
Sprowadzając go do stacjonarności (czyli biorąc pierwsze różnice) otrzymamy zwykły AR(1) ze współczynnikiem autoregresji 0.6 (czyli jest to ruch Browna z autokorelacją 1 rzędu). Dostaniemy dla niego funkcję autokorelacji - ACF:

Empiryczny ACF zaczyna się faktycznie od poziomu 0.6, ale w kolejnych rzędach błędnie odnajduje dodatkowe autokorelacje. ACF wskazuje, że pamięć kończy się dopiero przed 6-tą obserwacją (p-value = 0.11). Dzieje się tak, dlatego że kolejne obserwacje wpływają na siebie: jeżeli jednego dnia jest wzrost, to szansa na wzrost kolejnego dnia jest spora, ale skoro tak, to i trzeciego dnia będzie spora itd. Tak więc pozornie pierwszy dzień wpływa na trzeci, czwarty itd. To daje do myślenia. Ten efekt może być pomylony z "efektem motyla" znanym z teorii chaosu, który będzie związany z pamięcią długoterminową, ale nie krótkoterminową.
Aby usunąć te wewnętrzne autokorelacje, stosuje się cząstkową autokorelację PACF (partial ACF).

PACF wyraźnie wskazuje, że już po 1 kroku autokorelacja znika.
Stąd PACF służy do oceny autokorelacji p-tego rzędu, a jednocześnie pozwala dobrać optymalny poziom p w modelu AR(p).
A teraz wygenerujmy proces z długą pamięcią, ale bez krótkiej, tzn. część AR(1) = 0, a więc wydawałoby się, że także autokorelacja cząstkowa nie wystąpi. Niech to będzie proces o takim przebiegu, również z 1000 obserwacjami:

Jest to ułamkowy proces ruchu Browna z wykładnikiem Hursta = 0.9, czyli jego pierwsze różnice charakteryzują się ułamkowym rzędem integracji d = 0.4 w modelu ARFIMA (krótkie opisowe wyjaśnienie ułamkowego rzędu integracji zamieściłem w Czy oczekiwane stopy zwrotu w ogóle się zmieniają?, tam też opisałem znaczenie ACF). Analizując pierwsze różnice, zacznijmy znowu od ACF:

Tym razem ACF spada o wiele wolniej i pamięć utrzymuje się jeszcze długo po 9-tej obserwacji. Następnie sprawdźmy PACF:

Autokorelacja cząstkowa zanika dopiero po 3 kroku. Sugerowałoby to, że aby wymodelować ten proces, trzeba by użyć AR(3), a właściwie ARFIMA(3, 0.4, 0) - część MA zostawiam, aby nie wprowadzać zamieszania. A jednak gdy mamy do czynienia z procesami o długiej pamięci, ta klasyczna zasada Boxa-Jenkinsa nie działa. Przecież wygenerowałem ten proces, wiedząc, że nie posiada krótkiej pamięci, którą odnajduje PACF. Żeby zauważyć, że rzeczywiście długa pamięć "myli" PACF, możemy estymować 2 modele: ten prawidłowy, tj. ARFIMA(0, 0.4, 0) oraz ARFIMA(1, 0.4, 0). Taką możliwość daje program Matrixer.
ARFIMA(0, 0.4, 0)

Dostaliśmy d = d1 = 0.448. Ocena parametru jest bliska prawdziwemu 0.4.
ARFIMA(1, 0.4, 0)

W tym przypadku część AR(1) okazuje się nieistotna statystycznie (p-value = 0.176), natomiast d = d1 = 0.388 jest istotny i bliski prawdziwemu 0.4.
Nie ma sensu zwiększać p aż do 3, skoro już 1 rząd jest nieistotny. Dlatego widać, że długa pamięć może zastąpić całkowicie autoregresję. PACF działałby tylko wtedy, gdybyśmy od początku nałożyli warunek, że d = 0, czyli po prostu estymowali zwykły AR. Wtedy istotnie powinniśmy zastosować AR(3).
Mimo iż pamięć jest rozważana w rozmaitych kontekstach, to okazuje się, że różnicę pomiędzy pamięcią krótko- a długoterminową można sformułować następująco: pamięć, w sensie ACF, krótkoterminowa zanika geometrycznie, natomiast długoterminowa - hiperbolicznie [1, 2]. Przykładem funkcji, która maleje geometrycznie jest e^(-x), a hiperbolicznie 1/(1+x). Poniższe rysunki pozwalają porównać obydwa zjawiska:
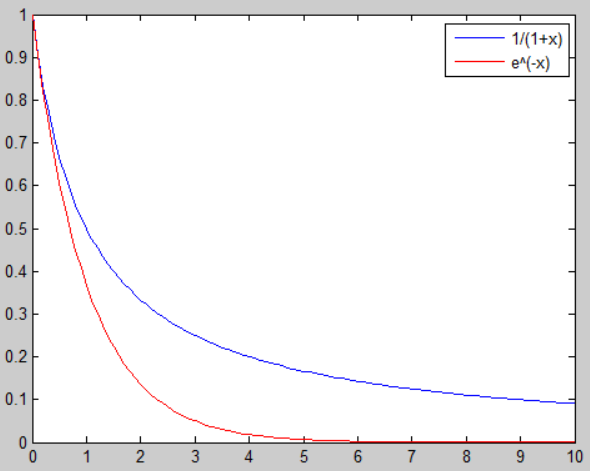
Tak więc w szeregach czasowych z długą pamięcią, ACF i PACF są nieprzydatne. ACF może błędnie sugerować niestacjonarność procesu (kolejne obserwacje korelują ze sobą, powodując nieprzypadkowe zmiany, co wywołuje ich oddalanie się od średniej), a PACF autokorelację pierwszych rzędów. Może się oczywiście zdarzyć odwrotnie - istnieć autokorelacja liniowa dalekiego rzędu, np. 7-go i jeśli nie wyłapiemy AR(7), to błędnie oszacujemy występowanie długiej pamięci. Co więcej, nawet jeśli wyłapiemy AR(7), ale nie zauważymy, że reszty modelu są (nadal) wzajemnie skorelowane, to też błędnie oszacujemy występowanie długiej pamięci. To właśnie dlatego, aby usunąć autokorelacje pomiędzy resztami (składnikami losowymi), stosuje się proces MA. Stąd podstawą jest model ARMA, ARIMA i dopiero potem ARFIMA.
Literatura:
[1] Pong S., Shackleton, M. B., Taylor, S. T., Distinguishing short and long memory volatility specifications, 2008;
[2] Jin H. J., Frechette, D. L., Fractional Integration in Agricultural Futures Price Volatilities, May 2004.
Brak komentarzy:
Prześlij komentarz