Przedsiębiorczy inwestor poszukuje najlepszych, tj. przynoszących największe zyski, walorów na rynku. Gdyby był inwestorem pasywnym, maksymalnie dywersyfikowałby portfel, co znaczyłoby, że nie wierzy w możliwość zainwestowania w najlepsze spółki i opierałby się na teorii efektywności rynku - teorii portfela Markowitza oraz CAPM-CML. Czy jest racjonalne bycie przedsiębiorczym inwestorem czy raczej pasywnym? Odpowiedź zależy od tego czy rynek jest efektywny czy nie. Jeśli jest efektywny, to jedynie racjonalne jest bycie inwestorem pasywnym (co jest oczywiście paradoksem, bo gdyby wszyscy byli racjonalni, nikt nie dyskontowałby nowych informacji, a więc rynek nie byłby efektywny; o tym paradoksie warto byłoby jeszcze podyskutować). Jeśli nie jest efektywny, wtedy warto być inwestorem przedsiębiorczym. Wynika z tego, że trzeba najpierw sprawdzić hipotezę efektywności rynku, a następnie obrać odpowiednią postawę.
Model SML pozwala właśnie sprawdzić czy rynek jest efektywny czy nie. Jest to bowiem model "wyceny" dowolnego aktywa kapitałowego, na przykład pojedynczych papierów wartościowych. Jeśli aktywo nie leży na SML, rynek nie jest efektywny. Przypomnijmy, że model CML dotyczył jedynie portfeli leżących na granicy portfeli efektywnych, a więc służył jedynie inwestorowi pasywnemu. W tym sensie model SML staje się bardziej ogólny od CML. Interpretacja SML jest następująca:
zysk z aktywów = cena czasu + cena jednostki ryzyka rynkowego*ilość ryzyka rynkowego.
Postać SML wyznacza równanie:

gdzie:
μ(i) - oczekiwana stopa zwrotu inwestycji w i-ty walor lub portfel ryzykowny w warunkach równowagi
R(f) - stopa wolna od ryzyka
μ(M) - oczekiwany zysk portfela rynkowego
beta(i) - współczynnik ryzyka systematycznego (rynkowego) i-tego waloru dany wzorem:

gdzie:
cov - kowariancja
σ(M)^2 - wariancja portfela rynkowego
R(M) - zysk portfela rynkowego
R(i) - stopa zwrotu inwestycji w i-ty walor lub portfel ryzykowny
Współczynnik beta staje się wskaźnikiem ryzyka (ilość ryzyka), zastępując tym samym odchylenie standardowe w modelu CML. Wielkość R(M)-R(f) nazywana jest premią za ryzyko. Premia za ryzyko stanowi więc cenę jednostki ryzyka.
Można udowodnić, że w warunkach równowagi (rynku efektywnego), kiedy wszyscy inwestorzy wybierają portfele znajdujące się na CML, stopy zwrotu poszczególnych portfeli ryzykownych (w tym również pojedynczych walorów) są wyznaczane przez równanie SML.
1. Wyprowadzenie modelu
Przypomnijmy metodę tworzenia linii CML. Na poniższym rysunku widać krzywą minimalnego ryzyka, na której leży portfel rynkowy M, zaś CML powstaje poprzez dołączenie do tego portfela instrumentu bez ryzyka rynkowego F, co graficznie powoduje utworzenie się linii prostej łączącej F z M:

Pamiętajmy, że ta krzywa powstaje w oparciu o wszystkie ryzykowne aktywa kapitałowe. Dzięki temu dywersyfikacja ryzyka jest maksymalna dla aktywów ryzykownych, co powoduje, że krzywa minimalnego ryzyka przesunięta jest maksymalnie w lewo.
Jednym z aktywów ryzykownych jest walor A widoczny na rysunku. Możemy zrobić następujący zabieg: potraktować portfel M jak zwykły walor i stworzyć portfele złożone z dwóch walorów: A i M. Taki schemat pokazano na poniższym rysunku:

Należy zauważyć, że powstała krzywa musi mieć nachylenie równe CML. Dlaczego? Spójrzmy na sytuację, gdy krzywa jest nachylona na lewo od punktu M:

A teraz na prawo od M:

W obydwu przypadkach nowa zakreskowana CML jest mocniej nachylona niż pierwotna, co zostaje spowodowane innym nachyleniem krzywej minimalnego ryzyka. Staje się więc możliwe uzyskanie wyższej oczekiwanej stopy zwrotu przy danym ryzyku, albowiem nowa CML okazuje się być bardziej efektywna. Ale to przeczy logice: pierwotna krzywa minimalnego ryzyka optymalizuje portfele składające się ze wszystkich ryzykowanych walorów, zatem również powstająca w oparciu o nią CML musi być najlepszą z możliwych. Wynika z tego, że nowa krzywa minimalnego ryzyka musi mieć w punkcie M nachylenie równe pierwotnej CML.
Na naszym rysunku widoczny jest portfel P1 złożony z A i M. Oczekiwana stopa zwrotu P1 (μ(P1)) jest dana wzorem:
(1)

gdzie:
x - udział waloru A, μ(A) - oczekiwana stopa zwrotu waloru A, μ(M) - oczekiwana stopa zwrotu portfela rynkowego M.
Z kolei odchylenie standardowe stopy zwrotu P1 (σ(P1)) jest równe:
(2)

σ(A)^2 - wariancja stopy zwrotu A, σ(M)^2 - wariancja stopy zwrotu M, Cov(A,M) - kowariancja stóp zwrotu A i M.
Rozważmy nachylenie krzywej minimalnego ryzyka w punkcie P1, z którym ściśle związany jest tangens kąta nachylenia tej krzywej. Tangens kąta jest to pochodna μ(P1) względem σ(P1). Jednocześnie μ(P1) oraz σ(P1) są funkcjami zależnymi od udziału x. Zatem pochodna μ(P1) względem σ(P1) jest pochodną zewnętrzną, natomiast zarówno pochodna μ(P1) względem x jak i σ(P1) względem x jest pochodną wewnętrzną. Aby wyznaczyć pochodną zewnętrzną, wyznaczamy najpierw wewnętrzną zgodnie ze wzorem:
(3)

Na podstawie (1) dostajemy:
(4)

Na podstawie (2) dostajemy
(5)

Kolejny krok polega na tym, że przesuwamy po krzywej portfel P1 w stronę M. W punkcie M udział x wynosi 0. Uwzględniając to i podstawiając (4) i (5) do (3) otrzymujemy:
(6)

Przedostatni krok polega na spostrzeżeniu, że w punkcie M nachylenie krzywej minimalnego ryzyka jest równe nachyleniu CML. Przypomnijmy, że wzór na oczekiwaną stopę zwrotu portfela CML jest dany wzorem:
(7)

Dla przypomnienia - tutaj wyprowadzam CML.
Zatem tangens kąta nachylenia krzywej jest równy współczynnikowi kierunkowemu CML:

Po przekształceniu tego równania otrzymujemy:

Upraszczając to zapisujemy:

Ostatni krok polega na zauważeniu, że powyższą procedurę możemy powtarzać dla każdego i-tego waloru. Zastąpimy A literką i:

I to jest właśnie równanie SML.
Ponieważ beta(i) i μ(i) będą zmieniać swoje wartości dla różnych i-tych aktywów, natomiast R(f) i μ(M) są stałe, to możemy potraktować SML jako zwykłą funkcję liniową. Wielkość R(f) - μ(M) to współczynnik kierunkowy SML. Graficznie SML przedstawia rysunek:
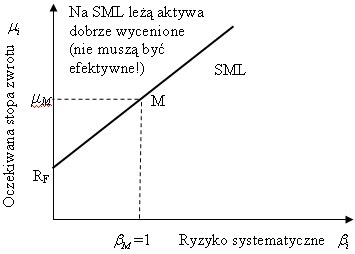
Teraz udowodnimy, że SML stanowi uogólnienie CML. Wzór na betę zawiera kowariancję. Przypomnijmy, że kowariancja może być wyrażona za pomocą wzoru:

gdzie ρ(i,M) to współczynnik korelacji liniowej pomiędzy walorem i oraz M.
Zatem równanie SML można wyrazić w postaci:
Łatwo zauważyć, że gdy współczynnik korelacji równa się 1, wtedy SML = CML. Dokładnie tak; SML staje się CML, ponieważ walor i zmienia się dokładnie z taką samą siłą i kierunkiem jak M. W końcu w CML siedzi zawsze pewna część M, natomiast drugą część stanowi niezmienna stopa zwrotu wolna od ryzyka R(f).
Należy rozumieć, że SML jest rozszerzeniem CML na wszelkie aktywa kapitałowe. Portfele CML były efektywne w sensie Markowitza. Portfele SML muszą być dobrze wycenione, a nie muszą być efektywne.
2. Współczynnik beta
Współczynnik beta jest często określany mianem ryzyka systematycznego (rynkowego), gdyż wskazuje na wrażliwość zmiany ceny aktywa na zmiany ceny portfela rynkowego. Współczynnik beta decyduje o tym, jaką część premii za ryzyko rynku stanowi premia za ryzyko z tytułu inwestycji w portfel ryzykowny. Można bowiem zapisać, że

