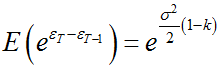- Dzięki temu zmniejszy się różnica między wynagrodzeniem średnim, a minimalnym. Zbliżymy się do pożądanych 50 proc. Dobra sytuacja na rynku pracy powinna przekładać się także na wzrost wynagrodzeń.
Reszta na stronie: http://www.regiopraca.pl/portal/rynek-pracy/wiadomosci/placa-minimalna-2017-2000-zlotych-od-pierwszego-stycznia
Dobrze, że dodano komentarz dr Małgorzaty Starczewskiej-Krzysztoszek, głównej ekonomistki Konfederacji Lewiatan:
"Tak wysoki wzrost płacy minimalnej z 1850 zł do 2000 zł może być bardzo niekorzystny dla mikrofirm, które są zwykle mniej efektywne, a średnie wynagrodzenie w nich niewiele przekracza 50 proc. płacy w dużych firmach, a jednocześnie jest tylko trochę wyższe niż płaca minimalna. Dla 96 proc. mikrofirm wysoka podwyżka płacy minimalnej będzie problemem i skłoni przynajmniej część z nich do przejścia do szarej strefy."
Na http://demotywatory.pl/4589316/WIG-20-a-PIS pojawił się swego czasu taki obrazek:

Choć od tego czasu giełda się poprawiła, to nadal jest poniżej punktu, od którego PIS przejął władzę.
Wzrost pensji minimalnej najprawdopodobniej spowoduje, że giełda polska będzie spadać jeszcze co najmniej przez 2 lata. Dlaczego tyle? Nie chodzi tu o kolejne wybory parlamentarne, ale właśnie o wynagrodzenie minimalne. Nieco rozświetlę ten temat.
Bardzo przyjemne (bo krótkie) podsumowanie poglądów o płacy minimalnej w ekonomii przedłożył Szarfenberg [1] w 2014 r. Zaczyna od motta:
„... płaca minimalna jest przede wszystkim sprawą polityczną, a koncentrowanie uwagi na modelach ekonomicznych, jakby to one miały kierować procesem politycznym jest całkowicie chybione” Oren M. Levin-Waldman
Nie wiem kto to jest Levin-Waldman, choć google stwierdza, że to spec od ekonomii politycznej. Może i coś w tym jest.
Szarfenberg podaje cały szereg argumentów zwolenników jak i przeciwników płacy minimalnej. Nie będę tu ich przytaczał, bo artykuł Szarfenberga jest dostępny w internecie (link podałem w przypisach).
Ogólnie można powiedzieć, że obrońcy płacy minimalnej albo nie rozumieją jak funkcjonują mechanizmy rynkowe (i w ogóle świat) albo wydaje im się, że wszyscy pracodawcy żyją w zmowie, maksymalizując zyski poprzez maksymalne obniżanie kosztów, czyli wynagrodzeń. Zatem pracodawcy nie konkurują między sobą jak to mówi pre-klasyczna ekonomia, tylko się wzajemnie wspierają. Idąc tym tropem, można byłoby rozszerzyć tę spiskową teorię i powiedzieć, że na rynku jest tylko jeden pracodawca - i oczywiście nie-Polak, tylko Żyd albo Niemiec.
Jasne - są duże sieci monopolistyczne, które rzeczywiście wykorzystują swoją siłę i na przykład dzięki tzw. korzyściom skali ceny ich produktów są niższe niż w sklepach detalicznych, które niewątpliwie na tym cierpią. Ale jakoś obrońcy wynagrodzenia minimalnego nie mają z tym problemu. W końcu im niższa cena tym lepiej! Czysta hipokryzja albo po prostu krótkowzroczność.
