Jednym z najważniejszych wyzwań nauki o finansach jest zrozumienie w jaki sposób inwestorzy wyceniają ryzykowne aktywa. Jest ogólnie zgodny pogląd, że inwestorzy wymagają wyższego zwrotu z inwestycji w ryzykowne projekty czy papiery wartościowe, jednakże nadal nie ma jednolitego stanowiska co do modelu opisującego premię za ryzyko (jak i samo ryzyko). Wiemy, że punktem wyjścia musi być teoria portfela, która stanowi bazę do wyprowadzenia jednego z najważniejszych modeli w teorii finansów - CAPM, który z kolei pozwala w przejrzysty sposób oszacować premię za ryzyko z poszczególnych aktywów. Wnioski z CAPM są następujące:
a) ryzyko projektu jest mierzone betą danego aktywa
b) zależność pomiędzy wymaganą stopą zwrotu a betą jest liniowa (i dodatnia).
Wiele badań przeprowadzono w celu sprawdzenia czy CAPM faktycznie wyjaśnia historycznie średnie stopy zwrotu. Najpoważniejsze badania przeprowadzone np. przez Famę i Frencha w 1992 r. dowodzą, że CAPM jest niezdolny do wyjaśniania średnich stóp zwrotu, tak
że jest ekonomicznie nieistotny. Relacja pomiędzy rynkową betą a średnią
stopą zwrotu jest płaska. W szczególności portfele zawierające akcje z relatywnie małą kapitalizacją (małe spółki) pozwalały osiągać ponadprzeciętne stopy zwrotu, tzn. w tym sensie, że pewna część średniej stopy zwrotu nie mogła zostać wyjaśniona za pomocą premii za ryzyko.
Trzeba jednak pamiętać o założeniach stojących u podłoża klasycznego CAPM. Model ten wyprowadzono przy założeniu, że inwestorzy żyją tylko w jednym okresie, przez co model jest statyczny. W ten sposób zakłada się, że beta i premia za ryzyko są zawsze takie same.
W rzeczywistości mogą się one zmieniać. Na przykład podczas recesji dźwignia finansowa (stosunek długu do kapitału własnego plus jeden lub inaczej aktywa do kapitału własnego) firm o słabszej kondycji może drastycznie wzrosnąć (1. firma, aby przetrwać, zaciąga pożyczkę, ale pożyczkodawcy będą w takiej sytuacji żądać wyższego oprocentowania; 2. na skutek strat i spadku kapitału własnego) powodując wzrost bety. (Zwróćmy uwagę, że wtedy rośnie oczekiwana stopa zwrotu, ponieważ cena akcji spada). Beta zależy od warunków ekonomicznych, co prowadzi do wniosku, że trzeba stosować betę warunkową.
R. Jagannathan i Z. Wang [1] obrazują problem statycznego CAPM następująco. Wyobraźmy sobie, że są tylko dwie akcje na świecie, A oraz B, i rozważamy dwa okresy. Beta akcji A wynosi 0,5 w 1 okresie i 1,25 w 2 okresie (czyli średnia beta wynosi 0,875). Beta akcji B wynosi odpowiednio 1,5 i 0,75 (czyli średnia beta = 1,125). Załóżmy, że oczekiwana premia za ryzyko portfela rynkowego (tj. z tych dwóch akcji) jest to 10% w 1 okresie i 20% w 2 okresie (czyli średnio 15%). Wtedy oczekiwana premia za ryzyko akcji A wyniesie 5% (0,5*10%) w 1 okresie i 25% (1,25*20%) w 2 okresie. Oczekiwana premia za ryzyko z akcji B wyniesie 15% w obu okresach. W ten sposób badacze popełniają błąd, gdyż stwierdzają, że średnia premia wynosi 15% zarówno dla rynku jak i akcji B, ale beta jest inna: rynek ma betę równą 1, a akcja B 1,125. To znaczy - mówiąc bardziej ogólnie - mogą istnieć dwie różne akcje o tej samej średniej (w czasie) premii za ryzyko, lecz innej becie i będzie się wydawało, że CAPM nie działa.
Autorzy opracowują atrakcyjny teoretycznie i empirycznie model, gdyż przechodzi on płynnie od warunkowego CAPM do niewarunkowego CAPM, w którym to beta jest zbudowana z dwóch niezależnych części. Dostajemy de facto szczególny przypadek APM (Arbitrage Pricing Model), tj. modelu wieloczynnikowego (wielo-betowego). Tyle że APM jest tylko ogólnym modelem nie interpretującym żadnego czynnika, podczas gdy w modelu Jagannathana i Wanga wszystko jest ściśle określone.
