)
plot(sim1, type="l")
Za pomocą funkcji acf i pacf możemy sprawdzić autokorelacje próby. O różnicy między ACF i PACF pisałem kiedyś w art. Jak sprawdzić stabilność modelu ekonometrycznego w czasie?. Zatem wiemy, że ACF służy do oceny stacjonarności, a PACF do oceny autokorelacji danego rzędu. W tym przypadku wpiszmy najpierw
acf(sim1)
Samo takie wpisanie wywoła wykres:

Zerowy rząd, który zawsze będzie równy 1 pomijamy, więc widać, że proces jest stacjonarny.
Potem
pacf(sim1)

Brak autokorelacji - tak jak być powinno.
Przykład 2: autoregresja rzędu 1: AR(1). Powiedzmy, że współczynnik AR(1) - phi - wynosi 0,7. Stosujemy kod:
set.seed(1)
sim2 = arima.sim(list(order=c(1,0,0), ar=0.7), n=100)
plot(sim2, type="l")
Wykres:

Aby pokazać ACF i PACF obok siebie zastosujemy funkcję par(). Funkcja ustawia parametry grafiki w programie. Ponieważ robi to na stałe w sesji, to użyjemy jej dwukrotnie: raz do ustawienia dwóch wykresów, dwa do powrotu do ustawień domyślnych. Dodatkowo ustawimy tylko 5 rzędów acf i pacf, bo więcej nie potrzeba. To się robi za pomocą parametru lag.max:
par(mfrow=c(2,1), mar=c(2,5,2,2))
acf(sim2, lag.max=5)
pacf(sim2,lag.max=5)
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)

plot(sim3, type="l")
I wykres będzie typowo rynkowy:

Po wykonaniu jeszcze raz kodu:
par(mfrow=c(2,1), mar=c(2,5,2,2))
acf(sim3, lag.max=5)
pacf(sim3,lag.max=5)
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)
dostaniemy coś ciekawego:
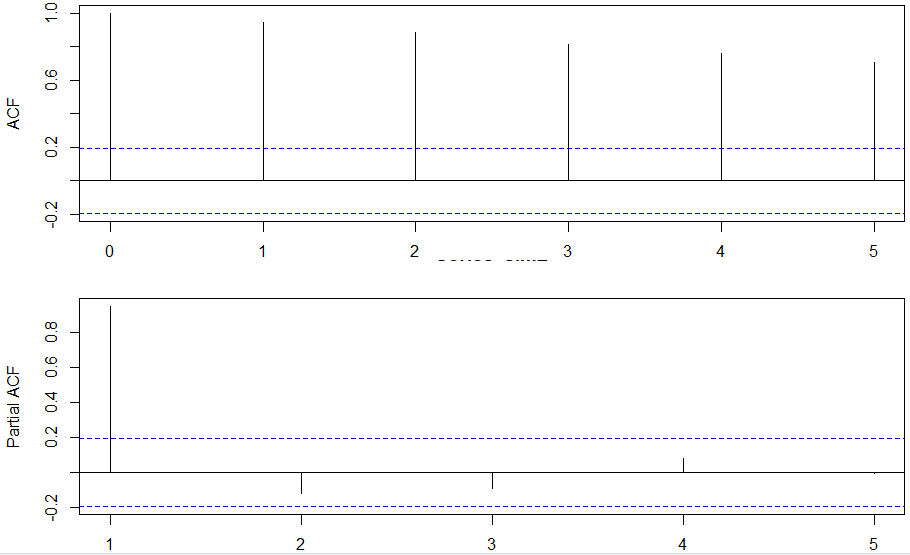
ACF wskazuje na niestacjonarność (powolne spadki autokorelacji), podczas gdy PACF informuje nadal tylko o 1 rzędzie. Można by zapytać dlaczego, skoro mamy tu do czynienia z procesem niestacjonarnym? No właśnie dzieje się tak, bo to co tutaj mamy to AR(1) z p >= 1, więc całkowita autokorelacja wskazuje na bardzo dużą liczbę rzędów (cena z dawnej przeszłości koreluje z ceną teraźniejszą), ale żeby dostać autokorelację tylko dla jednego rzędu, trzeba usunąć wszystkie inne, które na nią wpływają. Tak działa PACF. Czyli zauważmy, że mimo iż przeszliśmy z procesu stacjonarnego do niestacjonarnego tylko ACF się bardzo zmieniło, a PACF zmieniło jedynie poziom samej autokorelacji rzędu 1.
Przykład 4: średnia ruchoma rzędu 1: MA(1). Powiedzmy, że współczynnik MA(1) - theta - wynosi 0,7. Stosujemy kod:
set.seed(1)
sim4 = arima.sim(list(order=c(0,0,1), ma=0.7), n=100)
plot(sim4, type="l")
par(mfrow=c(2,1), mar=c(2,5,2,2))
acf(sim4, lag.max=5)
pacf(sim4,lag.max=5)
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)


