Dynamika środowiska giełdowo-gospodarczego powoduje, że parametry modeli ekonometrycznych są niestabilne i nie można ich traktować jako coś pewnego. Wiadomo choćby, że występują cykle nieokresowe, tzn. powtarzające się wzrosty i spadki o zmiennej długości i amplitudzie (i stąd niełatwe do prognozowania). Nie ma więc mowy o sezonowości, ale można badać zmienne korelacje, średnie oraz lokalne trendy. W tym art. analizowałem testy na zmianę struktury modelu, ale ich ograniczeniem była pojedyncza zmiana parametru. Jeżeli w próbie występują dwie albo więcej zmian, testy tego typu mogą okazać się niewystarczające, a może nawet wprowadzające w błąd. Poniższe przykłady i cała analiza będzie wykonywana w języku R. Najlepiej używać nakładki na suche środowisko R, RStudio, które znacznie ułatwia wprowadzanie kodów. Rzeczy, które tu omawiam są kontynuacją serii artykułów: 1, 2, 3, 4. Jeżeli coś jest niejasne, to prawdopodobnie w którymś z nich jest wyjaśnione. Jeżeli nie, należy sięgnąć do pomocy technicznej języka R.
Zanim przejdę do przykładów nasz skrypt musi mieć wstępny kod. A właściwie przedwstępny, dlatego że w późniejszych przykładach będą kolejne wstępne kody. Dla jasności zapisów kody będę oznaczał jako: Przedwstęp, Wstęp, Pod-wstęp (o ile jest), Część główna.
Potrzebne są nam cztery pakiety: tseries, strucchange, forecast oraz lmtest:
# Przedwstęp
if (require("tseries")==FALSE) {
install.packages("tseries")
library("tseries")
}
if (require("strucchange")==FALSE) {
install.packages("strucchange")
library("strucchange")
}
if (require("forecast")==FALSE) {
install.packages("forecast")
library("forecast")
}
if (require(lmtest)==FALSE) {
install.packages("lmtest")
library("lmtest")
}
Jedna uwaga. Raz na jakiś czas pakiety są aktualizowane, a wtedy i tak musimy je na nowo zainstalować, stąd jeśli nie zależy nam na efektywności kodu, to możemy zawsze używać po prostu:
install.packages("tseries")
library("tseries")
install.packages("strucchange")
library("strucchange")
install.packages("lmtest")
library("lmtest")
Przykład 1. Błądzenie losowe
Symulujemy ruch Browna z podziałem na 3 części: 50 danych ze średnią 1, 50 danych ze średnią 1.5 oraz 50 danych ze średnią 1. Połączoną próbę nazwiemy sim123:
# Wstęp
set.seed(550)
sim1 = arima.sim(list(order=c(0,0,0)), n=50, mean=1)
sim2 = arima.sim(list(order=c(0,0,0)), n=50, mean=1.5)
sim3 = arima.sim(list(order=c(0,0,0)), n=50, mean=1)
sim123 = c(sim1, sim2, sim3)
# Część główna
Testujemy stacjonarność (KPSS):
# test stacjonarności
if (length(stopa)>200) {
kpss.test(sim123, lshort=FALSE)
} else {
kpss.test(sim123)
}
Efekt:
KPSS Test for Level Stationarity
data: sim123
KPSS Level = 0.41947, Truncation lag parameter = 4, p-value = 0.06877
KPSS wykrył prawidłowo niestacjonarność (p < 0.1). Teraz jednak chcemy znaleźć punkty przełamań. To zastosujmy jak dotychczas QLR. Aby dobrze pokazać zmienną sim123 razem ze statystykami F, stosujemy funkcję par:
par(mfrow=c(2,1), mar=c(2,5,2,2))
plot(sim123, type="l")
qlr = Fstats(sim123 ~ 1)
plot(qlr, alpha=0.05)
Efekt:
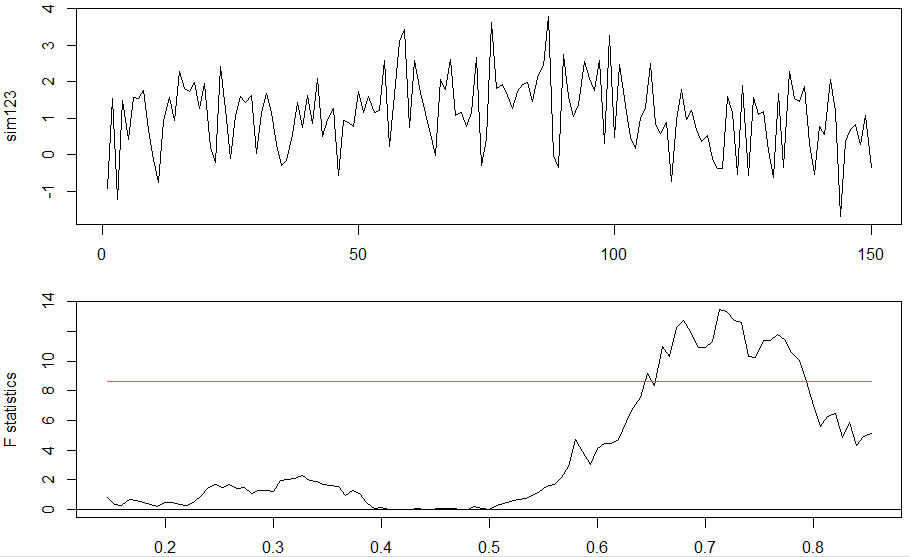
Graficzny test QLR pokazał tylko jeden punkt zmiany, czyli wprowadza w błąd. A wynika on właśnie z tego, że test dzieli próbę na dwie części i poszukuje istotnych zmian. Bai i Perron [1] zaproponowali procedurę uogólniającą QLR na testowanie wielu punktów zmian struktury regresji liniowej.
Od teraz zamiast QLR będziemy stosować funkcję breakpoints(). De facto już ją stosowałem do znajdowania momentu zmiany, ale wtedy ograniczałem się do jednego punktu. Np. żeby dostać konkretny punkt zmiany w sim123, który odpowiada statystyce supF wpisuję tylko:
breakpoints(qlr)
Efekt:
Breakpoints at observation number:
107
Corresponding to breakdates:
0.7066667
Widzimy, że to odpowiada mniej więcej maksimum na wykresie statystyk F.
