Autorzy podkreślają, że nie wystarczy tylko raz zastosować model, który wyprognozuje moment krytyczny i czekać do tego okresu. Jeżeli model wskazuje moment krytyczny za rok, to w ciągu tego roku może się struktura zmienić, więc należy aktualizować model. To jest dodatkowy stochastyczny element ich teorii.
Jest wiele różnych wersji modelu log-periodycznego, ale właściwie wszędzie pojawia się wzór, który w uproszczeniu wyprowadzę idąc tokiem rozumowania Kutnera [5]. Ogólnie biorąc musimy połączyć dwie koncepcje: jedną ze statystyki - rozkład Levy'ego-Pareto i jedną z fizyki - temperatury krytycznej. Podzielę to na dwie części.
1) Rozkład Pareto-Levy'ego jest związany z grubymi ogonami, które dobrze są nam znane, więc nie będę się o nim rozpisywał. Jeśli cenę akcji P(t) da się opisać rozkładem proporcjonalnym do:
(1)

to mamy do czynienia z rozkładem Pareto dla t > 0. Zwróćmy uwagę, że z jednej strony wzór (1) opisuje prawdopodobieństwo (zmiany) ceny, ale z drugiej wartość oczekiwana będzie proporcjonalna do tego prawdopodobieństwa. Zgodnie ze wzorem (1) dla każdego okresu t mamy inne prawdopodobieństwo. Gdybyśmy przemnożyli obie strony przez cenę P(t), to dostalibyśmy wartość oczekiwaną ceny dla okresu t. Stąd w miejsce prawdopodobieństwa możemy wstawić po prostu oczekiwaną cenę.
Znaną własnością rozkładu Pareta jest równanie skalowania:
(2)

gdzie L^a to czynnik skalujący funkcję P(t).
Najogólniejszym rozwiązaniem osobliwym (tzn. rozwiązaniem, które nie posiada zapisu zgodnego z całką ogólną - gdyż mamy tu do czynienia z równaniem różniczkowym zwyczajnym) równania skalowania (2) jest
(3)

(4)

2) W złożonych systemach istnieją różne fazy, w których pewne parametry fizyczne / ekonomiczne pozostają względnie stałe. W fizyce takimi parametrami są temperatura lub ciśnienie. Np. faza topnienia następuje w temperaturze poniżej 0 stopni Celsjusza, faza zamarzania - od 0 stopni wzwyż, a faza wrzenia - 100 stopni. Hołyst, Poniewierski i Ciach definiują fazę jako "makroskopowo jednorodny stan układu, odpowiadający danym parametrom termodynamicznym." [6]. Dalej: "Proces przekształcania się jednej fazy w inną nazywa się przejściem fazowym lub przemianą fazową". Różne fazy mogą ze sobą współistnieć (stąd często w przejściach między jesienią a zimą oraz zimą i wiosną utrzymuje się temperatura 0 stopni), ale w przypadku ciągłych przejść fazowych, jedna faza przechodzi bezpośrednią w inną. "Ciągłe przejścia fazowe mają na ogół charakter przemiany typu porządek-nieporządek. Przemianą tego typu jest np. przejście paramagnetyk-ferromagnetyk, występujące w materiałach magnetycznych, takich jak żelazo. Uporządkowanie dotyczy tutaj mikroskopowych momentów magnetycznych umiejscowionych w węzłach sieci krystalicznej. W fazie paramagnetycznej orientacje momentów magnetycznych są chaotyczne, więc jeśli nie ma zewnętrznego pola magnetycznego, to magnetyzacja układu znika. Jest tak wówczas, gdy temperatura układu jest wyższa od pewnej charakterystycznej temperatury Tc, zwanej temperaturą Curie. Natomiast w temperaturze niższej od Tc, mikroskopowe momenty magnetyczne porządkują się spontanicznie wzdłuż pewnego wspólnego kierunku, i magnetyzacja przyjmuje wartość różną od zera. Istotne jest to, że magnetyzacja pojawia się spontanicznie, bez udziału zewnętrznego pola magnetycznego, jako efekt oddziaływania pomiędzy mikroskopowymi momentami magnetycznymi." Tak więc temperatura Curie to temperatura krytyczna dla przemian magnetycznych, która charakteryzuje jednocześnie obszar krytyczny.
Kutner pisze, że w obszarze krytycznym większość wielkości fizycznych zmienia się w zależności od temperatury T według prawa potęgowego:
(5)

