gdzie:
P(0) - wartość wewnętrzna akcji w okresie 0
D - dywidenda (płacona dziś)
D*(1+g)^t - oczekiwana dywidenda w okresie t
r - stopa dyskontowa (wymagana stopa zwrotu)
Wartość wewnętrzna akcji stanowi wynik dzisiejszych oczekiwań co do kształtu przyszłych dywidend. Każda oczekiwana w przyszłości dywidenda jest jednak dyskontowana do dziś - stopa dyskontowa powoduje zmniejszenie jej wartości. Dzieje się tak, ponieważ inwestor płaci za czas i za ryzyko, co oznacza, że przyszła wartość dywidendy nie jest równa dzisiejszej wartości. Stopa dyskontowa jest równa:
r = cena za czas + cena za ryzyko
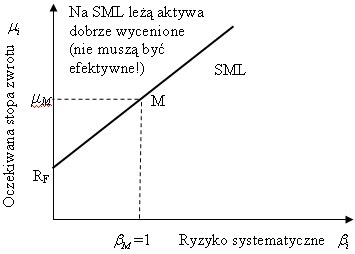
Oczywiście jest to model CAPM.
Wartość czegokolwiek w jakiejś abstrakcyjnej przyszłości nie istnieje. Wartość zawsze odnosi się do teraźniejszości. Dlatego też to, że będziemy otrzymywać strumień pieniędzy w nieskończonym horyzoncie czasu nie ma znaczenia, a więc w sumie informacja o tym, że uzyskujemy nieskończoną sumę pieniędzy jest "bezwartościowa". Całą tę sumę należy odnieść do dziś.
Innym twierdzeniem mistrzów Wschodu jest to, że każdy zysk, "sukces" jest złudzeniem umysłu. Również to zdanie jest zgodne z teorią efektywnego rynku. Na tym rynku inwestor kupuje akcje po cenie równej ich wartości wewnętrznej. Poprzednio dowiedliśmy, że wartość tę można wyrazić za pomocą wzoru (pamiętamy, że jest to przekształcony model Gordona):

Inwestor oczekuje w okresie 1 dywidendy na poziomie D(1+g) i tego, że cena rynkowa akcji wyniesie w tym czasie P(1) - będzie mógł po takiej cenie sprzedać akcje. Powyższy model możemy przekształcić:

A więc można oczekiwać, iż cena P(0) wzrośnie w okresie 1 zgodnie z wymaganą stopą zwrotu r. Jak widać P(0)*(1+r) nie jest równa cenie rynkowej akcji w okresie 1, czyli P(1). Możemy zapisać, że cena rynkowa P(1) równa się:

Zauważmy, że właśnie to odjęcie następuje na (naszym) rynku - kurs odniesienia jest obniżony o wielkość dywidendy w dniu ustalenia prawa do dywidendy. A więc inwestor sprzedaje akcję po cenie P(1), ale dodatkowo uzyskuje dywidendę D(1+g), wobec czego jego całkowity oczekiwany zysk wynosi P(0)*r:

Oczywiście widać natychmiast, że jego oczekiwana stopa zwrotu wynosi właśnie r:

Jak widać, nie ma znaczenia czy powiemy, że inwestor kupił akcję po cenie P(0) i sprzedał po cenie P(1), czy też, że inwestor kupił akcję po cenie P(0) i sprzedał po cenie P(0)*(1+r). W pierwszym przypadku po prostu dodajemy dywidendę, a drugim już ona "siedzi" w cenie sprzedaży.
Powyżej stwierdziliśmy, że stopa dyskontowa r jest równa sumie ceny czasu i ceny ryzyka. Wynika z tego, że r jest to koszt inwestora. Nazywamy go kosztem kapitału własnego. Otrzymujemy wniosek, że całkowity zysk inwestora jest równy kosztowi, który ponosi. Płacąc za czas i ryzyko, otrzymuje on po prostu taki nominalny wzrost wartości akcji. Innymi słowy musi zwyczajnie odjąć ten koszt, tak jak robi się to w rachunkowości, aby otrzymać zysk ekonomiczny:
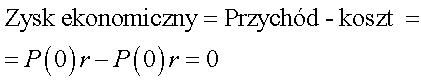
I w ten sposób dowodzimy, że na rynku efektywnym inwestor zarabia ekonomicznie ZERO.
Ten wniosek ma kolejne implikacje. Jeśli rynek kapitałowy daje zerowy zysk, to i każdy inny rynek musi taki dawać. Inaczej bowiem stwarzałoby to możliwość dodatkowego zarobku, która powinna zostać szybko wykorzystana. Wynika z tego, że każdy przedsiębiorca zarabia również w swojej działalności zero.
W sprawozdaniach finansowych zyski oczywiście nie są zerowe. Rachunkowość uwzględnia tylko te przychody i koszty dotyczące działalności gospodarczej, które są łatwo "obliczalne". W ekonomii jednak mamy także do czynienia z "niewidzialnymi" przychodami i kosztami.
Kosztem ekonomicznym nie znajdującym odzwierciedlenia w rachunkowości jest koszt kapitału własnego. Koszt kapitału własnego to właśnie wymagana stopa zwrotu przez inwestora, a zatem cena czasu i ryzyka. Odpowiada na pytanie, ile można wyciągnąć zysku (w postaci gotówki) z kapitału własnego (cena akcji powinna równać się odpowiednio skorygowanej wartości księgowej - ta kwestia powinna być jeszcze oddzielnie omówiona). Dlaczego zysk równa się kosztowi? Właśnie dlatego, że zysk wynika jedynie z podjętego ryzyka oraz wymiaru czasowego, za które się płaci. Zarówno czas jak i ryzyko są siłami destrukcyjnymi, stanowiąc ekonomiczny koszt, ale nie księgowy (w księgowości dokonuje się amortyzacji, ale dotyczy jedynie środka trwałego lub wartości niematerialnej i prawnej). W rachunkowości kategoria kosztu kapitału własnego jak na razie nie istnieje. Ale widzimy teraz jak to działa. Po odjęciu tego kosztu, zysk staje się zerowy.
Niektórzy mogą mieć wątpliwości, rzucając sarkastyczne pytanie: to co, powinniśmy leżeć i nic nie robić, bo i tak wyjdziemy na zero? Takie pytanie wynika z dużego niezrozumienia przedstawionej teorii. To tak jakby powiedzieć, że skoro otrzymujemy energię z zewnątrz, ale po jakimś czasie ją tracimy, to nie ma sensu w ogóle tej energii używać. Dzięki dostarczonej energii możemy robić to co preferujemy i nierobienie niczego jest raczej nieefektywnym zużywaniem energii. Otrzymujemy energię, ale płacimy czasem, a jeśli podejmujemy ryzykowne działania - ryzykiem. Innymi słowy, nierobienie niczego prowadziłoby po prostu do straty. Czyli nie można niczego ekonomicznie zyskać, ale za to można stracić. Energia jest po prostu budżetem, który należy wykorzystać najefektywniej. Co to znaczy najefektywniej? Oznacza to, że cała energia zostaje w pełni wykorzystana, a więc efekt włożonej pracy jest jej równy. Związek z termodynamiką jest jak widać bardzo głęboki.
No a przecież to jest właśnie teoria efektywności rynku! Najefektywniejsze wykorzystanie zasobów. Energia stanowi w tym przypadku kapitał jaki posiadamy, za który możemy kupować instrumenty finansowe, wykorzystując dostępne informacje. Początkowy kapitał musi być całkowicie wykorzystany, inaczej czas (a w fizyce ciepło lub entropia (entropia to zmiana ciepła podzielona przez temperaturę)) dokona zniszczenia. Na marginesie warto zauważyć, że pierwsza zasada termodynamiki stanowi:

Otrzymujemy następującą analogię z ekonomią:
Przychód ekonomiczny = (Koszt czasu + Koszt ryzyka) + Koszt pracy
Koszt czasu można traktować jak ciepło, które ucieka z układu "samo z siebie", cenę ryzyka jak coś pośredniego pomiędzy ciepłem a pracą (gdyż ryzyko trzeba podjąć samemu), zaś koszt pracy po prostu jak pracę (niewykonanie pracy kosztuje w postaci braku wyniku - praca posiada wartość równą kosztowi jej niewykonania).
Przychody ekonomiczne są równe wszystkim ekonomicznym kosztom. Wobec tego:
Zysk ekonomiczny = Przychody ekonomiczne - koszty ekonomiczne = 0.
Powyższa równowaga prowadzi do wniosku, że ani praca, ani kapitał intelektualny nie kreuje zysku ekonomicznego. Weźmy na przykład talent do danego zawodu. Talent pracownika to po prostu koszt pracodawcy w postaci wynagrodzenia. Pracodawca ekonomicznie nie zyska niczego na talencie pracownika, dopóki ów pracownik jest racjonalny - to znaczy wycenia swój talent. Wartość talentu jest obliczona na podstawie zdyskontowanych oczekiwanych dochodów jakie można uzyskać dzięki temu talentowi. Gdyby pracodawca nie płacił danej osobie dokładnie tyle, ile uzyskuje z jej talentu przychodów, toby ta osoba u niego nie pracowała: albo założyłaby swoją działalność gospodarczą wykorzystującą ów talent, albo znalazłaby racjonalnego pracodawcę. Jeśli zakłada własną działalność gospodarczą, to sama siebie wynagradza w ten sam sposób. Niczego nie zyskuje, ponieważ jej talent jest tyle wart, ile uzyskuje dzięki niemu przychodu, a ten talent ją właśnie tyle kosztuje jako pracodawcę siebie samego. To co jest tu abstrakcyjne i niełatwe do zrozumienia, to podzielenie jednej osoby na dwie części: ja jako pracodawca i ja jako pracownik. Mamy więc dwie odrębne jednostki w jednej osobie. Może się to wydać bezsensowne, ale i w psychologii, i filozofiach Wschodu pojawiają się również takie rozbicia indywiduów. Zauważmy, że jeśli w danym momencie myślę o tym, że myślę, to nie znaczy przecież, że jestem tą myślą, ponieważ myśli można zmienić. Ludzie jednak identyfikują się z własnymi myślami, głównie, gdy dotyczą one myśli o sobie. Szerzej, ludzie identyfikują się także z daną grupą społeczną, polityczną lub zawodem. Nie znaczy to jednak, że jeżeli teraz jest się Polakiem, to zawsze się nim będzie, gdyż obywatelstwo można w każdej chwili zmienić. Podobnie, jeśli ktoś mówi, że jest republikaninem, to się myli, bo może zmienić swoje poglądy polityczne. Ktoś, kto mówi, że jest prawnikiem także się myli, bo może zmienić zawód itd. Oczywiście samo pojęcie "bycia" jest bardzo filozoficzne i o tym co to znaczy w ogóle "być" napisano wiele tomów książek. Podkreślam jedynie, że traktowanie siebie w ramach jakiegoś pojęcia - pracownika czy pracodawcy, jest jedynie konwencją.
Przedstawiony idealistyczny świat ekonomii to świat pełen pokoju i równości, w którym zanika wszelka chciwość, żądza, strach i bezlitosna walka o ułamki procent. Każdy w tym świecie zdaje sobie sprawę, że i tak osiągnie zerowy zysk, dopóki będzie podejmował racjonalne decyzje (w przypadku braku racjonalności - poniesie straty). Jedynie preferencje będą pchały do ustalania kupna lub sprzedaży walorów (teoria Markowitza, CAPM). Nie ma już wyścigu kto pierwszy, ten lepszy. Nie ma "wyleszczania". Inwestor kupuje akcje o określonym przez swoje preferencje ryzyku i sprzedaje, gdy zakończy się jego horyzont inwestycyjny (od początku powinien go ściśle określić). Inwestorzy mogą także wymieniać się akcjami z powodu zmian swoich preferencji. Debiutant giełdowy po udanych transakcjach może poczuć większą pewność siebie i zacząć kupować akcje o większym ryzyku. Gdy już na nich straci, to albo wróci do mniejszego ryzyka, albo w celu "odkucia się" podejmie jeszcze wyższe ryzyko. Na szczęście jako racjonalny inwestor nie przejmie się potencjalnym bankructwem (taki żart).
Oczywiście, rzeczywistość nieco się różni od modelu ekonomicznego - rynek nie jest w pełni efektywny. Występuje nie zawsze silna, ale statystycznie istotna autokorelacja pomiędzy kolejnymi zmianami kursów akcji i indeksów giełdowych. Występuje zarówno korelacja liniowa, jak i nieliniowa. Korelacje te występują w różnych częstotliwościach (kilku, kilkunasto-, kilkudziesięciominutowych, dziennych itd.). Problem polega tu na pewnej ułamkowości. Wszystko to dzieje się na płaszczyźnie statystyki. Średnio tak wychodzi, co nie znaczy, że można na tym zawsze ponadprzeciętnie zarobić. Trend może się zmienić właściwie w każdej chwili, ale fraktalność rynku statystycznie zostanie uchwycona. Wynika z tego, że przeszłość ma znaczenie dla przyszłego zachowania kursu. Czyli stopa dyskontowa, która powinna dyskontować czas i ryzyko, a więc przyszłość, nie będzie prawidłowym narzędziem do wyceny akcji (klasyczny CAPM się sypie). Zyski ekonomiczne mogą być różne od zera. W prawdziwym świecie nie ma równości, a przede wszystkim doskonałej informacji. Insider trading na co dzień towarzyszy rynkom. Niejednokrotnie obserwujemy, że kurs akcji rośnie jeszcze przed publikacją raportu, a gdy się ten pojawia, kurs już spada.