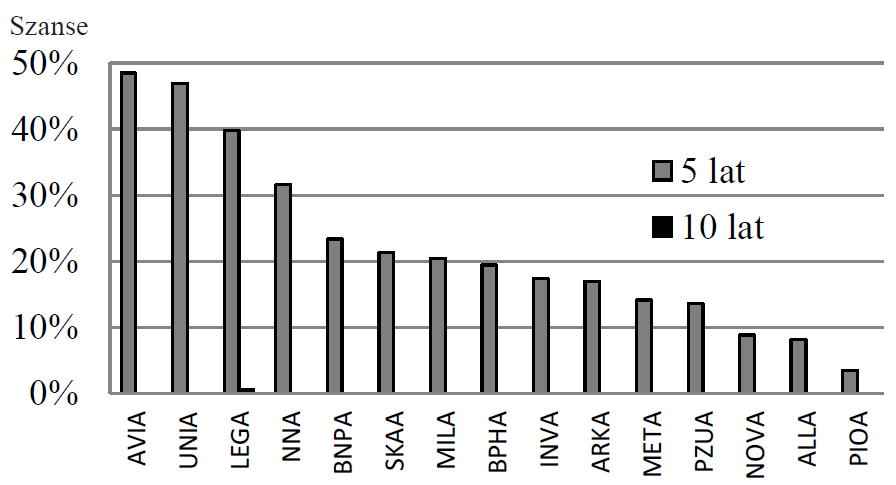
Porównując liniowy model prawdopodobieństwa (LMP) z regresją logistyczną (RL), doszliśmy do wniosku, że oba modele staną się tożsame, gdy spełnione będą dwa warunki: występuje tylko jedna zmienna niezależna X oraz zmienna ta jest zero-jedynkowa. Dzieje się tak dlatego, że wtedy oba modele mają tylko 2 punkty w X: 0 i 1, wobec czego naturalnie powstaje zawsze linia prosta (jako funkcja prawdopodobieństwa, P) która je łączy. Poniższy rysunek to pokazuje:
Rysunek nr 1
Już sytuacja, gdy wystąpi wiele zmiennych niezależnych typu 0-1, zmienia ten obraz. Jednak ciekawszy problem powstaje, gdy mowa o dowolnej zmiennej X, nie tylko 0-1. Bo przecież wyprowadzenie RL, które pokazałem
tutaj, opierało się w całości na zmiennych binarnych.
Po co RL uogólniać dla dowolnej zmiennej rzeczywistej X? W ekonomii rzadko spotyka się oczywisty podział na tak / nie. Np. moglibyśmy sprawdzić jaka jest szansa, że firma zbankrutuje, jeśli ponosi straty przez 3 lata z rzędu. Ale lepszym sposobem byłaby ocena prawdopodobieństwa bankructwa dla firmy, która ponosi straty dowolną liczbę lat z rzędu. Przypuszczalnie im większa liczba lat ze stratami, tym większa szansa na bankructwo. Innym kryterium mogłaby być wielkość strat: im większe straty, tym większa szansa na upadek firmy. Lub na odwrót: im większe zyski, tym mniejsze zagrożenie upadłością. To kryterium wykorzystam później w przykładzie.
Żeby zrozumieć, dlaczego można podstawić pod X dowolną zmienną, należy powrócić do
poprzedniego artykułu, w którym analizowałem przejście od funkcji Y = X do postaci Y = a + bX + e, gdzie a, b to stałe współczynniki, e to składnik losowy. Wtedy p = a + bX. Wiemy, że X równa się 0 lub 1 oraz Y równa się 0 lub 1. Powiedzmy jednak, że chcemy, aby X równało się 0 lub 5, a Y ciągle 0 lub 1. Mielibyśmy dwie możliwości osiągnięcia tego.