Jeżeli beta=0, wówczas stopa zwrotu i-tego waloru nie zależy od zmian koniunktury giełdowej. Jeżeli 0 < beta < 1, wówczas poprawie koniunktury na giełdzie mierzonej przyrostem tempa wzrostu portfela rynkowego (przybliżanego indeksem giełdowym) o 1% towarzyszy przyrost stopy zwrotu i-tego waloru o mniej niż 1%. W przypadku, gdy beta=1 stopa zwrotu z analizowanego waloru wzrasta w takim samym tempie jak indeks giełdowy. Jeżeli beta > 1, wtedy poprawa koniunktury giełdowej mierzona przyrostem tempa wzrostu indeksu giełdowego o 1% wywołuje przyrost stopy zwrotu i-tego waloru o więcej niż 1%. Ujemna wartość współczynnika beta może być interpretowana jako przejaw kształtowania się stopy zwrotu wbrew tendencji panującej na rynku, czyli oznacza jej spadek o beta% w sytuacji poprawy koniunktury o 1%.
Z jednej strony, jeśli akcje są silniej skorelowane z rynkiem, to rośnie beta. Z drugiej strony, jeśli zmienność akcji rośnie szybciej niż zmienność rynku, wtedy też rośnie beta. Beta nazywa się ryzykiem systematycznym, ponieważ nie ma sposobu na jego dywersyfikację - będzie systematycznie towarzyszyć inwestycji.
4. Równowaga na rynku kapitałowym
Co by się stało, gdyby oczekiwana stopa zwrotu nie leżała na linii rynku papierów wartościowych?
a) Leży powyżej SML
μ(i) > R(f)+ β[μ(m) - R(f)] => μ(i)- β[μ(m) - R(f)] > R(f).
Aktywa te stanowią bardzo dobry interes. Po skorygowaniu ich stopy zwrotu o ryzyko przynoszą wciąż wyższy przychód niż aktywa wolne od ryzyka. Jeśli inwestorzy odkryją, że takie aktywa istnieją, zechcą je kupić. Ktoś musi im sprzedać, kto również widzi tę zależność. Żeby więc inwestor mógł kupić aktywa, będzie musiał podnieść swoją cenę. Ponieważ stopa zwrotu to (cena 1 - cena 0)/(cena 0), cena 0 wzrośnie, a więc stopa zwrotu spadnie, tak że nadwyżka zysku zostanie zredukowana.
b) Leży poniżej SML
μ(i) < R(f)+ β[μ(m) - R(f)] => μ(i) - β[μ(m) - R(f)] < R(f).
Wszystko na odwrót. Aktywa te stanowią bardzo zły interes. Po skorygowaniu ich stopy zwrotu o ryzyko przynoszą niższy przychód niż aktywa wolne od ryzyka. Jeśli inwestorzy odkryją, że takie aktywa istnieją, zechcą je sprzedać. Ktoś musi od nich kupić, kto również widzi tę zależność. Żeby więc inwestor mógł sprzedać aktywa, będzie musiał obniżyć swoją cenę 0, co oznacza wzrost stopy zwrotu, czyli redukcję niepożądanej straty.
Rynek powinien więc dążyć do równowagi, czyli do spełnienia równania SML, μ(i) = R(f)+ β[μ(m)-R(f)]
5. Problemy praktyczne
Jeśli oczekiwana stopa zwrotu nie będzie leżeć na linii SML, to CAPM stwierdza, że rynek nie jest efektywny. Należy być jednak ostrożnym w stawianiu tezy o nieefektywności rynku, bo założenie o jednorodności i niezależności parametrów w czasie mogą być nieprawdziwe. (Należy wykorzystać wtedy uogólniony model CAPM).
W końcu trzeba znów podkreślić, że na dziś CAPM jest nieweryfikowalny. Portfel rynkowy bowiem zawiera wszelkie, nawet bardzo specyficzne aktywa na rynku (przy założeniu, że posiadają mierzalne parametry stopy zwrotu), będąc przy tym efektywnym w sensie Markowitza. Portfel indeksu giełdowego, który ma zastępować portfel rynkowy, nie musi być efektywny. Jeśli jakiś walor (portfel) uzyskuje stopę zwrotu średnio większą od indeksu giełdowego, to tylko w tym sensie oceniamy, że przynosi on ponadprzeciętne zyski. Jeśli słyszymy, że jakieś badanie wykazało, że CAPM nie sprawdza się w praktyce, to możemy być pewni, że badacz wcale tego nie udowodnił (na dziś). W istocie portfel rynkowy będzie stanowił indeks giełdowy tylko przy założeniu, że wszyscy inwestorzy będą racjonalni (pełne wyjaśnienie tego zagadnienia we wpisie: Dlaczego indeks ważony kapitalizacją uważany jest za benchmark? ).