A jeżeli nawet pracodawcy nie są w zmowie, to - według socjalistycznych orędowników płacy minimalnej - ludzie są za słabi by sami wymagać godziwego wynagrodzenia, dlatego państwo ma ich za to wyręczać. Jakie to przyjemne - nowi na rynku pracy podczas rozmowy kwalifikacyjnej nie muszą się głowić nad własną wartością rynkową, bo państwo już ich wyceniło.
Szarfenberg waży te dwa przeciwstawne stanowiska, przywołując przykładowe badania statystyczne - będące głosami zarówno za jak i przeciw. Do tego drugiego nurtu zaliczymy wnioski S. Borkowskiej [6]:
„Ogólnie rzecz biorąc, wzrost płacy minimalnej najsilniej oddziałuje na spadek zatrudnienia młodzieży (do 24 roku życia), a w szczególności młodocianych (do 18–19 roku życia)”
Szarfenberg chcąc zachować obiektywizm wskazuje na jedną pozycję w literaturze ekonomicznej, w której autorka pozytywnie ocenia wpływ płacy minimalnej. Cytuje tutaj C. Saget [2]:
„Analiza danych daje silne wsparcie twierdzeniu, że płaca minimalna może mieć pozytywne rezultaty w łagodzeniu ubóstwa poprzez poprawę warunków życia pracowników i ich rodzin, nie mając negatywnego wpływu na zatrudnienie”
Zajrzałem do tej pracy. Saget bada jedynie kraje rozwijające się z Afryki, Ameryki Łacińskiej i Azji. Te z Azji, jakby ktoś pytał, to: Azerbejdżan, Turcja, Filipiny, Tajlandia i Syria. Nie wiem jak inni, ale dla mnie wszelkie dane dot. aktywności ekonomicznej z tych krajów powinny być traktowane z założenia jako podejrzane. Ale nawet pomijając te podejrzenia jedna rzecz dyskwalifikuje ten artykuł. W wersji, która jest darmowa w internecie (i jak sądzę aktualna) autorka pokazuje tabelę z wynikami relacji między biedą a minimalnym wynagrodzeniem:

Częściowy komentarz Saget do tej tabeli:
"The relationship between the minimum wage and poverty remains when the level of development, as approximated by GDP/capita and location are introduced as explanatory variables.5 This can be seen from the bottom of Table 5 (second column), which relates the share of population in poverty to GDP per capita in dollars GDPCAP, minimum wage in dollars MINWDOL, average wage in
dollars AWAGEDOL and four regional dummies."
Zaznaczyłem pogrubioną czcionką "four", bo Saget odnosi się tu do 4 regionów: Afryki Północnej, Afryki Południowej, Ameryki Łacińskiej i Azji. Są to zmienne sztuczne w modelu regresji, tzw. dummy variables albo dummies, które przybierają wartość 0 (fałsz) lub 1 (prawda), wskazując tym samym istotność wpływu danego regionu. Jednak w rzeczonej dolnej części tablicy są tylko 3 z tych regionów, tak jakby 4-ta gdzieś się zgubiła (brakuje Azji). W dodatku analiza zawiera bardzo małą liczbę obserwacji. To wszystko sprawia, że analizy Saget nie można brać na poważnie.
Ludzie przeczytają takie prace niezbyt dokładnie, a potem się nimi posługują jako argumentami na poparcie swojej tezy. Problem naszych czasów polega na tym, że od dziecka ludzie uczeni są, że każdy może wypowiadać się w kwestii ekonomii tak samo jak polityki. Ekonomię traktuje się prawie na równi z polityką. Mamy przecież "ekonomię polityczną". Tak więc premier czy inny polityk nie wie o czym mówi, a ludzie tego słuchają. Ale nie chodzi tylko o polityków, ale też samych ekonomistów. Są różne poziomy ekonomistów. Nie mając przygotowania ani wiedzy, ludzie nie odróżnią eksperta od pseudo-eksperta. Dobrym przykładem jest następujące ćwiczenie: wpisałem w google frazę "wplyw placy minimalnej w polsce". Na drugim miejscu pojawił się artykuł Wielki mit płacy minimalnej. Jej podniesienie nie zwiększa bezrobocia. Czytanie tego to strata czasu, ale przytoczę jeden fragment:
"– Amerykanie potrafili dostrzec pozytywny wpływ racjonalnej polityki płacowej na rozwój gospodarczy. Henry Ford już w 1914 r. wprowadził w swojej firmie minimalną płacę dzienną w wysokości 5 dol. Była to wysoka kwota, bo np. samochód, który wówczas był towarem luksusowym, kosztował 450 dol. Początkowo wszyscy twierdzili, że Ford zbankrutuje, ale dzięki temu wyraźnie wzrosła wydajność pracy w firmie."