I uwaga, pokażę, jaki błąd początkowo popełniałem. Funkcja breakpoints() ma taki argument jak breaks, który oznacza maksymalną liczbę wybranych punktów "przełamań". Wydawało się, że wystarczy wpisać: breakpoints(qlr, breaks = 2) , aby znaleźć 2 takie momenty. Ale przecież argument qlr dotyczy tylko jednego takiego punktu, dlatego to nie zmieni efektu. Co więc zrobić? Okazuje się, że te funkcje są dość elastyczne i można je zastosować na różnych funkcjach. I tak zamiast argumentu qlr, czyli zamiast statystyk F, można wpisać sam model sim123 ~ 1. Mówiąc inaczej breakpoints częściowo zastępuje funkcję Fstats. Dlaczego częściowo? Bo funkcja plot(breakpoints()) działa wtedy inaczej.
Po kolei. Pierwsza część nowego kodu będzie wyglądać następująco. Dla ułatwienia przekształcamy szybko dane w szereg czasowy:
sim123 = ts(sim123)
Następnie stosujemy na tej zmiennej breakpoints:
bai = breakpoints(sim123 ~ 1, breaks = 2)
summary(bai)
Efekt:
Breakpoints at observation number:
m = 1 107
m = 2 49 102
Corresponding to breakdates:
m = 1 0.713333333333333
m = 2 0.326666666666667 0.68
Fit:
m 0 1 2
RSS 148.9 136.5 124.3
BIC 434.6 431.6 427.6
Ponieważ sami wybraliśmy dwa punkty, to dostaliśmy analizę dla dwóch punktów. Najpierw wskazano jakie to punkty. Warto zwrócić uwagę, że algorytm inaczej oblicza je zależnie od ustawienia breaks, co wyraża tu indeks m. Dla m = 1 algorytm oszacował 107 (na datach - ponieważ nie ma ustawień dat - w częściach ułamkowych - 0,71), a dla m = 2 49 (0,33) i 102 (0,68).
Najważniejsza statystyka jest na dole. Patrzymy jak zachowuje się BIC. Dla m = 2 BIC jest najmniejszy w porównaniu z m = 0 i m = 1. Zatem wnioskujemy, że algorytm prawidłowo wskazał istotne 2 przełamania.
Co by się stało, gdybyśmy zwiększyli m do 4? Popatrzmy:
bai = breakpoints(sim123 ~ 1, breaks = 4)
summary(bai)
Efekt:
Breakpoints at observation number:
m = 1 107
m = 2 49 102
m = 3 49 75 102
m = 4 24 49 75 102
Corresponding to breakdates:
m = 1 107
m = 2 49 102
m = 3 49 75 102
m = 4 24 49 75 102
Fit:
m 0 1 2 3 4
RSS 148.9 136.5 124.3 122.7 122.5
BIC 434.6 431.6 427.6 435.7 445.4
Widać, że dla m >= 3 BIC wzrósł, a więc wynik się pogorszył. Wniosek: nie ma więcej niż 2 punkty zmiany modelu - prawidłowo.
Jeżeli chcemy zobaczyć to graficznie, to używamy plot:
bai = breakpoints(sim123 ~ 1, breaks = 4)
plot(bai)
Efekt:

Plot możemy jeszcze użyć do dwóch celów.
W połączeniu z funkcją lines możemy na wykresie czasowym pokazać momenty zmian w czasie:
par(mfrow=c(2,1), mar=c(2,5,2,2))
sim123 = ts(sim123)
plot(sim123)
bai = breakpoints(sim123 ~ 1)
lines(bai, breaks = 2)
Efekt:
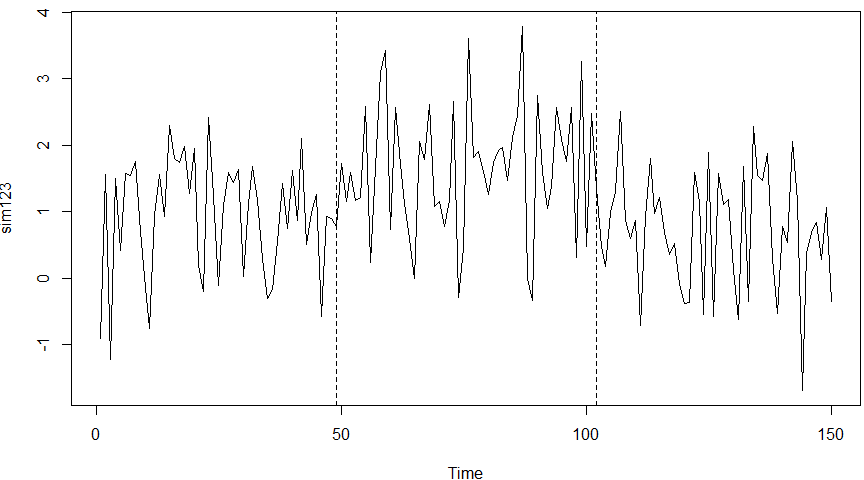
Grafika wyżej zawiera pewien błąd związany z ucięciem 15% skrajnych danych na Fstat. Wcześniej to poprawiałem dla prawdziwych danych, ale w tym wypadku to byłaby bardziej sztuka dla sztuki.
Jeszcze ciekawszą grafikę można pokazać wykorzystując funkcję breakfactor:
sim123.model = lm(sim123 ~ breakfactor(bai)-1)
dopas = fitted(sim123.model)
plot(sim123)
lines(dopas, col=4, lwd=3)

Efekt:
breakfactor(bai, breaks = 2)segment1 breakfactor(bai, breaks = 2)segment2 breakfactor(bai, breaks = 2)segment3
0.9340913 1.6430498 0.7015123
W sumie cały nasz nowy kod może wyglądać następująco:
#Wstęp
#symulacja procesu losowego - tu ruchu Browna - zmienne parametry
set.seed(199)
sim1 = arima.sim(list(order=c(0,0,0)), n=50, mean=1)
sim2 = arima.sim(list(order=c(0,0,0)), n=50, mean=1.5)
sim3 = arima.sim(list(order=c(0,0,0)), n=50, mean=1)
sim123 = c(sim1, sim2, sim3)
# Część główna
# test stacjonarności
if (length(sim123)>200) {
kpss.test(sim123, lshort=FALSE)
} else {
kpss.test(sim123)
}
#ustawienie parametru graf
par(mfrow=c(3,1), mar=c(5,5,2,2))
sim123 = ts(sim123)
plot(sim123)
#Procedura Bai-Perrona:
bai = breakpoints(sim123 ~ 1, breaks = 4)
lines(bai, breaks = 2)
summary(bai)
plot(bai)
sim123.model = lm(sim123 ~ breakfactor(bai)-1)
dopas = fitted(sim123.model)
plot(sim123)
lines(dopas, col=4, lwd=3)
coef(sim123.model)
#przywracanie parametru graf
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)
Przykład 2.
