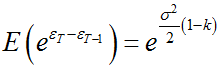1) gdy cena rośnie wykładniczo w czasie, tzn. prawdziwy jest model P(t) = e^(bt + składnik losowy), przy czym składnik losowy może pochodzić z dowolnego rozkładu;
2) gdy cena nie zależy od czasu, tzn. średnio znajduje się ciągle na tym samym poziomie. Np. WIG od końca 10.2006 do końca 10.2016 to praktycznie linia płaska:

Okazało się, że w tym drugim przypadku SE sprowadza się do niewarunkowej średniej arytmetycznej stopy zwrotu. Natomiast gdy istnieje wykładnicza zależność od czasu, to SE jest warunkową średnią równą e^b*D, gdzie D to korekta Duana liczona jako średnia arytmetyczna z wykładniczych składników losowych e^(składnik losowy). Zatem, jeżeli czas staje się warunkiem dla zmian kapitału, to średnia niewarunkowa przekształca się w średnią warunkową.
Jednak inwestor przyzwyczajony do pojęcia stopy zwrotu zaczyna się zastanawiać: w jaki sposób czas miałby w ogóle wpływać na stopę zwrotu? Przecież po to właśnie jest pojęcie stopy, czyli procentu, aby uniezależnić zmiany kapitału od kolejnych okresów. Ale gdy spojrzymy na to zagadnienie tak jak na różnicę pomiędzy średnią arytmetyczną a geometryczną, odpowiedź staje się jaśniejsza: gdy obliczamy średnią geometryczną, uwzględniamy fakt, że wartość kapitału zależy od okresu poprzedniego, bo jest jakby oprocentowany. Natomiast gdy wyznaczamy średnią arytmetyczną, każdą zmianę kapitału traktujemy całkowicie niezależnie od poprzednich okresów. To stąd przecież powstaje różnica pomiędzy "długookresową średnią stopą zwrotu" a "krótkookresową średnią stopą zwrotu", wskazując w pierwszym przypadku na czasową zależność zmian kapitału oraz w drugim przypadku na ich niezależność.
A stąd już tylko krok do zrozumienia różnicy pomiędzy warunkową a niewarunkową średnią: ta pierwsza zawiera część stochastyczną D oraz część systematyczną e^b. Część systematyczna jest niczym innym jak średnią geometryczną brutto w rozkładzie ciągłym. Oczywiście jest różnica między rozkładem ciągłym a dyskretnym, ale w modelu ciągłym zakładamy, że pomiędzy dwoma oddalonymi punktami możemy wstawić pewną średnią z tych punktów, ponieważ czas jest ciągły. Nie będzie to średnia arytmetyczna, ale właśnie geometryczna. Jeżeli mamy okres pomiędzy 10 a 11, np. 10,5 i chcemy wyznaczyć teoretycznie ten punkt, to zauważmy, że średnia geometryczna brutto z wartości pomiędzy okresem 10 a 11 równa się (e^10*e^11)^0,5 = e^(21*0,5) = e^10,5. Trzeba jednak zaznaczyć, że przejście od rozkładu dyskretnego do ciągłego w rzeczywistości wszystko zmienia, bo o ile w dyskretnym stopy brutto wewnątrz okresu się redukują, tak że wpływ na średnią ma jedynie pierwsza i ostatnia wartość, o tyle w ciągłym już tego zrobić nie mogą i jest to poniekąd przyczyna, dla której średnia geometryczna brutto w rozkładzie ciągłym staje się równa medianie, co odpowiada temu co napisałem kiedyś w Istota i znaczenie logarytmicznej stopy zwrotu.
Oczywiście trzeba pamiętać, że średnia warunkowa jest znacznie szerszym pojęciem niż tylko w kontekście czasu. Częściej średnia warunkowa traktowana jest w powiązaniu z inną zmienną losową. Np. w dwuwymiarowym rozkładzie normalnym, w którym zmienne losowe X i Y są ze sobą skorelowane, wartość oczekiwana Y pod warunkiem, że X = x jest dana wzorem [2]:

Jeżeli współczynnik korelacji ρ jest równy zero, warunkowa wartość oczekiwana Y sprowadza się do niewarunkowej wartości oczekiwanej m(Y). W przeciwnym razie Y zależy od zachowania X. Na przykład Y może być stopą zwrotu z akcji, a X stopą zwrotu z indeksu giełdowego. Gdyby obie pochodziły z rozkładu normalnego, to przedstawiona relacja byłaby zawsze prawdziwa i zawsze liniowa. Widać więc, jak istotną rolę pełni warunkowość, którą można rozpatrywać zarówno w kontekście przestrzeni jak i czasu.
Literatura:
[1] N. Duan, Smearing Estimate: A Nonparametric Retransformation Method, Sep. 1983,
[2] Z. Hellwig, Elementy rachunku prawdopodobieństwa i statystyki matematycznej, PWN W-wa 1998.