Po pierwsze - mimo że ciągle używamy seed(1), to wynik znowu jest inny dla MA(1) niż dla AR(1). Po drugie zmieniła się struktura PACF - korelacja 1-go rzędu jest nadal wysoka, ale pojawiła się drugiego i czwartego ujemna. To świadczy o tym, że MA jest dużo mniej intuicyjna niż AR, ale z drugiej strony obejmuje bardziej skomplikowane procesy. Fakt, że mamy tu ujemną autokorelację 2-go rzędu nie jest przypadkiem. Dla lepszej ilustracji oraz dalszej analizy zróbmy to samo, ale zwiększmy próbę do 1000 oraz liczbę rzędów autokorelacji do 15. Za n wstawiamy do kodu 1000, reszta taka sama. Efekt:


Jak się okazuje PACF realizuje się w postaci na przemian dodatniej i ujemnej autokorelacji. Z czego to wynika? Popatrzmy, MA(1) przy zerowym wyrazie wolnym ma postać:
(1)
W okresie 0 składnik losowy z okresu -1 jest równy zero i wtedy:


Można by jeszcze zapytać dlaczego MA nazywana jest średnią ruchomą albo średnią kroczącą. Pomijając względy historyczne, bo nie jest to rzeczywiście średnia, to zauważmy, że:
* dostaliśmy wyżej model zależny liniowo od wartości poprzednich, a współczynniki można porównać z wagami średniej ważonej (chociaż nie muszą się sumować do 1, dlatego to nie jest prawdziwa średnia),
* mimo że występuje zamiana znaków plus na minus, co wydaje się psuć ideę średniej kroczącej, to zauważmy, że MA dotyczy zmiennej stacjonarnej, a więc zawsze przyspiesza prawo regresji do średniej. Co więcej, możemy utworzyć MA kolejnych rzędów. To znaczy, że dla MA(2) drugi rząd będzie się zachowywał tak samo jak pierwszy z przesunięciem o 1, a to oznacza, że dla okresu 2 znak minus z MA(1) będzie jakby redukowany przez plus z MA(2).
Przykład 5. ARMA(1, 0, 1). phi(1) = 0,7 i theta(1) = 0,7. Kod:
set.seed(1)
sim5 = arima.sim(list(order=c(1,0,1), ar=0.7, ma=0.7), n=1000)
plot(sim5, type="l")

par(mfrow=c(2,1), mar=c(2,5,2,2))
acf(sim5, lag.max=15)
pacf(sim5,lag.max=15)
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)

Przykład 6. ARIMA(1, 1, 1). Siła AR(1) = 0,7 i siła MA(1) = 0,7 oraz d = 1. Kod:
set.seed(1)
sim6 = arima.sim(list(order=c(1,1,1), ar=0.7, ma=0.7), n=1000)
plot(sim6, type="l")

par(mfrow=c(2,1), mar=c(2,5,2,2))
acf(sim6, lag.max=15)
pacf(sim6,lag.max=15)
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)

Wprowadzenie jednoczesne AR i MA wywołało autokorelację rzędu 1 praktycznie równą jedności. I co więcej, nawet jeśli zmniejszymy parametr MA niewiele się zmieni. W ogóle wykres się praktycznie nie zmieni. Zobaczymy to w kolejnym przykładzie.
Przykład 7. ARIMA(1, 1, 1): phi(1) = 0,7 i theta(1) = 0,1 oraz d = 1. Kod:
set.seed(1)
sim7 = arima.sim(list(order=c(1,1,1), ar=0.7, ma=0.1), n=1000)
plot(sim7, type="l")
par(mfrow=c(2,1), mar=c(2,5,2,2))
acf(sim7, lag.max=15)
pacf(sim7,lag.max=15, plot=FALSE)
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)


Przykład 8. Ciekawszy wynik dostaniemy, jeśli ustawimy phi na 0.1 thetę na -0.95. Funkcja PACF występuje dwukrotnie, pierwsza pokazuje wykres, druga - same współczynniki korelacji:
set.seed(1)
sim8 = arima.sim(list(order=c(1,1,1), ar=0.1, ma=-0.95), n=1000)
plot(sim8, type="l")
par(mfrow=c(2,1), mar=c(2,5,2,2))
acf(sim8, lag.max=15)
pacf(sim8,lag.max=15)
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)