Wykonajmy ten sam kod, ale zmieńmy jedną linię. Zamiast
sim123.model = lm(sim123 ~ breakfactor(bai)-1)
wpiszmy
sim123.model = lm(sim123 ~ breakfactor(bai, breaks = 1)-1)
Efekt:
breakfactor(bai, breaks = 1)segment1 breakfactor(bai, breaks = 1)segment2
1.292695 0.655961

Czyli widzimy, że jeśli nie wstawimy parametru breaks do breakfactor, to algorytm automatycznie wybiera optymalną liczbę punktów. Dopisanie tego parametru wymusza taką liczbę zmian, jaką chcemy.
Przykład 3. ARMA(1, 1)
Znów zmieniamy parametry procesu w połowie próby dwukrotnie, ale tym razem średnią zachowuję taką samą, a zmienia się część AR i MA:
#Wstęp
set.seed(1980)
sim1 = arima.sim(list(order=c(1,0,1), ar=0.6, ma=0.3), n=50, mean=1)
sim2 = arima.sim(list(order=c(1,0,1), ar=0, ma=0), n=50, mean=1)
sim3 = arima.sim(list(order=c(1,0,1), ar=0.6, ma=0.3), n=50, mean=1)
sim123 = c(sim1, sim2, sim3)
# Część główna
# test stacjonarności
if (length(sim123)>200) {
kpss.test(sim123, lshort=FALSE)
} else {
kpss.test(sim123)
}
#ustawienie parametru graf
par(mfrow=c(3,1), mar=c(5,5,2,2))
sim123 = ts(sim123)
#Procedura Bai-Perrona:
bai = breakpoints(sim123 ~ 1)
plot(bai)
Efekt:
KPSS Test for Level Stationarity
data: sim123
KPSS Level = 0.31029, Truncation lag parameter = 4, p-value = 0.1

Tym razem dostaliśmy niespójność: dane są stacjonarne mimo wskazania punktów zmian. Ponadto test wskazał 3 punkty, choć powinien dwa.
Błąd, o którym już pisałem w art. o trzech technikach testu F wynika z tego, że sprawdziliśmy sobie samą średnią (wyraz wolny), a nie cały model, który tutaj dodatkowo (oprócz wyrazu wolnego) zawiera zmienne zależne. Poprawiamy:
# Wstęp
set.seed(1980)
sim1 = arima.sim(list(order=c(1,0,1), ar=0.6, ma=0.3), n=50, mean=1)
sim2 = arima.sim(list(order=c(1,0,1), ar=0, ma=0), n=50, mean=1)
sim3 = arima.sim(list(order=c(1,0,1), ar=0.6, ma=0.3), n=50, mean=1)
sim123 = c(sim1, sim2, sim3)
# Część główna
# test stacjonarności
if (length(sim123)>200) {
kpss.test(sim123, lshort=FALSE)
} else {
kpss.test(sim123)
}
sim123 = ts(sim123)
#tworzenie modelu arma(1,1)
sim = ts(sim123[-1])
sim_ar1 = ts(sim123[-length(sim123)])
sim_arma11 = arima(sim123, order=c(1,0,1))
sim_ma = ts(residuals(sim_arma11))
sim_ma1 = ts(sim_ma[-length(sim_ma)])
#Procedura Bai-Perrona:
bai = breakpoints(sim ~ sim_ar1 + sim_ma1)
plot(bai)
Efekt:

Tym razem jest OK.
To dokończmy kod:
plot(sim123)
lines(bai, breaks = 2)
summary(bai)
sim.model = lm(sim ~ breakfactor(bai)-1)
dopas = fitted(sim.model)
lines(dopas, col=4, lwd=3)
coef(sim123.model)
#przywracanie parametru graf
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)
Efekt:

Kolejne przykłady będą robione na danych rzeczywistych. Dane w formie plików najpierw ściągam z internetu. I tu pokażę jedną nową rzecz. Żeby otworzyć plik w R, musimy podać ścieżkę i tu napotykamy niekompatybilność R z Windowsem: w tym pierwszym ścieżki używają slasha, a w tym drugim backslasha. Coś, co np. w VBA jest łatwe do podmiany, w R okazuje się zadziwiająco trudne. W każdym razie jeśli mamy w miarę nową wersję R, to stosujemy następujący kod. Powiedzmy, że nasza ścieżka z plikami (folder roboczy) to C:\R\testy
# Wstęp
#zamieniam "\" na "/"
sciezka = r"(C:\R\testy)"
sciezka = gsub("\\", "/", sciezka, fixed=T)
# albo
# sciezka = gsub("\\\\", "/", sciezka)
# ustawiamy folder roboczy
setwd(sciezka)
I teraz idziemy z żywymi przykładami.