gdzie Tc to temperatura krytyczna.
Aby zastosować pojęcie temperatury krytycznej do rynku, zastąpimy temperaturę T czasem t. Jest to chyba najważniejszy moment w zrozumieniu zastosowania fizyki do giełdy: temperaturę określamy jako wielkość proporcjonalną do czasu.
Punkt 1, który jest czysto matematyczny, wydaje się zupełnie logiczny, ale zawiera założenie, że szukamy tylko rozwiązania osobliwego (a nie ogólnego). To założenie jest potrzebne, aby spełniona została interpretacja fizyczna z pktu 2, mianowicie istnienia temperatury krytycznej, a więc dla ekonofizyki - czasu krytycznego. Natomiast czas krytyczny jest potrzebny po to, aby spełniona została koncepcja "racjonalnej (lub ograniczenie racjonalnej) bańki spekulacyjnej".
Technicznie rzecz biorąc zmienna (t - tc) stanie się ujemna, bo wielkość tc z założenia ma być większa od każdego t w którym operujemy: model ma prognozować przyszłość, a nie przeszłość. Dlatego od razu użyjemy zmiennej -(t-tc) = (tc - t). Następnie, nie interesuje nas za bardzo wykres z argumentami tc-t, bo przecież chcemy widzieć normalny przebieg czasu na wykresie. Punkt krytyczny tc jest parametrem do oszacowania, a więc stałą. Dlatego stworzymy zmienną P(t) zamiast P(tc - t). Stąd za P(tc - t) podstawimy P(t). Jeżeli uprościmy szereg Fouriera w (4) do pierwszego rzędu, dostaniemy w końcu model log-periodyczny:
(6)
(7)

Do oszacowania parametrów zastosuję NMNK w Gretlu, której praktyczne zastosowanie szczegółowo opisałem w poprzednim artykule
Nieliniowa metoda najmniejszych kwadratów dla modelu trendu. Algorytm Levenberga–Marquardt może w końcu przydać się do czegoś praktycznego, bo poprzednie modelowanie trendu nieliniowego za pomocą funkcji wykładniczej, jak pokazałem, nie ma większego sensu. W przypadku skomplikowanych nieliniowych trendów z cyklami i krachami sprawa wygląda zupełnie inaczej. Tak więc algorytm jest analogiczny do tamtej funkcji. Algorytm Levenberga–Marquardt został także użyty przez Sornette'a i Sammisa [7], którzy jako jedni z pierwszych używali modelu (6) - ich pierwsze próby dotyczyły przewidywania trzęsień ziemi.
Kiedy zacząłem testować (6) szybko okazało się, że wiele zależy od ustawienia początkowych parametrów: a, d , w i tc. Algorytm wprawdzie sam je szacuje, ale potrzebuje danych wejściowych. W wielu sytuacjach model nie zbiega do wybranej funkcji. Stąd warto posłużyć się wynikami uzyskanymi przez innych badaczy. Drożdż, Grummer, Ruf i Speth [8] empirycznie dowodzą, że dla większości znaczących, historycznych finansowych zdarzeń, preferowana wartość parametru L = 2. Na podstawie wzoru (7) dostaniemy więc, że preferowane w równa się ok. 9,06. Następnie, w [9] autorzy stwierdzają, że jeśli 0 < a < 1, to cena w skończonym czasie dojdzie do tc. I jeszcze na koniec znalazłem jedną z najnowszych publikacji Sornette'a i Filimonova [10], którzy po zebraniu wielu danych, skompilowali parametry do następujących ograniczeń:
0.1 ≤ a ≤ 0.9,
6 ≤ w ≤ 13,
|C| < 1
B < 0.
Jeśli chodzi o ostatnią nierówność, to jest prawdopodobne, że B > 0 dla trendu spadkowego - znalazłem w [11]. Piszę prawdopodobnie, bo autor popełnił tam błąd we wzorze na w, więc nie mam pewności czy gdzieś indziej nie ma błędu.
Jeśli chodzi o początkowe tc, to jak sądzę preferowane będzie T+e gdzie T to liczba obserwacji, a e to liczba dni, po której spodziewalibyśmy się załamania (lub ewentualnie zmiany bessy na hossę) od momentu T.
Modele log-periodyczne w trzech ostatnich wspomnianych pracach opierają się na logarytmach ceny, czyli mają postać:
(8)
Przykład 1. WIG: notowania dzienne 1994-13.01.2017 (T = 5704 obserwacji). Przy preferowanych parametrach modelu nie mogłem otrzymać. Dopiero po wpisaniu następujących wstępnych parametrów:
A = 1, B = -1, C = 0.5, a = 0.5, w = 15, d = -1, tc = 5800 uzyskałem model:

Oszacowane tc = 7405,03 (p-value 1%). Z tego punktu widzenia krach nam nie straszny: 7405 - 5704 = 1701 dni pozostało do ewentualnego krachu. Jest to oczywiście tak odległa perspektywa, że nie ma sensu brać tego na poważnie.
Zamiast tego cofnijmy się do końca czerwca 2007. Liczba danych = 3316. Ustawione preferowane początkowe parametry wystarczyły: A = 1, B = -1, C = 0.5, a = 0.5, w = 9.06, d = -1, tc = 3317. Tym razem model robi wrażenie:

Otóż oszacowane tc wyniosło 3321,68 (p-wartość 1%). Natomiast faktyczna bessa zaczęła od 3322 dnia (7.07.2007). Trafiło w punkt. W momentu prognozy do oszacowanego dnia załamania pozostało 5-6 dni (3321,68 - 3316).
Wydawałoby się, że potrafimy przewidywać przyszłość. Nie do końca. Gdy ustawimy dane do końca maja (3296 danych), to dostaniemy tc = 3301,19, czyli o 20 dni za wcześnie, ale 5 dni od dnia, w którym dokonalibyśmy prognozy (3301-3296=5). To samo, gdy ustawimy datę końcową koniec kwietnia (3275): dostaniemy tc = 3282,11. Tym razem jednak czas do prognozowanego krachu jest nieco większy (3282-3275=7 dni). Weźmy jeszcze koniec grudnia 2006 (3192 danych). Dostałem tc = 3213,42. Czas do szacowanego krachu jest znacznie większy (3213-3192=21 dni).
Zwracam uwagę, że nie ma znaczenia jaką ustawimy datę początkową tc, zawsze wyjdzie to samo. Odpowiednia wstępna wielkość tc jest potrzebna tylko po to, by algorytm "załapał" ten parametr. W powyższych przykładach najczęściej wpisywałem tc = T+1.
Tak więc decydującym jest ciągła aktualizacja modelu (8), tak jak wcześniej podkreślali to Sornette i Johansen. A mimo to możemy uzyskiwać fałszywe sygnały, o czym przekonamy się, generując prognozę w dniu poprzedzającym początek bessy, czyli 6.07.2007: znów przesunęłaby się prognoza krachu o ok. 5-6 dni (T = 3321 oraz tc wyniósłby 3326,6, czyli 3326,6-3321=5,6). Ta sytuacja będzie codziennie się powtarzać, przez cały lipiec, a nawet w kolejnych miesiącach.
Przykład 2. Mbank: roczne 1994-2015 (T = 22 obserwacje). Wróćmy jeszcze raz do mbanku, który ostatnio modelowałem regresją nieliniową, tyle że zwykłą funkcją wykładniczą. Tym razem możemy znaleźć o wiele dokładniejsze przewidywania przy tych samych danych. Aby dostać model użyłem: A = 1, B = -1, C = 0.5, a = 0.5, w = 16, d = -1, tc =23. NMNK oszacował tc = 24,87, a wykres jest taki:

Jednakże obecnie możemy już dodać rok 2016. Pytanie czy wielkość tc zmieni się? Użyłem tych samych wstępnych parametrów. NMNK oszacował ponownie tc = 24,87, a wykres jest taki:

Czyli wg modelu mamy spodziewać się załamania za 1-2 lata.
Aby jednak nie napawać się zbytnio optymizmem, pokażę teraz, że model (8) kiepsko radził sobie z dziennymi wahaniami.
Przykład 3. Mbank: dzienne 1994-koniec 2013 (T = 4941 obserwacji): Wpisałem następujące wstępne parametry:
A = 1, B = -1, C = 0.5, a = 0.5, w = 9.06, d = -1, tc = 5000. Uzyskałem model o wykresie:

Ogólnie model na rysunku wydaje się całkiem dobry. Parametr krytyczny tc został oszacowany na 5507,77 i jest istotny statystycznie na poziomie 1% (tak samo jak reszta parametrów). czyli krachu powinniśmy oczekiwać po 5507,77-4941 = 566,77 dniach. Dodatkowo: Błąd standardowy reszt = 0,252757, Skorygowany R-kwadrat 0,890034. Co więc się stało po tym czasie? Poniżej zamieściłem ten sam wykres powiększony o 567 dni.

A do dziś mamy:

Już dawno po "krachu". Model powinien przewidywać go w momencie gdy tworzyliśmy prognozę, bo od tego momentu trend się zmienił. Ale można byłoby starać się obronić model, bo kurs od momentu wykonania prognozy, czyli końca 2013, przez kolejne pół roku stał w miejscu, więc należałoby aktualizować model i być może wtedy uzyskalibyśmy moment wyjścia? Nic z tego. Przesuwając dane do końca lipca 2014 (5087) dostaniemy tc = 5588,87 i wykres:

Zatem czekalibyśmy, bo przecież różnica 5589-5087 = 502, czyli jeszcze ok. 2 lata dni roboczych.
Powyższe bardzo skrótowe testy pokazały, że model log-periodyczny może rzeczywiście służyć jako wskaźnik "temperatury rynku" czy zwiększonej niepewności dla racjonalnego inwestora, tak że spekulacja zaczyna przeważać nad wyceną fundamentalną. Ale kontrowersyjne jest twierdzenie, że pozwala przewidywać zmianę trendu. Możliwe, że rynek zachowuje się tak jak to opisuje teoria Sornette-Johansena [2, 3, 4]. Fakt pozostaje faktem, że analiza WIG wykazała, że im bliżej był dzień zmiany trendu w 2007, tym model (8) wskazywał na coraz bliższą datę od momentu prognozy, przy czym krańcowym czasem pozostałym do załamania był mniej więcej 1 tydzień.
Na sam koniec stworzę prognozę dla indeksu USA dla częstości rocznej i miesięcznej.
Przykład 4. S&P500 roczne: 1933-2016 (T=84 dane). Wstawiłem standardowe parametry, w tym tc = 85. W odpowiedzi otrzymałem tc = 94,355. Czyli do krachu stulecia jeszcze 10 lat.

Najgorsze rezultaty model osiągnął w drugiej połowie lat 90 XX w. Można to nawet potraktować jako argument za przewartościowaniem akcji w tym okresie.
Przykład 5. S&P500: miesięczne 1933-koniec 2016 (T=1008). Ustawienia: identyczne co poprzednio, ale nie chciało wejść z tc = 1009 i dopiero dla tc = 1020 "załapało". Prognoza tc = 1126,55, a wykres przedstawia się:
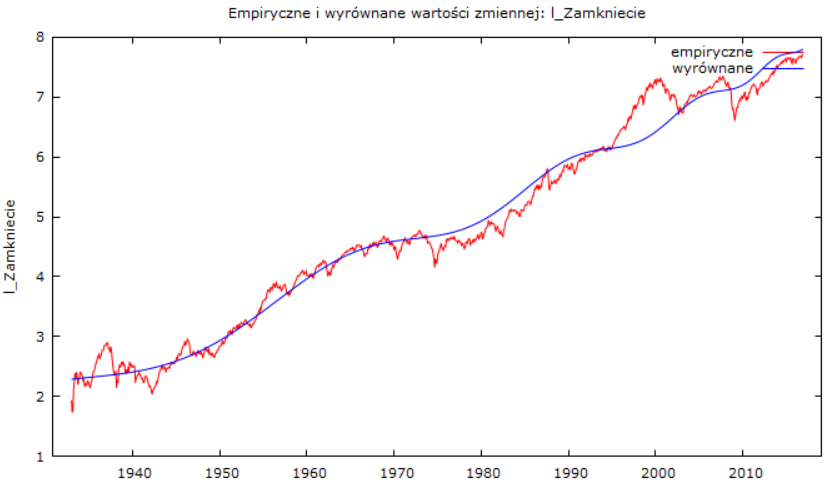
W powiększeniu ostatnich okresów widać, że model wchodzi w fazę wzrostu:

Jeżeli prognoza się sprawdzi, to czeka nas krach w USA za 119 miesięcy, czyli za 119/12 = 9,9 lat. Prognoza miesięczna idealnie więc pokrywa się z prognozą roczną.
Literatura:
[1] Sornette, D., Johansen, A. - Modeling the stock market prior to large crashes, 1999,
[2] Sornette, D., Johansen, A. - Critical Market Crashes, 1999,
[3] Sornette, D., Johansen A., Ledoit, O. - Predicting Financial Crashes Using Discrete Scale Invariance, Feb 2008,
[4] Sornette, D., Johansen A. - Significane of log-periodic precursors to financial crashes, Feb. 1, 2008,
[5] Kutner, R., Wprowadzenie Do Ekonofizyki: Niegaussowskie Procesy Stochastyczne Oraz Niedebye'Owska Relaksacja W Realu. Elementy teorii ryzyka rynkowego wraz z elementami teorii zdarzeń ekstremalnych, W-wa czerwiec 2015,
[6] Hołyst, R., Poniewierski A., Ciach A., Termodynamika Dla Chemików, Fizyków I Inżynierów, Październik 2003,
[7] Sornette, D., Sammis, C., - Complex critical exponents from renormalization group theory of earthquakes Implications for earthquake predictions, 1995,
[8] Drożdż S., Grummer, F., Ruf, F., Speth, F. - Log-periodic self-similarity an emerging financial law, 2002,
[9] Fantazzini, D. ,Geraskin, P., - Everything You Always Wanted to Know about Log Periodic Power Laws for Bubble Modelling but Were Afraid to Ask, Feb 2011,
[10] Sornette, D., Filimonov, V. - A Stable and Robust Calibration Scheme of the Log-Periodic Power Law Model, 2013,
[11] Górski, M. - Zastosowanie Teorii Log-Periodyczności W Prognozowaniu Krachów Giełdowych, 1/2014.


















