Kontynuuję temat analizy stabilności w języku R. Jest to kontynuacja serii 1, 2, 3, 4, 5. Dotychczas pokazywałem sposób testowania stabilności całego modelu. Był to dobry sposób, aby sprawdzić czy i w którym miejscu zmienił się wyraz wolny lub współczynnik kierunkowy, czyli wpływ zmiennej objaśniającej. Jeżeli jednak model zawierał zarówno wyraz wolny jak i współczynnik kierunkowy, a chciałem ocenić co dokładnie i kiedy się zmieniło, zaczynały się problemy. Dotychczas radziłem sobie w ten sposób, że testowałem stałość średniej poprzez test stacjonarności zmiennych i jeśli została ona zachowana, dopiero testowałem stabilność modelu. Jeśli model okazał się niestabilny, wnioskowałem, że współczynnik kierunkowy się zmienił, ponieważ wyraz wolny pełnił rolę średniej zmiennej objaśnianej (która z testu stacjonarności okazała się stała). To rozwiązanie jednak odpada, jeśli model zawiera wiele zmiennych objaśniających - nie będę wiedział, która zmienna "zmieniła" współczynnik.
Będą potrzebne 2 pakiety: strucchange oraz forecast. Jednak postanowiłem włączyć do swoich analiz trzeci pakiet, xts.
Czasem może się też przydać zmiana opcji programu, ponieważ wolę unikać notacji naukowej. Często dostajemy małe liczby, np. 0.0001. Normalnie program wyświetli 1e-04. Żeby dostać zapis dziesiętny, moża użyć funkcji options(scipen = 1). Jednak jeszcze mniejsza liczba, jak 0.00001 znów zostanie zapisana naukowo. Żeby przywrócić zapis dziesiętny, musimy zwiększyć scipen do 2. Itd. Domyślne ustawienia to scipen = 0. Czyli jeśli część dziesiętna ma powyżej 3 zer, to zwiększamy scipen o odpowiednio dużą liczbę. Wystarczy, że ustawimy scipen = 100. Trzeba zauważyć, że nie chodzi tu tylko o część dziesiętną, ale ogólnie o liczbę cyfr. Dla scipen = 100 dopiero po wystąpieniu powyżej 103 cyfr w całej liczbie dostaniemy notację naukową.
Dodatkowym problemem jest nie rzadko wyświetlanie wielu cyfr w części dziesiętnej. Chodzi tu o format, a nie zaokrąglenie. Aby kontrolować ten format stosujemy parametr digits w funkcji options. Domyślnie program używa digits = 7, co oznacza, że maksymalnie wyświetli się 7 cyfr. Np. liczbę 555.00001 pokaże jako 555. Aby zwiększyć precyzję, musimy ustawić digits = 8 lub więcej. W naszym przypadku lepiej będzie na odwrót - zmniejszymy precyzję, ponieważ nasze liczby to zazwyczaj ułamki dziesiętne i nie potrzebujemy aż 7 cyfr po kropce czy przecinku. Dla obecnych potrzeb ustawię digits = 4.
Dla przypomnienia kody dzielę zazwyczaj na 3 części:
1. Przedwstęp - najbardziej wstępne ustawienia, nie trzeba nic zmieniać
2. Wstęp - ustawianie ścieżek i modelu, tutaj wprowadzamy własne dane
3. Część główna - dotyczy głównego tematu, zazwyczaj nie trzeba nic zmieniać.
Z powodu takiego podziału przykłady zawierają jedynie Wstęp i Część główną.
# Przedwstęp
#precyzja i sposób zapisu liczb:
options(scipen = 100, digits = 4)
#pakiety
if (require("strucchange")==FALSE) {
install.packages("strucchange")
library("strucchange")
}
if (require("forecast")==FALSE) {
install.packages("forecast")
library("forecast")
}
if (require("xts")==FALSE) {
install.packages("xts")
library("xts")
}
Pakiet strucchange jest bardzo bogaty w testy stabilności. Dotychczas stosowałem testy bazujące na statystyce F. Pakiet jednak oferuje także drugą grupę testów - fluktuacji procesów empirycznych (The Empirical Process, EFP). Pierwsza grupa może wskazać co najwyżej momenty zmiany struktury modelu. Druga grupa w pewnym sensie jest bardziej ogólna, bo pokazuje jak dochodzi do tej zmiany i co się dzieje po tej zmianie - punkt zostaje zastąpiony przedziałem w czasie. Ma to duże znaczenie dla zrozumienia metodologii i interpretacji tego typu testów. W teście F dzielono próbę na dwie (różne) części i sprawdzano czy gdzieś w modelu empirycznym następuje zmiana. Tutaj natomiast sprawdza się zachowanie modelu w różnych przedziałach próby na tle procesu czysto losowego. W stabilnym modelu empiryczna ocena parametru zawsze losowo fluktuuje wokół teoretycznego parametru. Jeśli jej wariancja staje się za duża, znaczy, że proces przestaje być losowy. Aby określić czy mamy do czynienia ciągle z fluktuacją losową, wykorzystuje się centralne twierdzenie graniczne funkcjonałów. Zgodnie z tym twierdzeniem suma wielu zmiennych niezależnych ze stałą średnią i wariancją będzie w (dodatkowym) wymiarze czasowym błądzeniem przypadkowym. Dlatego w teście sumowane są kolejne odchylenia od parametru teoretycznego w danym przedziale próbnym i sprawdza się czy to zsumowane odchylenie tworzy błądzenie przypadkowe. Jeśli fluktuacja jest za duża i wychodzi poza błądzenie przypadkowe, to znaczy, że wartość prawdziwego parametru się zmieniła. Pełen zakres czasu wynosi (0, 1, ... t, ... T). Kolejne przedziały testowania są budowane na 2 sposoby, (a) od 0 do t albo (b) od t-h do t+h. Przedział (a) dotyczy skumulowanych sum reszt standardowych (ang. cumulative sums of standardized residuals, CUSUM) oraz estymacji rekurencyjnych (recursive estimates, RE), natomiast (b) ruchomych sum reszt (moving sums of residuals, MOSUM) oraz estymacji ruchomych (moving estimates, ME). W przypadku RE i ME odchylenia dotyczą nie tyle sum, co średnich w danym przedziale. Wszystkie te testy zostały powiązane w jedną klasę tzw. uogólnionego testu fluktuacji (The Generalized Fluctuation Test [1]), a ich procesy w uogólniony empiryczny proces fluktuacji (Generalized Empirical Fluctuation Process, GEFP).
Z moich obserwacji wynika, że nie ma najlepszego testu fluktuacji. Dla mniejszych prób ME najlepiej radzi sobie z odkrywaniem nagłych zmian w symulowanych modelach. Żeby mieć pełen obraz należy wykonać wszystkie testy i dopiero wtedy wyciągać wnioski.
Są różne typy testu CUSUM. Standardowy test tego rodzaju opisałem już kiedyś w tym art., gdy swoje badania wykonywałem w gretlu. Nas interesują tylko te, które umożliwiają analizę poszczególnych parametrów. Są to Score-CUSUM, Score-MOSUM, ME, RE i GEFP.
Pierwsze próby wykonam na symulacjach, aby sprawdzić jak test sobie radzi. Symulowana próba składa się z 1500 danych podzielona na 3 identyczne części. Najpierw zrobię przykład stabilnego ARMA(1,1).
#Wstęp