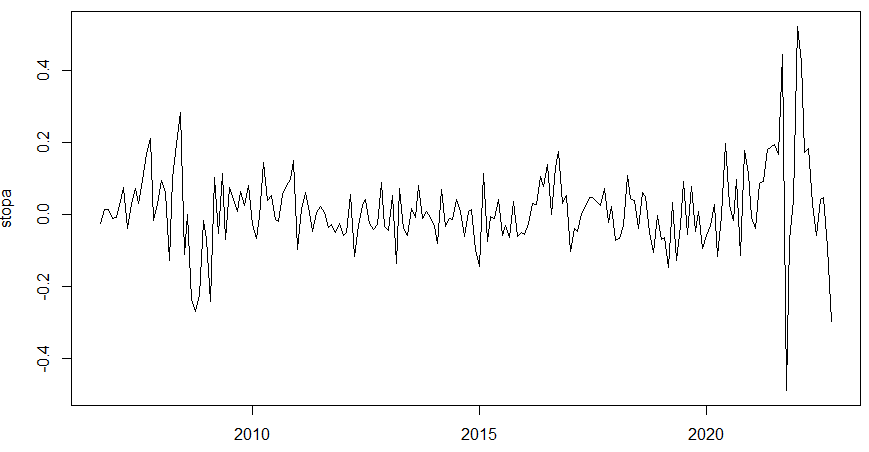
Przykład 4. Ceny węgla (ICE Rotterdam Coal)
Sprawdzamy notowania węgla od 31.08.2006 do 31.10.2022 - dane miesięczne, źródło stooq.pl: kontrakty na węgiel (oznaczenie LU.F). Mam plik o nazwie coal.csv. Początek pliku wygląda tak:
Data Otwarcie Najwyższy Najniższy Zamknięcie
31.08.2006 70 70.5 67.9 68.45
30.09.2006 67.5 67.5 63.75 66.75
31.10.2006 65 68.55 63.5 67.75
30.11.2006 68.25 68.75 66.2 68.75
31.12.2006 67 69.25 67 68

# test stacjonarności
if (length(stopa)>200) {
kpss.test(stopa, lshort=FALSE)
} else {
kpss.test(stopa)
}
Efekt:
KPSS Test for Level Stationarity
data: stopa
KPSS Level = 0.22501, Truncation lag parameter = 4, p-value = 0.1
Zmiany procentowe są stacjonarne. Oznacza to, że raczej nie mamy tutaj do czynienia ze zmienną średnią. Sprawdzamy autokorelację cząstkową. Możemy ją sprawdzić za pomocą funkcji pacf(). Niestety ona sama nie zawiera informacji o istotności stat. Dlatego do pacf() dodamy kod na skumulowany rozkład odwrotny. W sumie:
pacf(stopa, plot=FALSE, lag.max=10)
ist_pacf = qnorm((1 + 0.95)/2)/sqrt(sum(length(stopa)))
noquote(c("Istotna autokorelacja będzie od poziomu: ", ist_pacf))
Efekt:
Partial autocorrelations of series ‘stopa’, by lag
0.0833 0.1667 0.2500 0.3333 0.4167 0.5000 0.5833 0.6667 0.7500 0.8333
0.242 0.089 -0.081 0.086 -0.005 -0.010 0.100 -0.004 -0.047 0.055
Istotna autokorelacja będzie od poziomu: 0.140717213329746
Ułamkowe rzędy mogą być mylące, bo są to po prostu kolejne części roku: 1/12 = 0.0833 = 1 miesiąc, 1/6 = 0.1667 = 2 miesiące itd. Dla kwartałów byłoby to 0.25 = kwartał ; 0.5 = 2 kwartał itd. Istotna korelacja występuje od poziomu 0.14, a to znaczy, że mamy do czynienia z korelacją 1 rzędu. Prawdopodobnie zastosujemy AR(1). Upewniamy się za pomocą funkcji auto.arima:
arma_stopa = auto.arima(stopa,ic="bic", max.P=7, max.Q=7)
arma_stopa
Efekt:
ARIMA(1,0,0) with zero mean
Coefficients:
ar1
0.2612
s.e. 0.0705
sigma^2 = 0.01162: log likelihood = 157.29
AIC=-310.59 AICc=-310.53 BIC=-304.05
Istotnie występuje AR(1), więc tworzymy ten model. Zwróćmy uwagę, że stopa zwrotu już zaczyna się od drugiej obserwacji, więc zmienna opóźniona 1 rzędu będzie zaczynać się od 3-ciej. Choć moglibyśmy użyć podobnej techniki jak przy symulacji, to użyjemy innej, w sumie prostszej techniki, używając funkcji lag. Mimo prostoty funkcja nie jest zbyt intuicyjna, więc opiszę ją nieco dokładniej.
--------------------------------------------------------------------------------------
Zacznijmy od pytania czym jest zmienna opóźniona o 1 okres? Powiedzmy, że zmienna to nasz szereg czasowy. Wtedy opóźniona o 1 będzie to:
zmienna1 = zmienna[-length(zmienna)]
i aby porównać ją z bieżącym okresem, musieliśmy utworzyć nową bieżącą zmienną , którą definiowaliśmy jako
zmienna0 = zmienna[-1]
Zatem zmienna1 to zmienna kończąca się na przedostatniej obserwacji, a zmienna0 to zmienna zaczynająca się od drugiej obserwacji. Jeżeli więc tworzymy model typu:
zmienna0 ~ zmienna1
to patrzymy jak pierwsza obserwacja (zmiena1) wpływa na drugą (zmiena0), druga na trzecią itd.
I teraz najważniejsze: opisana technika wcale nie tworzy zmiennej opóźnionej sensu stricte. Czas płynie do przodu, a to znaczy, że opóźniona obserwacja to taka, która występuje później niż bieżąca. A więc w rzeczywistości tworzyliśmy tutaj nie zmienną opóźnioną, ale przyspieszoną (pospieszoną)! Zmienna0 to zmienna obserwowana w czasie teraźniejszym i patrzymy jak na nią wpływa zmienna1 z przeszłości. Skoro więc porównujemy dzisiejsze obserwacje z tym co było, to w pewnym sensie traktujemy obserwacje z przeszłości jako teraźniejsze, bo skoro mają teraz wpływ, to znaczy, że ciągle istnieją tu i teraz. Z technicznego punktu widzenia bierzemy dane z przeszłości i przesuwamy do przodu. To przesunięcie do przodu oznacza właśnie przyspieszenie, a nie opóźnienie.
Dlaczego o tym mówię? Bo funkcja lag tworzy zmienną opóźnioną sensu stricte. Wielu tego nie rozumie i w poradnikach możemy przeczytać, że lag działa na odwrót i trzeba używać ujemnego kroku, aby dostać opóźnienie. W rzeczywistości ten ujemny lag da nam właśnie pospieszenie okresu, ale to właśnie o to nam chodzi. Dlatego do intuicyjnie rozumianych "opóźnień" używamy ujemnego kroku, a do "pospieszeń" dodatniego. W każdym razie nie ma tu żadnego błędu, a jedynie musimy pamiętać, że jeżeli wyciągamy zmienną z przeszłości do teraźniejszości, to de facto ją pospieszamy, choć w modelu nazywamy ją zmienną opóźnioną.