Zacznijmy więc od wprowadzonej definicji CCAPM (Conditional CAPM - Warunkowy CAPM). Niech I(t-1) oznacza informację dostarczoną inwestorom w okresie t-1. Wtedy:

Pojawia się tutaj pojęcie zero-beta, o którym nigdy nie wspominałem. Model Zero-beta CAPM został wyprowadzony w 1972 r. przez Fishera Blacka [2] i można go traktować jako uogólnienie klasycznego CAPM. Zamiast stopy wolnej od ryzyka pojawia się stopa aktywa, którego beta = 0. Taka beta może mieć odchylenie standardowe różne od zera (w przeciwieństwie do stopy wolnej od ryzyka), a więc aktywo może być ciągle ryzykowne, ale sama stopa zwrotu może w ogóle nie korelować z portfelem rynkowym (i dlatego jest niezależnym od bety elementem). Na przykład jeśli spółka opiera swoją działalność na wdrażaniu nowoczesnej, opatentowanej przez siebie technologii, to jej zyski nie będą raczej zależały od kondycji gospodarki (pod warunkiem, że nie jest to "dobro luksusowe", o wysokiej cenie). Motywem do wyprowadzenia tego modelu było, podobnie jak w przypadku CCAPM, empiryczne zakwestionowanie CAPM przez statystyków.
Z równania (2) można otrzymać niewarunkowy CAPM:
W okresie recesji wiele firm wpada w problemy finansowe, przez co dźwignia finansowa, jak już wspomniałem, wzrasta. Jest to czynnik powodujący wzrost warunkowej bety. Jednocześnie jednak, ponieważ możliwości kreowania zysku spadają, niepewność również spada (bo wiadomo, że będzie źle). Jest to więc czynnik obniżający warunkową betę. Tak więc te dwa przeciwstawne czynniki będą się ze sobą ścierać.
Jeśli ostatnie wyrażenie w równaniu (4) będzie równe 0, to wracamy do statycznego, klasycznego CAPM. W przypadku CCAPM wyrażenie to można zdekomponować na dwa niezależne czynniki. Po dalszych przekształceniach Autorzy otrzymują model w formie regresji liniowej:
gdzie:
c(0), c(m), c(prem) to pewne stałe,
Pierwsza beta(i) mierzy, tak jak zwykła beta, średnie ryzyko rynkowe i-tego aktywa. Druga beta nazwana premium beta (po polsku możemy powiedzieć, że jest to premia za betę), mierzy niestabilność bety, czyli zmienność ryzyka rynkowego.
Premia za ryzyko rynkowe, R(prem)(t-1) to różnica między oczekiwaną stopą zwrotu z portfela rynkowego a oczekiwaną stopą zwrotu z aktywa o zerowej becie, lecz odnosi się do okresu poprzedniego, nawiązując tym samym do zmienności samego ryzyka.
Autorzy weryfikują ten model w praktyce. Najpierw określają 2 problemy natury technicznej.
Po pierwsze premia za ryzyko nie jest już różnicą pomiędzy oczekiwaną stopą zwrotu z portfela rynkowego a stopą wolną od ryzyka, lecz różnicą pomiędzy oczekiwaną stopą zwrotu z portfela rynkowego a stopą zwrotu z aktywa o zerowej becie. Wiadomo jednocześnie, że premia za ryzyko będzie się zmieniać pod wpływem cyklów gospodarczych. Z tego powodu Autorzy decydują się użyć zmiennych prognozujących takie cykle. Jak Autorzy stwierdzają, wskazując na literaturę, dużą pomocą w tym stanowią stopy procentowe. Jako jednostkową premię za ryzyko wykorzystują różnicę pomiędzy 6-miesięcznymi papierami komercyjnymi a 6-miesięcznymi bonami skarbowymi.