MOSUM wskazał błędnie zmianę struktury modelu - została przebita linia czerwona. Zobaczmy, który czynnik wywołał taki błąd:
























plot(me, functional = NULL)








MOSUM wskazał małą (dwukrotną) zmianę wyrazu wolnego i sporą zmianę w MA. Kiedy spojrzymy na wykres, to zauważymy, że faktycznie wydaje się, jakby średnia dla sim2 spadła. W rzeczywistości nie spadła tylko utrzymuje się na poziomie 1,4, a to właśnie sim1 i sim3 mają za wysokie średnie: dla sim1 3,12, sim3 3,41. Nie ma tu błędu, a po prostu silne autokorelacje podwyższają średnią empiryczną. MOSUM obiektywnie więc prawidłowo informuje nas o zmianach na wykresie, bo główną przyczynę utraty stabilności dostrzega w części MA. Część AR nie przebiła linii czerwonej, a wyraz wolny ledwo się poza nią wychylił.
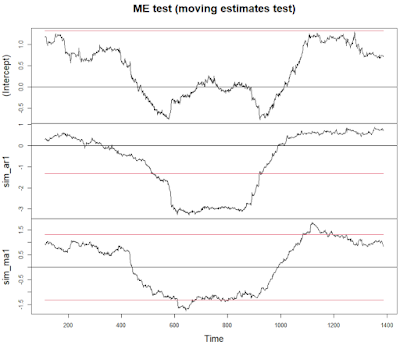
ME z kolei błędnie widzi zmianę w AR, a niewiele zmian w MA.