--------------------------------------------------------------------------------------
Tworzymy zmienną opóźnioną:
stopa1 = lag(stopa, k = -1)
To niestety nie wystarcza do stworzenia AR(1), bo przesuwa całą zmienną razem z okresem, podczas gdy my chcemy zachować stałość okresu, a jedynie przesuwać obserwacje w czasie. Żeby uzyskać żądany efekt, musimy użyć funkcji intersect (albo ts.intersect aby działać od razu na ts), która działa jak funkcja INNER JOIN w SQL. Nazwa intersect jest myląca, powinna działać jak przecięcie zakresów w VBA albo mieć nazwę np. "innerjoin". Ale nieważne, tworzymy nową zmienną:
dane = ts.intersect(stopa, stopa1)
którą wykorzystujemy do przekształcenia naszych zmiennych:
stopa0 = dane[, "stopa"]
stopa1 = dane[, "stopa1"]
I dalej już to co wcześniej:
#test Bai-Perrona
bai = breakpoints(stopa0 ~ stopa1, breaks = 3)
summary(bai)
plot(bai)
Efekt:
Breakpoints at observation number:
m = 1 164
m = 2 29 164
m = 3 29 58 164
Corresponding to breakdates:
m = 1 2020(5)
m = 2 2009(2) 2020(5)
m = 3 2009(2) 2011(7) 2020(5)
Fit:
m 0 1 2 3
RSS 2.228 2.149 2.082 2.041
BIC -297.590 -288.798 -279.130 -267.116

A więc brak zmian struktury. Z jednej strony to pozytywne, bo znaczy, że można lepiej prognozować kolejne zmiany dzięki autoregresji, która pozostaje stabilna. Z drugiej strony ostatnie lata przynoszą o wiele większe wahania, więc możliwe, że to wariancja stopy zwrotu się zmieniła, a nie średnia czy autokorelacja.
Zmianę wariancji, jak pamiętamy, wykonujemy np. za pomocą takich testów jak Goldfelda-Quandta, Breuscha-Pagana czy Harrisona-McCabe. Kod:
czas = c(1:length(stopa))
bptest(stopa ~ czas)
gqtest(stopa ~ 1)
hmctest(stopa ~ 1)
Normalnie w każdym z tych testów użyłbym wyrazu wolnego za zmienną niezależną, ale dla pierwszego nie da się - pokazuje się błąd, dlatego ustawiłem czas. Wszystkie z tych testów p-value < 0,01, zatem nie ma wątpliwości, że wariancja stopy zwrotu jest zmienna w czasie. Skoro test Bai-Perrona był niewrażliwy na jej zmianę, to znaczy, że można go spokojnie używać na danych heteroskedastycznych.
Cały kod:
# Pod-wstęp
nazwa = "Coal.csv"
plik = read.csv(nazwa, sep=";")
if (ncol(plik)==1) {
plik = read.csv(nazwa, sep=",")
}
daty = as.Date(plik[,1], tryFormats = c("%d.%m.%Y", "%Y.%m.%d", "%d-%m-%Y", "%Y-%m-%d", "%d/%m/%Y", "%Y/%m/%d"))
#jeżeli ostatnia data przekracza wczorajszą datę, to usuwamy ostatnią obserwację
if (daty[length(daty)]>=Sys.Date()) {
plik = plik[-nrow(plik),]
daty = daty[-length(daty)]
}
rok = as.numeric(format(daty, "%Y"))
mc = as.numeric(format(daty, "%m"))
dz = as.numeric(format(daty, "%d"))
cena = as.numeric(plik[,5])
cena = ts(cena, start=c(rok[1], mc[1]), frequency=12)
stopa = diff(cena)/cena[-length(cena)]
# Część główna
#test stacjonarności
if (length(stopa)>200) {
kpss.test(stopa, lshort=FALSE)
} else {
kpss.test(stopa)
}
pacf(stopa, plot=FALSE, lag.max=10)
ist_pacf = qnorm((1 + 0.95)/2)/sqrt(sum(length(stopa)))
noquote(c("Istotna autokorelacja będzie od poziomu: ", ist_pacf))
arma_stopa = auto.arima(stopa,ic="bic", max.P=7, max.Q=7)
arma_stopa
stopa1 = lag(stopa, k = -1)
dane = ts.intersect(stopa, stopa1)
stopa0 = dane[, "stopa"]
stopa1 = dane[, "stopa1"]
#test Bai-Perrona
bai = breakpoints(stopa0 ~ stopa1, breaks = 3)
summary(bai)
plot(bai)
czas = c(1:length(stopa))
bptest(stopa ~ czas)
gqtest(stopa ~ 1)
hmctest(stopa ~ 1)
Przykład 5. Inflacja USA
Inflacja roczna USA w latach 1775-2021 (247 obs), średnioroczna. Źródło: https://www.measuringworth.com/
Zanim przejdę do części głównej, zmodyfikuję nieco część pod-wstępną, tak aby uwzględniała zarówno roczne, jak i miesięczne, a także aby można było łatwo przełączać się między danymi pierwotnymi a przekształconymi. W tym ostatnim chodzi o to, czy nasza zmienna już jest gotowa (stopa inflacji jest podana), czy może musimy ją uzyskać (przekształcić ceny w stopy zwrotu). Oprócz tego do read.csv dodam opcję dec , aby prawidłowo czytać ułamki dziesiętne (w moim pliku używam przecinków). Dzięki temu nie muszę tworzyć dwóch różnych skryptów:
# Pod-wstęp
nazwa = "inflation US.csv"
plik = read.csv(nazwa, sep=";", dec=",")
if (ncol(plik)==1) {
plik = read.csv(nazwa, sep=",", dec=".")