I) Zamieniamy współczynnik b na 1/5*b. Wtedy Y = a + 1/5*bX + e, oraz p = a + 1/5*bX
II) Zamieniamy e na e' = -4/5*bX + e. Wtedy Y = a + bX + e', oraz p = a + bX + E(e'). Zauważmy, że E(e') = E(-4/5*b*X + e) = -4/5*b*X + E(e) = -4/5*b*X, bo X uznajemy za stałą (jest zawsze znana, 0 lub 5), wartość oczekiwana e wynosi 0. Stąd p = a + bX + E(e') = a + bX - 4/5b*X = a + 1/5*b*X.
Dostaliśmy to samo w obu sposobach.
Teraz powiedzmy, że są dwie zmienne niezależne X1 i X2, pierwotnie typu 0-1. Ale teraz chcemy, by X1 = 0 lub 5, oraz X2 = 0 lub 10. Wtedy, aby zachować wszystko inne, Y = a + 1/5*b1*X1 + 1/10*b2*X2 + e, oraz p = a + 1/5*b1*X1 + 1/10*b2*X2.
Następnie łączymy obie zmienne w jedną nową X: p = a + b(1/5*b1/b*X1 + 1/10*b2/b*X2) = a + bX, gdzie X = 1/5*b1/b*X1 + 1/10*b2/b*X2. Powiedzmy, że b1 = 0,5, b2 = 0,7, b = 0,6. Wtedy powstają 3 możliwości rozłożenia X:
Jeśli X1 = 5, a X2 = 10, to X = 1/5*0,5/0,6*5 + 1/10*0,7/0,6*10 = 5/6 + 7/6 = 2.
Jeśli X1 = 5 i X2 = 0, to X = 5/6.
Jeśli X1 = 0, a X2 = 10, to X = 7/6.
Jest też czwarta możliwość, że X1 = 0 i X2 = 0. Najlepiej byłoby, gdyby ta sytuacja była przeznaczona dla Y = 0, a pozostałe dla Y = 1. Oznacza to, że dla p(Y = 1) X powinna mieć tylko 3 różne wartości: 2, 5/6 i 7/6. Wówczas odpowiednio obliczymy prawdopodobieństwo, że Y = 1:
p = a + 0,6*2 = a + 1,2;
p = a + 0,6*5/6 = a + 0,5;
p = a + 0,6*7/6 = a + 0,7.
Możemy z tych 3 wartości p określić przedział dla stałej a. Wiemy, że p < 1, więc na pewno a < -0,2. Ponadto p > 0, więc a > -0,5. W sumie więc a będzie się mieścić między -0,5 a -0,2. Np. a = -0,3. Wtedy:
dla X = 2, p = -0,3 + 1,2 = 0,9,
dla X = 5/6, p = -0,3 + 0,5 = 0,2,
dla X = 7/6, p = -0,3 + 0,7 = 0,4.
Zatem dostajemy dodatnią zależność p od X: dla małej wartości (0,83) p = 0,2, dla większej (1,17) p = 0,4, oraz dla dużej (2) p = 0,9. Sumując, widać, że
z początkowych dwóch zmiennych binarnych, doszliśmy do dowolnej zmiennej rzeczywistej X. Jeśli zwiększymy ilość zmiennych do X3, X4..., to liczba możliwych wariantów X będzie się zwiększać.