Podobnie jak CUSUM - błędnie.
# Wstęp
#zamieniam "\" na "/"
sciezka = gsub("\\", "/", sciezka, fixed=T)
# albo
# sciezka = gsub("\\\\", "/", sciezka)
# ustawiamy folder roboczy
setwd(sciezka)
# pliki - źródło stooq.pl
nazwa1 = "^spx_w.csv"
nazwa2 = "wig_w.csv"
nazwa <- c(nazwa1, nazwa2)
dane <- list()
stopa <- list()
for (i in 1:2) {
if (grepl(";", readLines(nazwa[i], n=1))) {
plik = read.csv(nazwa[i], sep=";", dec=",")
} else if (grepl(",", readLines(nazwa[i], n=1))) {
plik = read.csv(nazwa[i], sep=",", dec=".")
} else {
stop("Unknown separator in the file: ", nazwa[i])
}
daty = as.Date(plik[,1], tryFormats = c("%d.%m.%Y", "%Y.%m.%d", "%d-%m-%Y", "%Y-%m-%d", "%d/%m/%Y", "%Y/%m/%d"))
daty = as.Date(daty)
#jeżeli ostatnia data przekracza wczorajszą datę, to usuwamy ostatnią obserwację
if (daty[length(daty)]>=Sys.Date()) {
plik = plik[-nrow(plik),]
daty = daty[-length(daty)]
}
# inne dla pliku:
st = TRUE
k = 5
zmienna = as.numeric(plik[,k])
dane[[i]] <- na.omit(data.frame(daty, zmienna))
dane[[i]] <- as.xts(dane[[i]])
# warunek czy stopy zwrotu
if (st==TRUE) {
stopa[[i]] = round(diff(as.numeric(dane[[i]][,1]))/as.numeric(dane[[i]][,1][-length(dane[[i]][,1])]), 4)
stopa[[i]] = as.xts(na.omit(data.frame(daty[-1], stopa[[i]])))
}
dane_merged <- merge.xts(dane[[1]], dane[[2]], join="inner")
stopa_merged <- merge.xts(stopa[[1]], stopa[[2]], join="inner")
colnames(dane_merged) <- c('SP500', 'WIG')
colnames(stopa_merged) <- c('SP500', 'WIG')
sp500 = dane_merged$SP500
wig = dane_merged$WIG
stopa_sp500 = stopa_merged$SP500
stopa_sp500_1 = stopa_sp500[-length(stopa_sp500)]
stopa_wig = stopa_merged$WIG
cor(wig, sp500)
cor(stopa_wig, stopa_sp500)
Korelacja między WIG a S&P500 wynosi 0,72, natomiast ich stopy zwrotu korelują na poziomie 0,51. Regresję liniową przy pomocy funkcji lm [linear model] zbudujemy na stopach zwrotu.
summary(stopa.model)

Model jest oczywiście istotny (wpływ SP500 wynosi 58%), natomiast ciekawe, że wyraz wolny jest nieistotny - średnia niewarunkowa stopa wychodzi zerowa.

Wg CUSUM zmieniła się wariancja modelu.

MOSUM nie wskazuje na zmiany.
#Moving estimate
me <- efp(stopa.model, type="ME")
plot(me, functional = NULL)

ME sugeruje, że korelacja z S&P500 zmieniła się na chwilę. Wykres agregujący pozwoli pokazać ten moment na WIG. W tym miejscu muszę przyznać, że zrobiłem "błąd", bo operowałem na pakiecie xts, sądząc, że będzie łatwiej przy konstrukcji danych i wykresach. Jednakże pakiet strucchange działa (obecnie) formalnie na obiektach ts i jeśli jest to xts, to nie widać dat na wykresach. Drugim problemem jest odpowiednie dopasowanie osi x do wykresu. Aby pokazać każdy rok, trzeba użyć dodatkowego kodu, który objaśniłem na stronie o parametrach graficznych w R.
par(mfrow=c(2,1), mar=c(1,5,2,3), oma=c(2,0,0,0))
plot(me, functional="max")
plot(x=daty, y=as.ts(as.zoo(wig)), type="l", ylab="WIG", xaxt="n")
datySkr = seq(from=daty[1], to=daty[length(daty)], length.out=round(length(daty)/52))
axis(side=1, cex.axis=1, cex.lab=1, at=datySkr, labels=format(datySkr,"%Y"), las=2)

Z wykresów wynika, że tygodniowa kowariancja z amerykańskim indeksem wzrosła w latach 2005-2006. Obecnie wpływ USA na WIG wynosi niecałe 60% zgodnie z modelem regresji i nic nie wskazuje, by miało się to zmienić w najbliższym czasie.
Możemy też wnioskować, że słaba kondycja naszej giełdy na tle USA wynikała nie ze spadku korelacji, ale średniej (niewarunkowej) stopy zwrotu. To znaczy średnia tygodniowa pozostała stabilna - jest praktycznie zerowa - i znajduje się w obszarze normalności, ale "losowo" spadła poniżej zera (Intercept < 0). Dzieje się to od 2008 r. Ostatnie tygodnie to jej poprawa i jeżeli iść "logiką" regresji do średniej to powinniśmy oczekiwać wychylenia na plus.P. S. Pozostałych dwóch testów: RE i GEFP nie pokazuję już, bo wyniki są takie same jak przy CUSUM.
Brak komentarzy:
Prześlij komentarz