6. Podsumowanie
CAPM-SML stanowi swego rodzaju uogólnienie CAPM-CML, rozszerzając go na wszelkie aktywa kapitałowe. Model ma na celu prawidłowo wycenić dowolny walor poprzez wyznaczenie optymalnej struktury zysku jaki on generuje i ryzyka systematycznego towarzyszącego mu. Jest to model zupełnie różny od CML z dwóch związanych ze sobą powodów. Po pierwsze nie służy on inwestorowi pasywnemu, który jedynie dywersyfikuje portfel, lecz przedsiębiorczemu, aby mógł sprawdzić hipotezę rynku efektywnego. Na podstawie SML inwestor może oszacować czy walor jest przewartościowany, niedowartościowany czy dobrze wyceniony. Po drugie zapis SML - choć na pierwszy rzut oka bardzo podobny do CML - znaczy kompletnie co innego. W modelu CML inwestor kupuje w pewnych proporcjach wolne od ryzyka na przykład obligacje skarbowe i portfel rynkowy. Ograniczają go jedynie jego możliwości kapitałowe, stąd wyznacza on własną kombinację zysku wolnego od ryzyka i oczekiwanego zysku z portfela rynkowego. W modelu SML nie musi kupować żadnych obligacji skarbowych ani też portfela rynkowego. Instrumenty te stają się jedynie punktem zaczepienia przy osiąganiu stopy zwrotu z akcji czy innych aktyw kapitałowych. Implikacją jest to, że na efektywnym rynku, czyli na linii SML, giełda pozwala zarobić na dowolnym papierze wartościowym lub portfelu dokładnie tyle ile daje papier wolny od ryzyka (cena za czas) plus tyle ile wynosi premia za ryzyko przemnożona przez ilość ryzyka (cena ryzyka).
P.S. Chociaż CAPM został uogólniony na model APT (Teorię Arbitrażu Cenowego wprowadzoną przez Stephana Rossa), to jednak ten drugi nie jest już modelem tak zwartym teoretycznie jak CAPM. CAPM chociażby teoretycznie (a może nawet kiedyś praktycznie) jest falsyfikowalny, a APT nawet teoretycznie nie jest. Jego uogólnienie polega po prostu na uogólnieniu czynników ryzyka, nie mówi się jednak jakie są to czynniki. Jajuga podaje, że na amerykańskim rynku takimi czynnikami są m.in. zmiany PKB, zmiany stopy bezrobocia, zmiany stopy inflacji, zmiany indeksu produkcji przemysłowej, zmiany w różnicy stóp dochodu obligacji o wysokim i niskim ryzyku itp. W sumie więc wszelkie wskaźniki ekonomiczne. Oczywiście przy większej liczbie zmiennych objaśniających, linia SML (tutaj nazywana linią arbitrażu cenowego) staje się hiperpłaszczyzną. W modelu APT nie musi być wcale oczekiwanego zysku portfela rynkowego. Można powiedzieć, że został on rozbity na wiele czynników, bowiem już ten zysk powinien mieć zakodowaną informację o wszystkich przedstawionych elementach wpływających na zmiany kursu. APT jest to model do eksperymentowania, nie do weryfikowania.
W ten sposób zakończyliśmy klasyczną teorię rynków kapitałowych. Należy jednak powiedzieć wprost - to jedynie wstęp do modeli uogólnionych.
Źródło:
1. T. Bołt, Rynki finansowe, część II, rok akademicki 2004/2005;
2. H. R. Varian, Mikroekonomia, W-wa 2002.
3. K. Jajuga, T. Jajuga, Inwestycje. Instrumenty finansowe, ryzyko finansowe, inżynieria finansowa, 2006.
