Po drugie portfel rynkowy również jest nieobserwowalny. Portfel ten powinien odzwierciedlać zagregowane bogactwo uczestników rynku. To znaczy, inwestor posiadający ułamek portfela rynkowego posiada nie tylko ułamek wartości spółek na rynku kapitałowym i pieniędzy w skarbie państwa oraz bankach, ale także ułamek wartości wszystkich innych firm spoza rynku kapitałowego oraz ułamek wszystkich innych aktywów (nie tylko które da się kupić i sprzedać, ale także tych, których nie da się kupić ani sprzedać). Portfel rynkowy jest więc bardzo szeroko rozumiany. Wynika to z faktu, że w teorii portfela uwzględniamy wszystkie aktywa, które mogą inwestorowi przynieść zysk i niosą ryzyko mierzone wariancją. Teoria sztucznie zakłada, że wszyscy mają równy dostęp do każdego aktywa. W rzeczywistości, jak wiadomo każdy inwestor może de facto mieć dostęp do takich aktywów, do których inni nie mają. To oczywiście powoduje, że każdy inwestor może mieć inny portfel rynkowy, a nie - jak mówi teoria - jeden i ten sam. Na szczęście, jak się okazuje, taka sytuacja nie będzie wywoływać strasznych rozbieżności z modelem. David Mayers w 1972/1973 r. wyprowadził następujący model CAPM, uwzględniający aktywa niehandlowane:

gdzie:
Model ten oczywiście można sprowadzić do wersji zero-beta CAPM.
Jeśli więc są jakieś aktywa niedostępne dla reszty, którymi się nie handluje, to najprawdopodobniej ich korelacja z rynkiem będzie zerowa, wtedy kowariancja będzie zerowa i model sprowadza się do postaci klasycznego CAPM. Fama i Schwert [3] empirycznie zbadali różnicę pomiędzy betą pierwotnego
CAPM a modelem Mayersa, przyjmując, że aktywa niehandlowane jest to
kapitał ludzki. Analizowali zarówno miesięczne, jak roczne stopy zwrotu
na NYSE. Autorzy kwitują stwierdzeniem, że różnica ta jest niewielka i
praktycznie model Mayersa nie zmienia dostarczanych przez pierwotny CAPM
oczekiwań. Można więc mniemać, że korelacja niehandlowanego z handlowanym kapitałem jest faktycznie zerowa albo bliska zeru. Trzeba jednak podkreślić, że badacze zajmowali się tylko
statyczną wersją CAPM.
Normalnie celem CAPM jest wyznaczenie oczekiwanej stopy zwrotu aktywa z rynku kapitałowego (zupełnie inną kwestią jest fakt, że do jej wyznaczenia potrzebne są także aktywa spoza tego rynku). Ale gdybyśmy już chcieli wyznaczyć oczekiwaną stopę zwrotu z niehandlowalnego aktywa, ale korelacja z rynkiem byłaby zerowa, to dostalibyśmy stopę wolną od ryzyka lub - dla zero-beta CAPM - stopę zwrotu z aktywa o zerowej becie. Model z zerową betą staje się bardziej realistyczny, ale też kłopotliwy, bo jeśli każdy ma swoje własne aktywo o zerowej becie, a ich oczekiwane stopy zwrotu będą różne, to nachylenie CML i SML będzie dla każdego inwestora inne (subiektywne), tak że obiektywne empiryczne modelowanie staje się niejednoznaczne.
Gdy analizujemy problem aktywów niehandlowalnych, to prędzej czy później docieramy do kapitału ludzkiego. Oczywiście możemy sprzedawać swoją pracę i swój czas, ale w większości cywilizowanych krajów (ze względu na przykład na ograniczenia prawne) nie możemy sprzedać swoich umiejętności, zdolności czy talentów. Posiadając te wartości możemy jedynie generować z nich okresowe wynagrodzenie, czyli swego rodzaju dywidendy, którym może towarzyszyć określone ryzyko (chwiejność umiejętności, zdolności lub talentów). Widzimy teraz jasno, że handlowane aktywa trzeba inaczej traktować niż niehandlowane, a stąd dlaczego model Mayersa odróżnia te dwa typy.
W rzeczywistości kwestia niehandlowalności kapitału ludzkiego jest
bardziej skomplikowana. Np. hipoteczne listy zastawne czy hipoteczne
instrumenty pochodne, normalnie handlowane na rynku, opierają się na
kredytach hipotecznych, a z kolei kredyty hipoteczne są swego rodzaju
pożyczką przyszłych oczekiwanych dochodów (wynagrodzeń z pracy) służących do kupna
nieruchomości. W ten sposób kapitałem ludzkim można w pewnym stopniu handlować.
