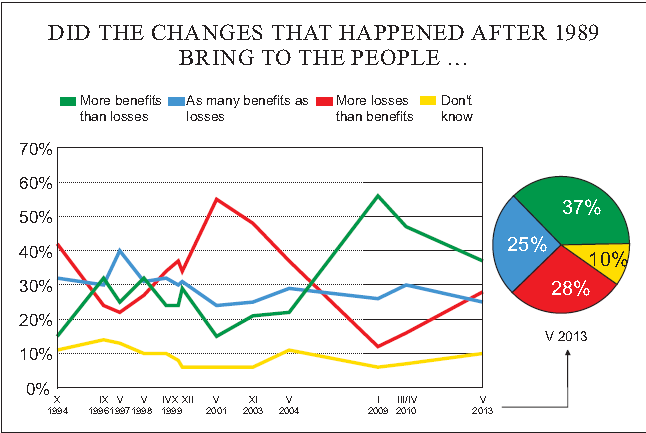
Od czasu Schumpetera i Keynesa cykle gospodarcze przestały być zwykłym odchyleniem od równowagi gospodarki kapitalistycznej, a stały się jej immanentnym elementem. Naturalnie pojawiło się wtedy pytanie czy można modelować i przewidywać cykle. Przez dziesiątki lat powstało mnóstwo różnych modeli starających się na nie odpowiedzieć. Jednym z bardziej znanych jest filtr Hodricka-Prescotta (HP). Współcześnie model ten jest często używany do prognozy PKB, inflacji, stopy procentowej i innych zmiennych ekonomicznych. Częściowo łączy on teorię ekonomiczną z praktyczną analizą nieliniowych trendów. Z giełdowego punktu widzenia można powiedzieć, że dotyka jednocześnie analizy fundamentalnej i analizy technicznej. Dlatego można spróbować użyć go pośrednio lub bezpośrednio do prognozy kursów giełdowych.
Hodrick i Prescott [1] najpierw definiują szereg czasowy y(t) (np. PKB) jako sumę zmiennego trendu g(t) (składowa wzrostu) oraz nieokresowego cyklu c(t) (stacjonarna reszta z wartością oczekiwaną zero):
(1)
Zmienna wzrostu, g(t), powinna być niestacjonarna, ale po dwukrotnym zróżnicowaniu, osiąga się często stacjonarność i w ten sposób dokonuje się de-trendyzacji. Dodatkowa zmienna stochastyczna c(t) mimo stacjonarności może być np. procesem ARMA (lub szerzej ARFMA), który zawiera autokorelacje. Aby znaleźć optymalne wartości oczekiwane, można określić następujące zadanie optymalizacyjne:
(2)
gdzie c(t) = y(t) - g(t).
Głównym problemem w tym zadaniu jest lambda, która wygładza szereg. Zgodnie z twierdzeniem podanym przez Hodricka i Prescotta jeżeli zmienna c(t) oraz zmienna [g(t) - g(t-1)] - [g(t-1) - g(t-2)] mają stacjonarny rozkład normalny, brak autokorelacji, średnią zero, to warunkowa wartość oczekiwana będzie rozwiązaniem problemu (2), jeżeli:
(3)
gdzie
σ(c)^2 to wariancja zmiennej cyklicznej oraz σ(g)^2 to wariancja trendu.
Można zauważyć, że coś tu się nie zgadza: przed chwilą
powiedziałem, że c(t) może być modelem z autokorelacjami, a teraz podaję
twierdzenie na optimum, gdy tych nie ma. Powinniśmy to twierdzenie rozumieć co
najwyżej jako przybliżenie rzeczywistości. Z drugiej strony powstaje wtedy
pytanie: jeśli to przybliżenie, to należy traktować zmienną cykliczną jak
zwykłą zmienną losową, ale wtedy nie może być zmienną cykliczną. Na ten problem
zwraca też uwagę Hamilton w świeżej pracy znamiennie zatytułowanej "Why
You Should Never Use the Hodrick-Prescott Filter" [2]. HP został tam poddany surowej krytyce, jednak jest
to zupełnie nowy temat.