}
if (is.numeric(plik[1,1])) {
daty = paste("01.01.", plik[,1], sep="")
} else {
daty = plik[,1]
}
daty = as.Date(daty, tryFormats = c("%d.%m.%Y", "%Y.%m.%d", "%d-%m-%Y", "%Y-%m-%d", "%d/%m/%Y", "%Y/%m/%d"))
#jeżeli ostatnia data przekracza wczorajszą datę, to usuwamy ostatnią obserwację
if (daty[length(daty)]>=Sys.Date()) {
plik = plik[-nrow(plik),]
daty = daty[-length(daty)]
}
fr = 1
kol = 2
st = FALSE
rok = as.numeric(format(daty, "%Y"))
mc = as.numeric(format(daty, "%m"))
dz = as.numeric(format(daty, "%d"))
data_startowa = c(rok[1], mc[1])
cena = as.numeric(plik[,kol])
cena = ts(cena, start = data_startowa, frequency = fr)
if (st == TRUE) {
stopa = diff(cena)/cena[-length(cena)]
} else {
stopa = cena
}
Jak widać, mimo, że okres pierwotnie podany jest w latach, to przekształcam je w pełne daty od pierwszego stycznia i z tego już wyciągam lata. Nowością są też 3 nowe zmienne: fr, kol oraz st, gdzie odpowiednio oznaczają częstość (tu roczna, czyli 1), nr kolumny szeregu czasowego (tu 2, wcześniej na danych stooq.pl było to 5) i zmienna logiczna typu TRUE / FALSE , gdzie TRUE oznacza, że zamieniamy pierwotny szereg w stopy oraz FALSE przeciwnie (tu FALSE).
W części głównej kodu jest bardzo podobnie jak w poprzednim przykładzie:
# Część główna
# test stacjonarności
if (length(stopa)>200) {
kpss.test(stopa, lshort=FALSE)
} else {
kpss.test(stopa)
}
# sprawdzanie autokorelacji
pacf(stopa, plot=FALSE, lag.max=10)
ist_pacf = qnorm((1 + 0.95)/2)/sqrt(sum(length(stopa)))
noquote(c("Istotna autokorelacja będzie od poziomu: ", ist_pacf))
# optymalne arima
arma_stopa = auto.arima(stopa,ic="bic", max.P=7, max.Q=7)
arma_stopa
Efekt:
KPSS Test for Level Stationarity
data: stopa
KPSS Level = 0.43043, Truncation lag parameter = 15, p-value = 0.06404
Partial autocorrelations of series ‘stopa’, by lag
1 2 3 4 5 6 7 8 9 10
0.390 0.158 -0.153 0.048 0.063 -0.063 -0.040 0.116 0.009 -0.049
[1] Istotna autokorelacja będzie od poziomu: 0.124709521934413
ARIMA(1,1,1)
Coefficients:
ar1 ma1
0.3758 -0.9817
s.e. 0.0614 0.0143
sigma^2 = 34.33: log likelihood = -784.25
AIC=1574.5 AICc=1574.6 BIC=1585.02
Inflacja USA okazuje się procesem niestacjonarnym, co podpowiada nam już, że dostaniemy model niestabilny. Najlepszym ARIMA okazał się jednak model bez wyrazu wolnego, ale jest to proces zintegrowany stopnia 1 z AR(1) i MA(1) - w sumie ARIMA(1,1,1). KPSS i ARIMA świetnie się tutaj uzupełniają.
Nie tworzymy w tym momencie modelu ARIMA, tylko zwyczajny ARMA(1,1), co pozwoli nam zobaczyć niejako, jak ta średnia się zmienia w czasie. Ale żeby to było możliwe, musimy dodać wyraz wolny. Następnie testujemy stabilność tego modelu:
# tworzenie optymalnego arma
stopa_ar1 = lag(stopa, k = -1)
stopa_ma = arma_stopa$residuals
stopa_ma1 = lag(stopa_ma, k = -1)
dane = ts.intersect(stopa, stopa_ar1, stopa_ma1)
stopa0 = dane[, "stopa"]
stopa_ar1 = dane[, "stopa_ar1"]
stopa_ma1 = dane[, "stopa_ma1"]
#test Bai-Perrona
bai = breakpoints(stopa0 ~ stopa_ar1 + stopa_ma1 + 1, breaks = 3)
summary(bai)
if (st ==TRUE) {
par(mfrow=c(3,1), mar=c(2,5,2,2))
plot(cena)
} else {
par(mfrow=c(2,1), mar=c(2,5,2,2))
}
plot(bai)
nowy_model = lm(stopa0 ~ breakfactor(bai)-1)
rok0 = as.numeric(format(as.yearmon(time(stopa0)[1]), "%Y"))
mc0 = as.numeric(format(as.yearmon(time(stopa0)[1]), "%m"))
dopas = ts(fitted(nowy_model), start=c(rok0, mc0), frequency = fr)
coef(nowy_model)
plot(stopa0, ylab=colnames(plik)[kol])
lines(dopas, col=4, lwd=3)
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)
Efekt:
Breakpoints at observation number:
m = 1 85
m = 2 39 85
m = 3 39 85 145
Corresponding to breakdates:
m = 1 1860
m = 2 1814 1860
m = 3 1814 1860 1920
Fit:
m 0 1 2 3
RSS 8250 7141 6729 6577
BIC 1584 1571 1578 1595
breakfactor(bai)segment1 breakfactor(bai)segment2
0.3842353 2.3413665

Zwracam uwagę, że w linii
bai = breakpoints(stopa0 ~ stopa_ar1 + stopa_ma1 + 1, breaks = 3)
jest dodany wyraz wolny, a w linii
nowy_model = lm(stopa0 ~ breakfactor(bai)-1)
odjęty. W tym ostatnim tworzymy nowy model, więc tworzony byłby nowy wyraz wolny - a tego już nie chcemy.