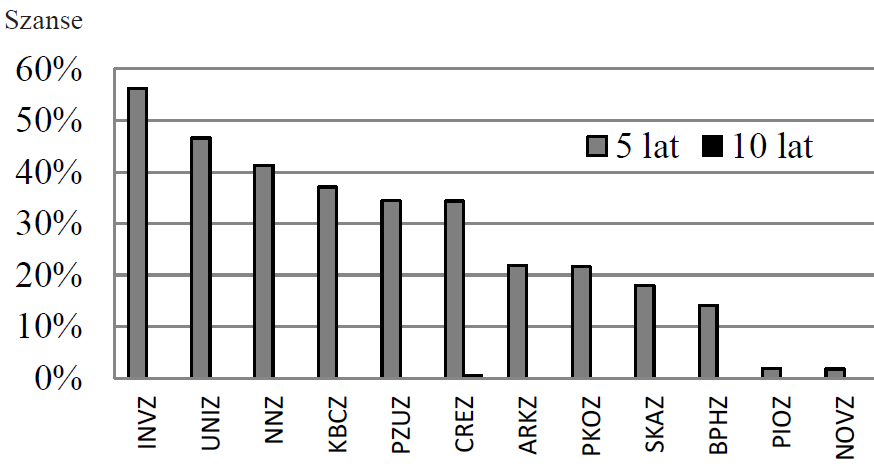
Zależność funkcyjna P od X będzie wyglądać od teraz tak jak na Rysunku nr 2:
Rysunek nr 2
X może znajdować się w przedziale (a, b). Wszystkie wartości powyżej i poniżej są niedozwolone.
Można zapytać, dlaczego od razu nie zapisałem Y = a + bX + e, gdzie Y to zmienna binarna, a X dowolna rzeczywista, reprezentująca jakąś cechę, np. dochód. Rzecz w tym, że wyprowadzenie LMP w poprzednim artykule zacząłem od tożsamości Y = X, gdzie Y była typu 0-1, a więc X też musiała taka być. Nawet przechodząc do słabszej korelacji Y = a + bX + e, musiałem zachować ten typ. Dopiero więcej zmiennych niezależnych pozwoliło mi na przekształcenie binarnego X w dowolnie rzeczywistą zmienną.
Ponieważ LMP jest funkcją liniową, to dla skrajnych wartości X, p będzie oczywiście zachowywać się mało sensownie. Mając naszą funkcję p = -0,3 + 0,6*X, już dla X = 2,2, dostaniemy p = 1,02 > 1. Albo dla X = 0,4, p = -0,06 < 0. Nie ma powodu, by dochód 2 był możliwy, a już 2,2 nie. Dlatego LMP nie nadaje się dla wielowartościowej zmiennej niezależnej lub dla wielu zmiennych zero-jedynkowych (które prowadzą do tego samego).
Stąd zamiast LMP zastosujemy RL. Dotychczas mogliśmy RL użyć tylko dla binarnego X. Ale dzięki zastosowaniu powyższego toku rozumowania, dostaniemy model już do bardzo szerokich zastosowań.
Tak więc, mamy regresję logistyczną dla 1 zmiennej niezależnej X typu 0-1:
(1)
Funkcja ta przyjmuje tylko dwie wartości. Dla X = 1:
(2)
Dla X = 0:
(3)
We wzorze (2) i (3) beta(0) znika dlatego, że siedzi w niej x2 = 0 (zob. wyprowadzenie regresji logistycznej
tutaj).
Fakt, że występują tylko dwa punkty oznacza, że dostajemy z powrotem Rysunek nr 1, a więc tak jak wcześniej powiedziałem dostajemy de facto LMP.
Dla dwóch zmiennych X1 i X2 typu 0-1 ogólna postać RL będzie następująca:
(4)
i dostaniemy już 4 różne wartości P ze względu na wystąpienie czterech różnych zdarzeń.
Dla X1 = 1 i X2 = 0:
Dla X1 = 0 i X2 = 1:
Dla X1 = 1 i X2 = 1:
Dla X1 = 0 i X2 = 0:
bo musi zajść:
Podobnie jak dla funkcji jednej zmiennej beta(0) = 0, bo siedzi w niej czwarte zdarzenie, gdy jednocześnie X1 = 0 i X2 = 0.
Czyli widać, że wraz z liczbą zmiennych niezależnych 0-1 wzrasta liczba wariantów P.