I tak zresztą wzór (3) niewiele daje, jeżeli wariancje tych procesów zmieniają się w zależności od wyboru lambda. Wzór ten bowiem zakłada, że znamy lambdę. Gdyby jednak zwiększanie tego parametru nie powodowało szczególnych zmian w obydwu wariancjach, to otrzymalibyśmy całkiem niezłe narzędzie. W praktyce HP polecają używać lambda = 1600 dla danych kwartalnych.
Jeżeli jednak mamy dane o większej częstości, to lambda wymaga odpowiedniego przekształcenia. Ravn i Uhlig [3] wyprowadzają następującą formułę:
(4)
gdzie f to częstość pobierania próbki w pewnym ustalonym z góry okresie czasu T. Częstość = 1/T. Załóżmy, że ten okres czasu to kwartał. Jeżeli pobieramy próbkę raz na kwartał, to znaczy, że f = 1. Jeśli z góry wiemy, że dla kwartalnych danych lambda = 1600, to mamy:
Jeżeli pobieramy próbkę 1 na miesiąc, to znaczy, że pobieramy ją 3 razy w ciągu kwartału, który ciągle stanowi nasz okres odniesienia. Oznacza to f = 1/3:
Jeżeli pobieramy próbkę 1 na rok, tj. roczne dane, tzn. f = 4, bo rok stanowi 4-krotność kwartału, tzn. równa się 4*T:
(5)
Wzór (4) można przedstawić w innej, trochę łatwiejszej postaci:
(6)
gdzie n to liczba obserwacji w ciągu 1 roku. Jeżeli bierzemy dane miesięczne, to n = 12, bo n =4T = 4*(liczba miesięcy w kwartale). Jeżeli dane są kwartalne, n = 4, a jeśli roczne n = 1. Wzór (6) jest bardziej intuicyjny, bo od razu wiemy czym jest n: odpowiada na pytanie ile razy obserwacje występują w roku. Jeśli przyjmiemy, że lambda kwartalna = 1600, wtedy będziemy operować wzorem:
(7)
Przykład 1. Zróbmy eksperyment na funkcji (sinus + biały szum) dla 1000 obserwacji. W Gretlu łatwo dostępny jest filtr HP (filtracja). Gretl automatem wybrał 100, ale ustawmy na początek lambda = 1600. Dostajemy obraz:
Dobrą opcją jest możliwość zapisania zarówno zmiennej trendu g(t), jak i cyklu c(t). Możemy więc sprawdzić czy została spełniona zależność (3). Po dwukrotnym zróżnicowaniu g(t) i wzięciu wariancji obydwu zmiennych dostałem lambda = 70090. A więc nie zgadza się. Aby zachować zależność (3) możemy spróbować do HP podstawić lambda = 70090. Dostaniemy wtedy:
Im większa lambda, tym większa gładkość sfiltrowanej funkcji. Jasne więc, że im większa lambda, tym obraz będzie ładniejszy, co automatycznie nie oznacza, że będzie to optimum. Gdy znów sprawdzimy zależność (3), okaże się, że nadal nie jest spełniona: dostałem na jej podstawie wartość 227932. Można więc przypuszczać, że wartość ta będzie ciągle rosła. Maksymalną wartość, jaką można podstawić w Gretlu to lambda = 999999. Wtedy mamy:
Ten przykład dobrze pokazuje, że maksymalizacja lambdy nie jest dobrym pomysłem: odchylenia szeregu od filtru są znacznie większe niż przy mniejszych wartościach. Nie da się jednak odnaleźć takiego optimum, które spełniałoby (3), bo zarówno drugie różnice trendu g(t), jak i zmienna c(t) nie spełniają warunków tamtego twierdzenia (występują autokorelacje, brak normalności). Tutaj stosując wzór (3) dostanę lambda = 1,55 mln.