Kolejnym etapem jest fitting, czyli dopasowanie modelu. Najłatwiej użyć optymalizacji za pomocą auto.arima(). Jest to funkcja zawarta w pakiecie forecast, który należy zainstalować:
dopas=auto.arima(sim1)
dopas
Otrzymamy:
Series: sim1ARIMA(0,0,0) with zero mean
Prawidłowo.
Ad 2: phi(1) = 0,7. Za sim1 wstawiamy sim2, więc nie ma sensu powtarzać kodu. Wyniki:
Series: sim2ARIMA(1,0,0) with zero mean
Coefficients:
ar1
0.6956
s.e. 0.0712
Prawidłowo.
Ad 3. phi = 1,3.
Series: sim3ARIMA(1,1,0)
Coefficients:
ar1
0.3116
s.e. 0.0958
Prawidłowo.
Ad 4. theta = 0.7
Series: sim4
ARIMA(0,0,2) with zero mean
Coefficients:
ma1 ma2
0.6609 -0.0724
s.e. 0.0318 0.0345
Pierwszy raz błąd. Powinno być MA(1), a dostaliśmy MA(2), pomimo, iż było 1000 danych. Gdy wrócimy do PACF dla przykładu 4, to zobaczymy, że występują istotne ujemne autokorelacje. Jest to niewątpliwie przyczyna błędu. Mimo wszystko powinniśmy uzyskać optimum dla MA(1). Co w takiej sytuacji zrobić? Warto przyjrzeć się p-value. Niestety pakiet tego nie oferuje. Żeby je uzyskać możemy użyć kodu:
(1-pnorm(abs(dopas$coef)/sqrt(diag(dopas$var.coef))))*2
Wynik:
ma1 ma2
0.00000000 0.03583408
p-value dla ma1 = 0 i ma2 = 0.0358. Nie można więc odrzucić modelu MA(2).
Tak więc już napotykamy pierwsze problemy. Pakiet auto.arima domyślnie głównie opiera się na AIC, ale wg moich testów BIC lepiej się sprawdza dla ARIMA. Algorytm można jednak ustawić tak, aby kierował się tylko BIC. Kod musimy zmodyfikować. Domyślny kod miał ustawienia następujące:
dopas=auto.arima(sim1, ic = c("aicc", "aic", "bic"))
Zastąpimy go:
dopas=auto.arima(sim1, ic = c("bic"))
dopas
Wynik:Series: sim4
ARIMA(0,0,1) with zero mean
Coefficients:
ma1
0.7039
s.e. 0.0258
Okazuje się, że kryterium BIC prawidłowo pokazało, że najlepszym modelem jest MA(1).
Ad 5. ARIMA(1, 0, 1). phi(1) = 0,7 i theta(1) = 0,7. Ponowne zastosowanie z BIC daje wyniki
ARIMA(1,0,1) with zero mean
Coefficients:
ar1 ma1
0.6404 0.7329
s.e. 0.0266 0.0268
Czyli prawidłowo. Dla domyślnych ustawień ponownie algorytm nie działał dobrze, dając ARIMA(2, 0, 1).
Ad 6. ARIMA(1, 1, 1). phi(1) = 0,7 i theta(1) = 0,7. To samo, ok.
Ad 7. ARIMA(1, 1, 1). Siła AR(1) = 0,7 i siła MA(1) = 0,1. Dla BIC:
Series: sim7
ARIMA(1,1,0)
Coefficients:
ar1
0.7030
s.e. 0.0225
Tym razem BIC nie poradził sobie, najwyraźniej theta = 0,1 była za małą wartością. Ale phi jest właściwa. Sprawdźmy jeszcze domyślne kryteria:
Series: sim7
ARIMA(2,1,2)
Coefficients:
ar1 ar2 ma1 ma2
-0.2678 0.6085 1.0397 0.0686
s.e. 0.0485 0.0346 0.0554 0.0470
Domyślny algorytm poradził sobie jeszcze gorzej.
Ad 8. ARIMA(1, 1, 1) z phi 0.1, theta -0.95. Zarówno domyślny jak i kryterium BIC dało to samo:
Series: sim8
ARIMA(1,1,2)
Coefficients:
ar1 ma1 ma2
-0.9124 -0.0011 -0.9222
s.e. 0.0401 0.0304 0.0285
Obydwa kryteria błędnie wskazały zarówno liczbę rzędów, jak i wartości współczynników. Proces okazał się dla nich zbyt złożony. Zwiększmy więc liczbę danych z 1000 na 10000:
set.seed(1)
sim8 = arima.sim(list(order=c(1,1,1), ar=0.1, ma=-0.95), n=10000)
plot(sim8, type="l")

Co się okazuje, obydwa kryteria pokazują to samo i radzą sobie dość dobrze:
Series: sim8
ARIMA(2,1,1)
Coefficients:
ar1 ar2 ma1
0.1205 0.0157 -0.9582
s.e. 0.0105 0.0105 0.0032
Chociaż model błędnie dodaje phi(2), to jego p-value okazuje się nieistotne (powtarzamy kod na p-value):(1-pnorm(abs(dopas$coef)/sqrt(diag(dopas$var.coef))))*2
ar1 ar2 ma1
0.0000000 0.1331158 0.0000000
Wobec tego odrzucamy ar2, tak że automat znajduje prawidłowe rozwiązanie.
Podsumowując część optymalnego modelowania, dostajemy dowód, że w ARIMA należy posługiwać się BIC - przynajmniej stosując auto.arima tak jak wyżej. Oczywiście są jeszcze inne możliwe kryteria do sprawdzenia, ale pakiet oferuje jedynie AIC i BIC.
Literatura:
[1] Hansen, B., Econometrics, 2022, link: https://www.ssc.wisc.edu/~bhansen/econometrics/
P. S. Bardzo dobre, zrozumiałe opracowanie.
Brak komentarzy:
Prześlij komentarz