Szok, żenada, jak to nazwać? Nie wiem czy cytowany "profesor" czy po prostu autor tego artykułu nie rozumie czym jest płaca minimalna. Gdyby przedsiębiorca mógł sam ustalać wynagrodzenie dla swojego pracownika, to zaprzeczałoby to właśnie idei płacy minimalnej, którą socjalistyczny autor próbuje nam narzucić. Takie artykuły, które pojawiają się nie tylko na pierwszych stronach, ale na pierwszych miejscach wyszukiwarki, stanowią właśnie przyczynę zacofania społeczeństwa w zakresie wiedzy ekonomicznej.
Co w takim razie mówią poważni ekonomiści na zadany temat? Analizując to zagadnienie dla USA, Sabia i Burkhauser w 2010 [3] stwierdzają, że "stanowe i federalne minimalne płace zwiększane pomiędzy 2003 a 2007 nie miały żadnego wpływu na poziom stopy biedy". Dodatkowo również zanotowali negatywny wpływ spadku zatrudnienia. Ich konkluzja brzmi:
"Nasze wyniki sugerują, że wzrost minimalnej płacy stanowi nieodpowiedni sposób do pomocy ubogim pracującym".
Przyglądając się innym badaniom ci sami autorzy zdradzają:
"Ostatnio przeprowadzano wiele badań na temat wpływu wzrostu minimum płacy na dochody i biedę (zob. np. Card i Krueger 1995; Addison i Blackburn 1999; Neumark i Wascher 2002; Gundersen i Ziliak 2004; Neumark, Schewitzer i Wascher 2004, 2005; Burkhauser i Sabia 2007; Sabia 2008) i wszystkie poza jedną zauważały, że podwyżki minimalnych płac nie miały w przeszłości żadnego efektu."
Tym wyjątkiem był artykuł Addisona i Blackburna z 1999 [4]. Przejrzałem go. Mimo że faktycznie ogólne rezultaty przemawiały za ujemną korelacją pomiędzy wzrostem minimalnego wynagrodzenia a stopą biedy, to gdy bliżej się im przyjrzymy, przestają być już tak oczywiste. Najbardziej uderzające jest to, że gdy autorzy podzielili badanie na 2 okresy 1983-1989 oraz 1989-1996, to tylko w drugim okresie minimalne wynagrodzenie miało istotny statystycznie wpływ. Cały efekt wynikał więc z drugiego okresu. Trochę pachnie przypadkiem.
Wszystkie powyższe artykuły skupiały się na szukaniu związku między zmianami min. płacy a poziomem biedy, najczęściej liczonej w dochodach rodziny. Prostszym sposobem jest zmierzenie po prostu poziomu bezrobocia wśród młodych grup zawodowych, których głównie dotyczy ta kwestia. Artykułów zagranicznych o tym jest cała masa. Można też znaleźć artykuły dotyczące Polski; np. jest artykuł B. Dańskiej-Borsiak z 2014 r. , dostępny w internecie [5]. Autorka dochodzi do następującego wniosku:
"Wykazano, że zarówno poziom płacy minimalnej, jak i jej stosunek do wynagrodzenia przeciętnego są przyczynami w sensie Grangera liczby pracujących w wieku 15-29 lat w Polsce w okresie 1990-2013. Stwierdzono również, ceteris paribus, negatywny wpływ obu wymienionych zmiennych na liczbę młodych pracujących, przy czym w przypadku płacy minimalnej ten efekt jest opóźniony o jeden rok. Prognozy wariantowe do roku 2020 wskazują największą liczbę pracujących, jeśli płaca minimalna nie przekroczy 40% wynagrodzenia przeciętnego przy jednoczesnym utrzymaniu obecnego tempa wzrostu płacy minimalnej."