Istotna zmiana modelu nastąpiła w 1860 r. Problem z jego interpretacją polega na tym, że nie widzimy w ogóle, czy niestabilność dotyczy wyrazu wolnego, części AR, MA, a może wszystkich na raz. To jest ograniczenie tego testu. Są ścisłe sposoby na jego rozwiązanie, ale na razie oprę się jedynie na KPSS. To znaczy wiem, że KPSS wskazał na niestacjonarność, czyli niestabilność właśnie wyrazu wolnego. Dlatego przetestujmy sam wyraz wolny. Kod będzie prawie ten sam, jedynie zmieni się od testu Bai-Perrona:
#test Bai-Perrona
stopa0 = stopa
bai = breakpoints(stopa0 ~ 1, breaks = 3)
summary(bai)
if (st ==TRUE) {
par(mfrow=c(3,1), mar=c(2,5,2,2))
plot(cena)
} else {
par(mfrow=c(2,1), mar=c(2,5,2,2))
}
plot(bai)
nowy_model = lm(stopa0 ~ breakfactor(bai) - 1)
rok0 = as.numeric(format(as.yearmon(time(stopa0)[1]), "%Y"))
mc0 = as.numeric(format(as.yearmon(time(stopa0)[1]), "%m"))
dopas = ts(fitted(nowy_model), start=c(rok0, mc0), frequency = fr)
coef(nowy_model)
plot(stopa0, ylab=colnames(plik)[kol])
lines(dopas, col=4, lwd=3)
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)
Efekt:
Breakpoints at observation number:
m = 1 166
m = 2 40 135
m = 3 40 77 166
Corresponding to breakdates:
m = 1 1940
m = 2 1814 1909
m = 3 1814 1851 1940
Fit:
m 0 1 2 3
RSS 9864 9317 9110 8906
BIC 1623 1620 1625 1631
breakfactor(bai)segment1 breakfactor(bai)segment2
0.5975301 3.7677778

Teraz już dostaliśmy jasną interpretację, choć zmieniła się data breakpoint: do 1939 r. inflacja w USA wynosiła średnio ok. 0.6%, a po tym roku 3.77%. Data jest nieprzypadkowa z trzech powodów:
1) między 1933 a 1939 wprowadzono szereg programów i reform, zwanych New Deal. Program był tak głęboki, że prawdopodobnie wpłynął na trwały wzrost cen,
2) druga wojna św. wprowadziła poważne zmiany w polityce fiskalno-pieniężnej w wielu krajach. Np. na Wikipedii ang. czytamy, że po 2 wojnie św. idee Keynesa zostały powszechnie przyjęte w krajach zachodnich (aż do lat 70-tych, gdy pojawiła się stagflacja),
3) Bank centralny USA - FED - powstał formalnie w 1913, a zaczął działać w 1914 r. Chociaż jego celem była m.in. kontrola inflacji, to de facto stał się maszyną do jej tworzenia. Jak czytamy w "Tajnikach bankowości" system bankowy zmieniono w ten sposób, że tylko Banki Rezerwy Federalnej mogły drukować banknoty [2]. Pierwszej poważnej ekspansji monetarnej dokonano podczas I wojny św., a drugiej podczas Wielkiego Kryzysu od 1929 do 1933 r.
Na koniec możemy wykonać test homoskedastyczności:
# test homoskedastyczności składnika losowego
czas = c(1:length(stopa))
bptest(stopa ~ czas)
gqtest(stopa ~ 1)
hmctest(stopa ~ 1)
Efekt:
studentized Breusch-Pagan test
data: stopa ~ czas
BP = 18.209, df = 1, p-value = 1.98e-05
Goldfeld-Quandt test
data: stopa ~ 1
GQ = 0.37915, df1 = 123, df2 = 122, p-value = 1
alternative hypothesis: variance increases from segment 1 to 2
Harrison-McCabe test
data: stopa ~ 1
HMC = 0.71341, p-value = 1
Jedynie BP wskazał na zmienność wariancji - zakładam, że wynika to z występowania warunkowej heteroskedastyczności, być może ARCH. Na razie jeszcze tym efektem się nie zajmuję.
Zupełnie z boku: analizę dla tego przykładu warto porównać z artykułem FED do likwidacji?! Wówczas porównałem okres inflacji przed powstaniem FEDu z okresem po jego powstaniu. Chociaż dostajemy różnicę ponad 25 lat, to należy pamiętać, że test Bai-Perrona znajduje punkt zmiany struktury. W przypadku inflacji taki punkt naprawdę nie istnieje, bo przecież ten wpływ FEDu był stopniowy. Test uśrednił więc ten proces do punktu.
Przykład 6. NewConnect
Miesięczne stopy zwrotu od 01.2012 do 10.2022 (źródło: stooq.pl)
Wbrew pozorom nie jest wcale takie proste znaleźć dane finansowe, które mają więcej niż jedną zmianę struktury. Jednak takim przykładem okazuje się osławiony indeks NewConnect. Kod generalnie jest ten sam co dla inflacji, choć zmieniają się założenia (fr, kol, st) i pojawia się nazwa_zmiennej (znaczenie tylko dla wykresu):
# Pod-wstęp
nazwa = "ncindex_m.csv"
plik = read.csv(nazwa, sep=";", dec=",")
if (ncol(plik)==1) {
plik = read.csv(nazwa, sep=",", dec=".")
}
if (is.numeric(plik[1,1])) {
daty = paste("01.01.", plik[,1], sep="")
} else {
daty = plik[,1]
daty = as.Date(daty, tryFormats = c("%d.%m.%Y", "%Y.%m.%d", "%d-%m-%Y", "%Y-%m-%d", "%d/%m/%Y", "%Y/%m/%d"))
#jeżeli ostatnia data przekracza wczorajszą datę, to usuwamy ostatnią obserwację
if (daty[length(daty)]>=Sys.Date()) {
plik = plik[-nrow(plik),]
daty = daty[-length(daty)]
}
#początkowe założenia i ustawienia
fr = 12
st = TRUE
kol = 5
if (st ==TRUE) {
par(mfrow=c(3,1), mar=c(2,5,2,2))
plot(cena, ylab= paste("cena", substr(nazwa, 1, nchar(nazwa)-4)))
nazwa_zmiennej = paste("stopa zwrotu", substr(nazwa, 1, nchar(nazwa)-4))
} else {
par(mfrow=c(2,1), mar=c(2,5,2,2))
nazwa_zmiennej = paste(dimnames(plik[kol])[2], substr(nazwa, 1, nchar(nazwa)-4))
}
rok = as.numeric(format(daty, "%Y"))
mc = as.numeric(format(daty, "%m"))