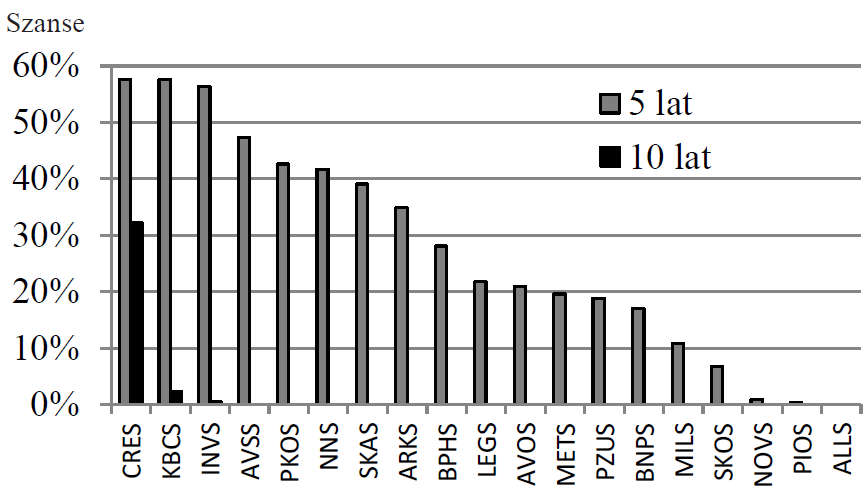
Stosując identyczne rozumowanie jak wcześniej dla LMP, zastępujemy teraz zmienne niezależne typu 0-1 jedną dowolną zmienną niezależną. W ten sposób powrócimy do wzoru nr (1), lecz X stanie się już zmienną o dowolnych wartościach rzeczywistych. Dzięki temu linia RL przybierze kształt dystrybuanty rozkładu prawdopodobieństwa, tak jak to pokazuje Rysunek nr 3:
Rysunek nr 3
Zmienna X może od teraz przyjmować dowolną wartość, bo funkcja nie spadnie nigdy poniżej 0 ani nie przekroczy 1.
W tym czasie sam Y ciągle przyjmuje 0 lub 1, tak że zależność od X
powinna się prezentować następująco:
Rysunek nr 4
Poziom a oraz b nie są jednoznaczne. Dla a możemy przyjąć, że będzie to wartość, od której zaczynają się straty, tak że firma będzie musiała zbankrutować. Natomiast b możemy uznać za taką wartość od której P zbliża się do 1. Wówczas porównujemy Rysunek nr 4 z Rysunkiem nr 3 oraz Rysunkiem nr 2. Należy zaznaczyć, że Rysunek nr 4 wskazuje jedynie na zależność planowaną, przewidywaną, dlatego w rzeczywistości niektóre punkty przecinające 0 będą przecinać 1, a te które przecinają 1 będą przecinać 0. Potem na przykładzie to zobaczymy.
RL można uogólnić na więcej zmiennych niezależnych. W sumie RL będzie mieć postać:
(5)
gdzie X(k) przyjmuje dowolną wartość rzeczywistą.
Na koniec teoretycznej części warto dodać, że pomiędzy LMP a RL ciągle istnieje pewna zależność. Zapiszmy (5) w prostszej formie:
(6)
Wzór (6) przekształćmy na dwa sposoby a i b:
a)
b)
Po odjęciu równania (b) od (a) i dalszych prostych przekształceniach otrzymamy
model logitowy:
(7)
Ten model jest najczęściej wykorzystywany do oszacowania parametrów RL,
zresztą prowadzi do niego metoda największej wiarygodności, za pomocą
której znajduje się właśnie parametry.
Model (7) dostarcza cennej informacji. Podstawmy P = 0,5. Dostaniemy ln1 = 0, czyli Z = 0, a to oznacza, że model niczego nie wyjaśnia, tzn. beta(0) = 0 oraz każde X(k) = 0 lub beta(k) = 0. Model praktycznie nie istnieje, więc nie istnieje także przewidywane Y. To prowadzi do wniosku, że przewidywane Y = 0.