Jagannathan i Wang przyjmują w swoim modelu, że część kapitału ludzkiego, ściślej sam dochód z pracy, jest dobrem handlowanym. Stąd wysuwają propozycję, by stopę wzrostu dochodu z kapitału ludzkiego potraktować jako pośrednik stopy zwrotu z kapitału ludzkiego. Trzeba przyznać, że ma to sens: część wynagrodzenia z pracy może zostać zainwestowane w projekty handlowalne, ale nieskorelowane z rynkiem kapitałowym, np. pomysły technologiczne lub organizacyjne, w skrócie: w projekty prowadzące do postępu technicznego. Takie projekty przynoszą stopę zwrotu z samego wynagrodzenia z pracy.
W konsekwencji przyjmujemy stopę z portfela rynkowego, Rm(t), o następującej konstrukcji:
gdzie:
(Reszta to stałe.)
Po odpowiednich przekształceniach otrzymujemy trój-betowy CAPM:
gdzie:
CZĘŚĆ EMPIRYCZNA:
Autorzy empirycznie testują swój CAPM, porównując go z innymi modelami. Użyli stóp zwrotu z akcji na NYSE, AMEX (1962-90) i NASDAQ (1973-90). Weryfikację modelu oparli na badaniach Famy i Frencha, aby móc z nimi porównywać. Najpierw zaczynają od tradycyjnego, zwykłego CAPM, tj. o postaci:
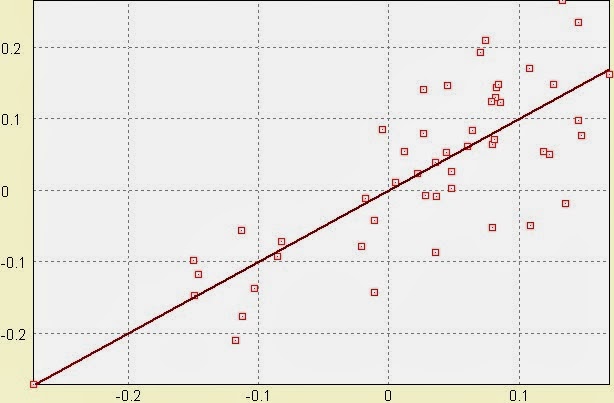
Graficznie przestawiają uzyskane wyniki:
Jak widać faktyczne średnie stopy zwrotu z akcji kompletnie nie odpowiadają oczekiwanym stopom zwrotu przewidywanym przez CAPM.
Następnie pozwalają, aby beta zmieniała się cały czas, tj. zakładają warunkowy CAPM, ale bez kapitału ludzkiego. Testują zatem swój dwu-betowy CAPM:
Niestety graficznie wyników nie pokazali. Możemy jedynie porównać dane statystyczne. O ile wsp. determinacji R^2 w statycznym CAPM wyniósł zaledwie 1,35%, o tyle w modelu z premium beta wynosi prawie 30%. Jest to istotna poprawa modelu, jednak jeśli przyjrzeć się p-value parametrów, to już tak kolorowo nie jest. O ile c(prem) jest istotny statystycznie (0,1%), o tyle c(vw) juz nie (38,45%).
W końcu Autorzy dodają do modelu kapitał ludzki, testując swój główny trój-betowy model:
Za dochód z pracy brali całkowity dochód minus dochód z dywidend. (dywidendy powinny być odejmowane, bo indeks już je uwzględnia). Tutaj już mogą pochwalić się całkiem niezłymi rezultatami:
Średnie zrealizowane stopy zwrotu niemal idealnie odpowiadają prognozowanym oczekiwanym zyskom. R^2 wyniósł 55%. p-value dla c(labor) wyniósł 2,07%, a więc dochód miał duży wpływ na poprawę prognozy. Niestety c(vw) nadal jest zbyt wysoki (p-value = 23,8%), pomimo że już jego istotność się poprawiła.
Szkoda, że Autorzy nie sprawdzili modelu usuwając c(vw), bo mogłoby się okazać, że wyniki są jeszcze lepsze. Ale to popsułoby wydźwięk pracy, której celem było opracowanie teorii i zbadanie jej w praktyce. Gdyby rzeczywiście tak było, to zamiast obrony CAPM, dostalibyśmy kolejne jego "obalenie".