dz = as.numeric(format(daty, "%d"))
data_startowa = c(rok[1], mc[1])
cena = as.numeric(plik[,kol])
cena = ts(cena, start = data_startowa, frequency = fr)
if (st == TRUE) {
stopa = diff(cena)/cena[-length(cena)]
} else {
stopa = cena
}
# Część główna
# test stacjonarności
if (length(stopa)>200) {
kpss.test(stopa, lshort=FALSE)
} else {
kpss.test(stopa)
}
# sprawdzanie autokorelacji
pacf(stopa, plot=FALSE, lag.max=10)
ist_pacf = qnorm((1 + 0.95)/2)/sqrt(sum(length(stopa)))
noquote(c("Istotna autokorelacja będzie od poziomu: ", ist_pacf))
# optymalne arima
arma_stopa = auto.arima(stopa,ic="bic", max.P=3, max.Q=3)
arma_stopa
# ODTĄD ZBĘDNE
# tworzenie optymalnego arma
stopa_ar1 = lag(stopa, k = -1)
stopa_ar2 = lag(stopa, k = -2)
stopa_ma = arma_stopa$residuals
stopa_ma1 = lag(stopa_ma, k = -1)
stopa_ma2 = lag(stopa_ma, k = -2)
dane = ts.intersect(stopa, stopa_ar1, stopa_ar2, stopa_ma1, stopa_ma2)
stopa0 = dane[, "stopa"]
stopa_ar1 = dane[, "stopa_ar1"]
#stopa_ar2 = dane[, "stopa_ar2"]
stopa_ma1 = dane[, "stopa_ma1"]
#stopa_ma2 = dane[, "stopa_ma2"]
# DOTĄD ZBĘDNE
stopa0 = stopa
#test Bai-Perrona
#bai = breakpoints(stopa0 ~ stopa_ar1 + stopa_ar2 + stopa_ma1 + stopa_ma2, breaks = 4)
bai = breakpoints(stopa0 ~ 1, breaks = 4)
summary(bai)
plot(bai)
nowy_model = lm(stopa0 ~ breakfactor(bai) - 1)
rok0 = as.numeric(format(as.yearmon(time(stopa0)[1]), "%Y"))
mc0 = as.numeric(format(as.yearmon(time(stopa0)[1]), "%m"))
dopas = ts(fitted(nowy_model), start=c(rok0, mc0), frequency = fr)
coef(nowy_model)
plot(stopa0, ylab= paste(nazwa_zmiennej, substr(nazwa, 1, nchar(nazwa)-4)))
lines(dopas, col=4, lwd=3)
par(mfrow=c(1,1), mar=c(5, 4, 4, 2) + 0.1)
#test homoskedastyczności składnika losowego
czas = c(1:length(stopa))
bptest(stopa ~ czas)
gqtest(stopa ~ 1)
hmctest(stopa ~ 1)
Efekt:
KPSS Test for Level Stationarity
data: stopa
KPSS Level = 0.12962, Truncation lag parameter = 4, p-value = 0.1
Warning message:
In kpss.test(stopa) : p-value greater than printed p-value
Partial autocorrelations of series ‘stopa’, by lag
0.0833 0.1667 0.2500 0.3333 0.4167 0.5000 0.5833 0.6667 0.7500 0.8333
0.189 0.028 0.043 -0.024 0.104 0.189 0.088 -0.240 -0.074 0.117
[1] Istotna autokorelacja będzie od poziomu: 0.172565206655387
Series: stopa
ARIMA(0,0,0) with zero mean
sigma^2 = 0.004339: log likelihood = 167.85
AIC=-333.7 AICc=-333.67 BIC=-330.84
Breakpoints at observation number:
m = 1 102
m = 2 83 102
m = 3 62 83 102
m = 4 41 62 83 102
Corresponding to breakdates:
m = 1 2020(7)
m = 2 2018(12) 2020(7)
m = 3 2017(3) 2018(12) 2020(7)
m = 4 2015(6) 2017(3) 2018(12) 2020(7)
Fit:
m 0 1 2 3 4
RSS 0.5597 0.5440 0.4640 0.4562 0.4514
BIC -325.9824 -319.9147 -330.7315 -323.1976 -314.8319
breakfactor(bai)segment1 breakfactor(bai)segment2 breakfactor(bai)segment3
-0.008154642 0.063809295 -0.021800546
studentized Breusch-Pagan test
data: stopa ~ czas
BP = 7.701, df = 1, p-value = 0.005519
Goldfeld-Quandt test
data: stopa ~ 1
GQ = 6.0217, df1 = 64, df2 = 63, p-value = 1.005e-11
alternative hypothesis: variance increases from segment 1 to 2
Harrison-McCabe test
data: stopa ~ 1
HMC = 0.14108, p-value < 2.2e-16
.xlsx%20-%20Excel.png)
Przykład NewConnect jest o tyle wyjątkowy, że KPSS wskazuje na stacjonarność stóp zwrotu, optymalny jest ARMA(0,0,0) z zerową średnią, a jednocześnie wyraz wolny jest niestabilny:
* do końca 2018 r. wynosił -0,8%,
* do lipca 2020 +6,4%
* do dziś -2,2%.
Tak się zmieniała się średnia miesięczna stopa zwrotu. Dlaczego więc KPSS nie potwierdza tego? Odpowiedź już była podana przy badaniu inflacji - nie wiemy czy przypadkiem między 2018 a 2020 nie powstał proces ARMA, który następnie znowu zanikł tak że sumarycznie BIC wskazuje optimum przy zerowych autoregresjach. Można by jeszcze pomyśleć o wpływie zmian wariancji na stabilność - wszystkie testy na wariancję dowodzą jej zmienności w czasie. Jednakże zarówno KPSS jak i test Bai-Perrona są odporne na heteroskedastyczność. Stąd KPSS nie wykrył zmian w rozkładzie stóp, natomiast Bai-Perron wykrył, bo jest wrażliwy na budowę modelu, który w dodatku musi być liniowy.
Analiza, którą przedstawiłem ma szczególne znaczenie przy prognozowaniu, gdyż widzimy, że niektóre procesy są niestabilne na poziomie zarówno średniej, jak i wariancji. W przypadku inflacji USA powinniśmy po pierwsze ustawić "uczenie się" parametrów przez program od roku 1941, a po drugie rozważyć model klasy (G)ARCH zamiast ARMA. Te pierwszy obejmuje drugi i czasem niepotrzebnie nazywany jest ARMA-GARCH. Z kolei poświęcanie czasu na NewConnect wydaje się złym pomysłem dopóki średnia jest ujemna - i to nie do końca z powodu bessy, bo to giełda, która od początku swojej historii spadła o 70% (od 2012 o ok. 30%).
Literatura:
[1] Bai J., Perron P. (2003), Computation and Analysis of Multiple Structural Change Models, Journal of Applied Econometrics, 18, 1-22 ;
[2] Rothbard, M. N.., Tajniki bankowości, Warszawa 2007, s. 254.
Brak komentarzy:
Prześlij komentarz