Można by zadać takie pytanie: skoro rzeczywiste częstości danych są znane, a posiadamy wzór (5) i (6), to po co liczyć lambdę z (3)? Rzecz w tym, że liczba 1600 została wybrana przez HP, dlatego że pasowała do danych empirycznych. a więc dla każdych innych jest właściwie z sufitu. Zacytuję ich fragment, aby dodatkowo to wyjaśnić:
Są różne metody szacowania lambdy - można wykorzystać filtr Kalmana, jak to robią HP lub estymator największej wiarygodności jak Schlicht [4].
Przykład 2. PKB kwartalnie od 1 kw 1996 do 1 kw 2017. Dane indeksu realnego wzrostu PKB r/r, z kwartalną częstością pobrałem z bankier.pl. Gretl automatycznie ustawia przy danych kwartalnych lambda = 1600. Dostajemy:
Przykład 3. Nowe zamówienia w przemyśle (ceny bieżące) miesięcznie od początku 2006 do marca 2017. Indeks zmian r/r, z częstością miesięczną pobrałem z GUS. Gretl automatycznie ustawia przy danych miesięcznych lambda = 14400. Dostajemy:
Mimo automatycznej lambdy, powinniśmy sprawdzić jak filtr się zachowa, gdy zastosujemy wzór (7). Dostaniemy lambda = 6,25*12^4 = 129600:
Wydaje się, że ten drugi wariant jest rzeczywiście lepszy.
Przykład 4. WIG - 2006-marzec 2017, miesięcznie (257 obserwacji). To samo, gdy lambda = 14400:
Lambda = 129600:
Przykład 5. WIG 1996-marzec 2017, miesięcznie. Jak wyżej lambda = 14400:
lambda = 129600:
Jak widać zakres próby nie zmienił zachowania filtra.
Przykład 6. Ruch Browna. Dla porównania także 257 obserwacji losowego procesu o rozkładzie normalnym: lambda = 14400:
Lambda = 129600:
Przykład ten ilustruje, że filtr HP nie jest żadnym magicznym narzędziem, nie wychwytuje rzeczywistego trendu, tylko to co przypomina trend. Powyższy ruch Browna z definicji ma wartość oczekiwaną równą 0 oraz brak autokorelacji.
Przykład 7. Zmiany WIG vs. zmiany ruchu Browna. Dla pełnego obrazu zrobiłem porównanie samych zmian
kursów. Również w tym przypadku filtr HP daje podobne sygnały jak przy
ruchu Browna. Użyłem tu lambdy 129600:
WIG (ten sam zakres co poprzednio):
Zmiany ruchu Browna (ten sam zakres):
Filtr Hodrika-Prescotta jest tak naprawdę bardziej wysublimowanym rodzajem średniej kroczącej, można go dodać lub zastąpić MA w analizie technicznej. Wydaje się, że sama znajomość przeszłości niewiele pomoże przy przewidzeniu przyszłych zmian. Rynek składa się z takich elementów jak oczekiwania finansowe, wielkość obrotów (energia kapitału, która z jednej strony wspomaga daną tendencję, z drugiej zmniejsza ryzyko płynności), psychologia (wpływ przeszłości oraz wzrost wariancji, kurtozy i skośności). Dlatego włączenie ich do modelu ekonometrycznego, a następnie użycie filtru HP na tym modelu powinno dawać lepsze rezultaty.
Literatura:
[1] Robert J. Hodrick, Edward C. Prescott,
Postwar U.S. Business Cycles: An Empirical Investigation, Feb., 1997;
[2] James D. Hamilton,
Why You Should Never Use the Hodrick-Prescott Filter, July 30, 2016;
[3] Morten O. Ravn, Harald Uhlig,
On Adjusting the Hodrick-Prescott Filter for the Frequency of Observations , May, 2002;
[4] Ekkehart Schlicht,
Estimating the smoothing parameter in the so-called Hodrick-Prescott filter, 2005.