Autorzy raczej, jak na klasycznych ekonomistów przystało, dążą do obalenia poglądów o istnieniu anomalii rynkowych, jak np. efekt małych spółek lub efekt BV/P. Na przykład dodali do swojego modelu nową zmienną, logarytm z wartości rynkowej akcji, testując efekt małych spółek. Wielkość spółki rozumie się tu poprzez wartość rynkową, a nie księgową. Jeśli dodatkowa zmienna wielkości rzeczywiście istotnie wpłynie na poprawę modelu, to znaczy, że efekt wielkości spółek rzeczywiście będzie występował. Wnioski są ogólnie takie, że ta dodatkowa zmienna w 3-betowym CAPM rzeczywiście poprawiła R^2, z 55% do 64,7%, jednakże sama istotność współczynnika tej zmiennej jest zbyt niska - jej p-value = 14,7%.
W końcu badacze porównali swój model z 3-czynnikowym modelem Famy i Frencha [4], którzy dowiedli empirycznie, że rzeczywiście występuje efekt małych spółek (tzn. średnio rzecz biorąc, im mniejsze spółki, tym większe oczekiwane zyski) oraz efekt BV/P (tzn. średnio biorąc, im większy BV/P , tj. book value to price, tym większe oczekiwane zyski). Fama i French wprowadzili do CAPM 2 czynniki, odpowiadający za efekt małych spółek oraz odpowiadający za BV/P. Postać tego modelu jest następująca:
c(SMB) - (Small Minus Big) - jest to różnica pomiędzy średnią stopą zwrotu z 3 portfeli najmniejszych akcji (o najmniejszej kapitalizacji) a stopą zwrotu z 3 portfeli największych akcji (o największej kapitalizacji).
c(HML) - (High Minus Low) - jest to różnica pomiędzy stopą zwrotu z 2 portfeli o największym BV/P a stopą zwrotu z 2 portfeli o najmniejszym BV/P.
Wyniki testu tego modelu przez Jagannathana i Wanga okazują się zaskakujące. Otrzymali R^2 równy 55%, czyli tyle samo, co w swoim 3-betowym CAPM. Obydwa modele mają podobną moc. Ale p-value dla c(SMB) i c(HML) wyniosło, odpowiednio, 12,6% i 33,6%, wskazując na duże ryzyko błędu. Oczywiste pytanie się nasuwa co by się stało, gdyby dodać dwa czynniki z modelu Famy-Frencha do 3-betowego CAPM? Czyli rozważamy następujący model:
Rezultat to wzrost R^2 do 64%. Jednakże jednocześnie p-value c(SMB) i c(HML) wzrosło do ponad 40%, wskazując na swoją nieistotność (co Autorzy zaznaczają). Jeżeli jednak model tak się poprawił, to najprawdopodobniej jest to wynik tego, że czynniki z modelu Famy i Frencha są skorelowane z niestabilnością bety i kapitałem ludzkim. Tym samym można uznać, że efekt małych spółek oraz efekt BV/P wynika przynajmniej w pewnej części z ryzyka zmienności bety i z ryzyka inwestowania dochodów z pracy.
Pomimo tych wszystkich rewelacji, empiryczna część badań Jagannathana i Wanga została skrytykowana przez Lewellena i Nagela w 2006 r. [5], którzy zaprzeczają jakoby CCAPM znacznie poprawiał CAPM. Według nich CCAPM (ani uzyskany z niego niewarunkowy CAPM) nie wyjaśnia stóp zwrotu, w szczególności anomalii rynkowych, jak efekt małych spółek, BV/P czy momentum. Dowodzą, że kowariancja pomiędzy betą a premią za ryzyko (drugi składnik w równaniu z numerem 4) nie jest wystarczająco duża, aby uzasadnić faktyczne stopy zwrotu. Pomimo tych kontrowersji wyprowadzony 3-betowy CAPM wnosi duży udział do teorii finansów.
Literatura:
[1] R. Jagannathan, Z. Wang - The conditional CAPM and the cross‐section
of expected returns, The Journal of Finance, 1996,
[2] F. Black -
Capital market equilibrium with restricted
borrowing, The Journal of Business, 1972,
[3] E. F. Fama, G. W. Schwert - Human capital and capital market
equilibrium, Journal of Financial Economics, 1977,
[4] E. F. Fama, K. R. French - Common risk factors in the returns on
stocks and bonds, Journal of financial economics, 1993,
[5] J. Lewellen, S. Nagel - The conditional CAPM does not explain
asset-pricing anomalies, Journal of Financial Economics, 2006.



























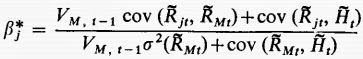



















{kind=link}
{kind=link}
{kind=link}
{kind=link}