A więc doszliśmy do wniosku, że gdy P = 0,5, to przewidywane Y = 0. Jakie to ma praktyczne znaczenie? Otóż prowadzi to do wniosku, że podejmując decyzję, np. o inwestowaniu w daną spółkę, powinniśmy kierować się tym, że spółka nie upadnie z prawdopodobieństwem powyżej 0,5.
Przykład. Część A)
Stworzyłem hipotetyczną listę 98 spółek o rocznych dochodach na akcję,
które nie zbankrutowały (oznaczone 1) lub zbankrutowały (0). Ogólnie mamy model ze zmienną zależną Y oznaczoną Czy_bez_upadlosci, która przyjmuje 0 (upadek) lub 1 (bez upadku). Zmienna niezależna X oznaczona jako Dochód_firmy przyjmuje wartości rzeczywiste. Na rysunku nr 4 pokazałem, jak przewidujemy zachowanie Y względem X. Ale wiadomo, że nie zawsze ta zależność będzie spełniona. Popatrzmy więc, jak w przykładzie to wygląda naprawdę:

Na podstawie tego wykresu moglibyśmy spróbować wyznaczyć poziomy a i b, korespondując z Rysunkiem nr 4. Poziom Y = 1 zaczyna się dla X bliskiego 0, stąd X = 0 uznamy na początek za wartość a. Jednocześnie oceniamy, że X = 48 to wartość, po której Y już nie przyjmuje w ogóle 0, zatem 48 może być uznane za wartość b. Jednak nie wszystko się zgadza z Rysunkiem nr 4. Wielu wartościom powyżej X = a przyporządkowane są Y = 0 a nie Y = 1, jak należałoby oczekiwać. Sugeruje to, że poziom a powinien zostać przesunięty. Zobaczymy później czy da się to zrobić.
Część B)
Na podstawie Przykładu nr 1 zbudujemy LMP.
Y = a +bX +e,
gdzie:
Y = Czy_bez_upadlosci
X = Dochód_firmy
e - składnik losowy.
Linia regresji będzie dana wzorem:
P = a +bX,
gdzie:
P - prawdopodobieństwo, że firma
nie upadnie
Stosujemy KMNK:
Wartości prognozy zapisałem jako nową zmienną Pr_Czy_bez_upadlosci_lin. Oto graficzne wyniki prognozy wedle LMP:
Zgodnie z oczekiwaniami im większe dochody, tym szansa, że firma nie zbankrutuje, rośnie. Niestety także dla wielu wartości P < 0 oraz P > 1, co dowodzi, że model jest nieprawidłowy. Gdy firma poniosła duże straty, poniżej -30 zł na akcję, P stało się ujemne. Analogicznie, dla dużych dochodów, powyżej 70 zł, P przekracza 1. Należy więc model skorygować, najlepiej stosując RL.
Część C)
Wykorzystujemy te same dane, aby poprawić prognozy za pomocą RL. Wchodzimy w Model logitowy w gretlu. Pamiętajmy, że mamy tu do czynienia z klasycznym, binarnym logitem, dlatego wchodzimy w Ograniczona zmienna zależna -> model logitowy -> binarny. (Pozostałe warianty przeznaczone są dla zmiennej zależnej nie-zerojedynkowej). Zaznaczamy Dochód_firmy jako regresor, Czy_bez_upadlosci jako zależną, zaznaczamy opcję Pokaż wartość p, i OK.
Otrzymujemy oceny parametrów i inne statystyki:
Model jest istotny statystycznie. Macierz błędów omówiłem w
poprzednim artykule; porównując liczbę błędów (sumarycznie 30) z prawidłowymi prognozami (68) oceniamy, że model jest dobry.
Wartości prognozy zapisałem jako nową zmienną Pr_Czy_bez_upadlosci_log. Graficzne wyniki prognozy wg RL przedstawiają się następująco:
Jest to oczywiście realizacja Rysunku nr 3. RL pięknie dostosowuje duże dochody do zerowego prawdopodobieństwa upadłości oraz duże straty do zagrożenia na poziomie prawie 100%.