Ostatnie dane GUS wskazują, że przeciętne wynagrodzenie brutto wyniosło w 2 kw. 2016 ponad 4000 zł. Oznacza to, że minimalna płaca obecnie jest za wysoka i nie powinna przekroczyć 1600 zł brutto.
Równie ważne jest ostatnie zdanie w cytowanej wyżej pracy:
"Uzyskane rezultaty mogą stanowić głos w powracającej co roku dyskusji na temat podnoszenia płacy minimalnej. Postulowane przez związki zawodowe ustalenie jej na poziomie 50% wynagrodzenia przeciętnego wydaje się bardzo niekorzystne z punktu widzenia poziomu zatrudnienia."
Od 2017 będziemy mieć już poziom 50%. Od 2018 r. należy się więc spodziewać wzrostu bezrobocia. Ktoś mógłby spytać, że skoro obecnie min płaca > 40% przeciętnej płacy, to dlaczego bezrobocie jest obecnie tak niskie? Tylko że jej skok nastąpił w 2009 r., a potem ją jeszcze w latach 2012-2013 podnoszono:

Źródło: wikipedia. Link: https://pl.wikipedia.org/wiki/P%C5%82aca_minimalna#/media/File:Minimalne_wynagrodzenie_jako_odsetek_przecietnego_wynagrodzenia_w_gospodarce_narodowej.png
Po roku 2013 też nastąpił wzrost stosunku minimalnej do przeciętnej płacy, ale spowolnił. Wg założeń PIS wzrost ten znów przyspieszy od 2017.
Dla porównania bezrobocie wśród młodych:

Źródło: http://rynekpracy.org/x/946883
Znając giełdę dyskontującą PKB (które jest ujemnie skorelowane z bezrobociem), spadki zaczną się wcześniej.
Literatura:
[1] R. Szarfenberg, Kontrowersje wokół podniesienia płacy minimalnej, Instytut Polityki Społecznej Uniwersytet Warszawski, 2014, link: rszarf.ips.uw.edu.pl/pdf/placmin.pdf
[2] C. Saget, Is the Minimum Wage an Effective Tool to Promote Decent Work and Reduce Poverty? The Experience of Selected Developing Countries, International Labour Office, 2001, link: http://www.ilo.org/employment/Whatwedo/Publications/WCMS_142310/lang--en/index.htm
[3] J. J. Sabia, R. Burkhauser, Minimum Wages and Poverty: Will a $9.50 Federal Minimum Wage Really Help theWorking Poor?, Jan. 2010;
[4] J. T. Addison, M. L. Blackburn, Minimum Wages and Poverty, Apr. 1999;
[5] B. Dańska-Borsiak, Płaca Minimalna A Liczba Młodych Pracujących. Związki Przyczynowe I Prognozy Wariantowe, Uniwersytet Łódzki, 2014, link: http://cejsh.icm.edu.pl/cejsh/element/bwmeta1.element.desklight-4feddeec-395b-4ec8-9f3b-aada3ae4e2fd
[6] S. Borkowska, Minimum Wages and Reducing Poverty, University of Łódź, 2001, link1: http://unpan1.un.org/intradoc/groups/public/documents/nispacee/unpan004913.pdf , link2: http://unpan1.un.org/intradoc/groups/public/documents/nispacee/unpan004779.pdf