Część D)
Powiedzmy, że obserwujemy nową firmę, która w ostatnim roku poniosła stratę 15 zł na akcję. Chcemy za pomocą RL ocenić szanse, że firma przetrwa. W gretlu Dane -> dodaj obserwację -> 1. Potem zaznaczamy Dochód_firmy, potem klikamy Dane -> Edycja wartości -> dopisujemy na koniec -15. Następnie wchodzimy w Prognozę mając ciągle otwarty model logitowy. Patrzymy na ostatnią wartość prognozy:
Czyli jest zaledwie 12% szans, że nowa firma nie upadnie, tzn. na 88% upadnie.
Co by się stało, gdyby ta firma zamiast straty 15 zł, miała 15 zł zysku? Zmieńmy dochód na +15. Teraz prawdopodobieństwo bankructwa wynosi 56%.
Czyli pomimo zysku, firma na ponad 50% i tak upadnie.
Część E)
Wszystko już wiemy, potrafimy modelować prawdopodobieństwo upadłości czy przetrwania, ale musimy teraz odpowiedzieć na pytanie czy inwestować w którąś firmę czy nie. Pierwszym kryterium, które moglibyśmy nazwać koniecznym, będzie wybór takich firm, dla których prawdopodobieństwo przetrwania będzie większe od 0,5. Z jednej strony jest to wybór intuicyjny, z drugiej wynika z samego modelu logitowego, o czym już wcześniej się rozpisałem.
W gretlu do poprzednich danych dopisujemy nową zmienną, np. Czy_bez_upadlosci_hat o formule Pr_Czy_bez_upadlosci_log > 0.5. Ta prosta formuła działa na zasadzie prawda-fałsz, a więc 1-0. Jeżeli zmienna Pr_Czy_bez_upadlosci_log > 0.5, to Czy_bez_upadlosci_hat = 1. W przeciwnym wypadku Czy_bez_upadlosci_hat = 0. To oznacza, że dostaniemy przewidywane Y z Rysunku nr 4 (dopisek hat oznacza z ang. daszek, czyli dostaniemy Y z daszkiem, tj. prognozowane Y właśnie). Tak więc dla zmiennej niezależnej X, zmienna zależna Czy_bez_upadlosci_hat, będzie się zachowywać tak:
Czyli dostajemy ten sam obraz co na Rysunku nr 4. Teraz widzimy, że poziom X = a nie wynosi 0, jak początkowo uznaliśmy, ale prawie 20. Czyli minimalnym kryterium, aby w firmę zainwestować, jest osiąganie dochodu 20. Porównując z poprzednim wykresem widać, że dochód = 20 koresponduje z P = 0,5, czyli rzeczywiście te poziomy powyżej 20 zł na akcję posiadają szansę na przetrwanie powyżej 50%.
Oczywiście 50% jest minimalnym poziomem, a więc możemy podwyższyć ten próg. Tym progiem może być taka wartość, dla której X = b, bo od tego poziomu żadna firma nie zbankrutowała. Ten poziom się nie zmieni i ciągle wynosi 48, tak jak wcześniej go wyznaczyliśmy w Części A. Teraz patrzymy, jakie p towarzyszy X = 48. To kryterium moglibyśmy nazwać wystarczającym. Tworzymy nową zmienną Czy_bez_upadlosci_min = Dochod_firmy=48. Formuła ta ponownie działa na zasadzie prawda-fałsz, w ten sposób, że przybierze 1 dla firmy osiągającej dochód 48, a dla pozostałych 0. Najszybciej znajdziemy P zaznaczając Czy_bez_upadlosci_min oraz Pr_Czy_bez_upadlosci_log, a następnie wyświetlamy wykres rozrzutu XY. Dostałem taki wykres:
W sumie wystarczy, aby firma na ok. 85% była wypłacalna, aby w nią zainwestować.